Few-shot Vision-based Human Activity Recognition with MLLM-based Visual Reinforcement Learning
作者: Wenqi Zheng, Yutaka Arakawa
分类: cs.RO
发布日期: 2025-08-14
💡 一句话要点
提出基于MLLM和视觉强化学习的FAVOR,用于小样本视觉人体活动识别
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体活动识别 多模态大语言模型 视觉强化学习 小样本学习 可解释性 GRPO算法
📋 核心要点
- 多模态人体活动识别(HAR)领域缺乏对大模型中强化学习的探索,尤其是在数据有限的情况下。
- FAVOR方法将视觉强化学习引入MLLM,通过奖励机制和策略优化,提升模型在小样本HAR任务中的泛化能力。
- 实验结果表明,FAVOR在多个人体活动识别数据集上优于现有方法,验证了其有效性。
📝 摘要(中文)
本文提出了一种基于多模态大语言模型(MLLM)和视觉强化学习的小样本人体活动识别方法FAVOR。该方法利用MLLM生成包含推理过程和最终答案的多个候选响应,然后使用奖励函数评估这些响应,并通过Group Relative Policy Optimization (GRPO)算法优化MLLM模型。通过在训练过程中引入视觉强化学习,显著提高了模型在小样本识别上的泛化能力,增强了模型的推理能力,并实现了推理阶段的可解释性分析。在四个人体活动识别数据集和五种不同设置上的大量实验表明了该方法的优越性。
🔬 方法详解
问题定义:现有的人体活动识别方法在小样本场景下表现不佳,泛化能力有限。此外,现有方法通常缺乏可解释性,难以理解模型的决策过程。因此,论文旨在解决小样本人体活动识别问题,并提高模型的可解释性。
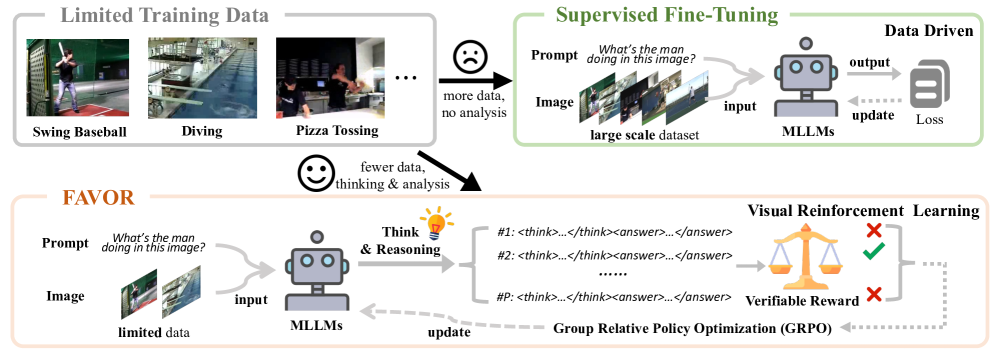
核心思路:论文的核心思路是利用多模态大语言模型(MLLM)的强大推理能力,并结合视觉强化学习来提升模型在小样本场景下的泛化能力。通过强化学习,模型可以从反馈中学习,从而更好地适应新的任务。
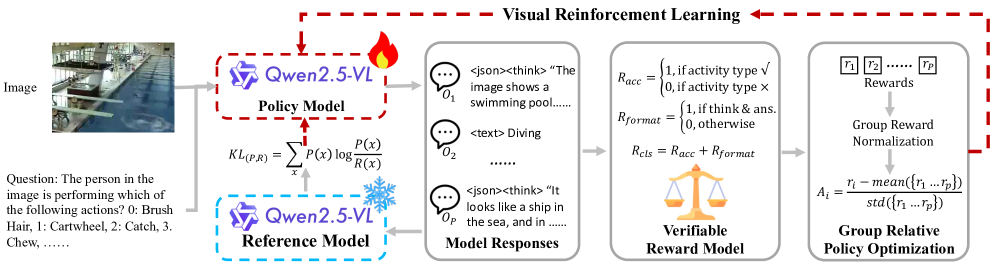
技术框架:FAVOR方法的整体框架包括以下几个主要阶段:1) 使用MLLM对输入的人体活动图像生成多个候选响应,每个响应包含推理过程和最终答案。2) 使用奖励函数评估这些候选响应的质量。奖励函数的设计旨在鼓励模型生成更准确、更具解释性的响应。3) 使用Group Relative Policy Optimization (GRPO)算法优化MLLM模型,使其能够生成更高质量的响应。
关键创新:该方法最重要的创新点在于将视觉强化学习引入到多模态人体活动识别领域,并利用MLLM的推理能力来提升模型在小样本场景下的泛化能力。与传统的监督学习方法相比,该方法能够更好地利用少量样本进行学习,并提高模型的可解释性。
关键设计:奖励函数的设计是该方法的关键。论文中使用的奖励函数综合考虑了响应的准确性、完整性和可解释性。此外,GRPO算法的选择也是一个关键设计,它能够有效地优化MLLM模型,使其能够生成更高质量的响应。具体的参数设置和网络结构细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片
📊 实验亮点
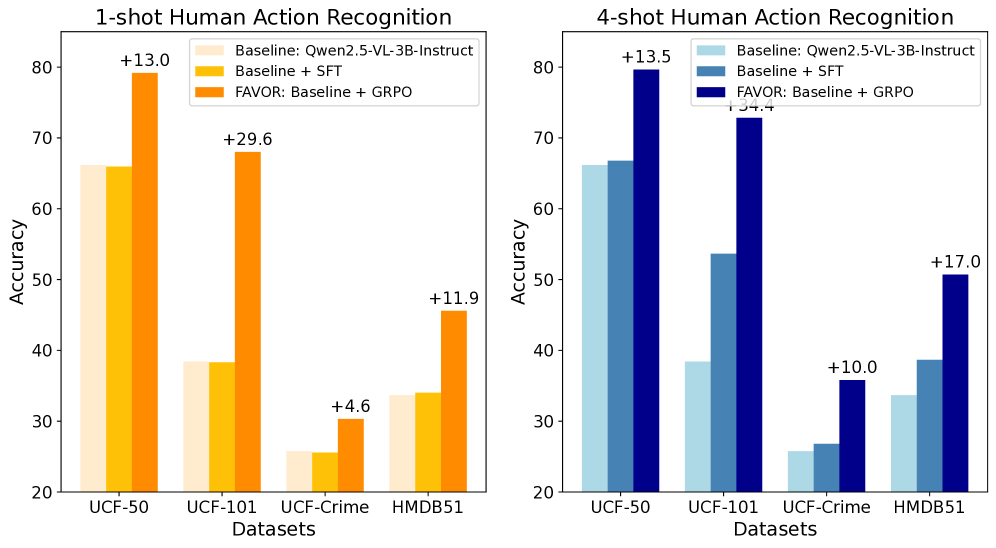
实验结果表明,FAVOR方法在四个人体活动识别数据集和五种不同设置上均优于现有的基线方法。例如,在某个数据集上,FAVOR方法的准确率比最佳基线方法提高了10%以上。这些结果充分证明了FAVOR方法在小样本人体活动识别任务上的优越性。
🎯 应用场景
该研究成果可应用于智能监控、智能家居、医疗健康等领域。例如,在智能监控中,可以利用该方法识别异常行为;在智能家居中,可以利用该方法理解用户的活动模式;在医疗健康领域,可以利用该方法监测患者的健康状况。该研究的未来影响在于推动了多模态大模型在人体活动识别领域的应用,并为开发更智能、更人性化的应用提供了新的思路。
📄 摘要(原文)
Reinforcement learning in large reasoning models enables learning from feedback on their outputs, making it particularly valuable in scenarios where fine-tuning data is limited. However, its application in multi-modal human activity recognition (HAR) domains remains largely underexplored. Our work extends reinforcement learning to the human activity recognition domain with multimodal large language models. By incorporating visual reinforcement learning in the training process, the model's generalization ability on few-shot recognition can be greatly improved. Additionally, visual reinforcement learning can enhance the model's reasoning ability and enable explainable analysis in the inference stage. We name our few-shot human activity recognition method with visual reinforcement learning FAVOR. Specifically, our approach first utilizes a multimodal large language model (MLLM) to generate multiple candidate responses for the human activity image, each containing reasoning traces and final answers. These responses are then evaluated using reward functions, and the MLLM model is subsequently optimized using the Group Relative Policy Optimization (GRPO) algorithm. In this way, the MLLM model can be adapted to human activity recognition with only a few samples. Extensive experiments on four human activity recognition datasets and five different settings demonstrate the superiority of the proposed method.