ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
作者: Wenxuan Song, Ziyang Zhou, Han Zhao, Jiayi Chen, Pengxiang Ding, Haodong Yan, Yuxin Huang, Feilong Tang, Donglin Wang, Haoang Li
分类: cs.RO, cs.CV
发布日期: 2025-08-14
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
ReconVLA:提出重建式视觉-语言-动作模型,提升机器人感知能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 注意力机制 扩散模型 图像重建 隐式引导 多模态学习
📋 核心要点
- 现有VLA模型在视觉注意力分配上存在不足,无法有效聚焦于目标区域,导致操作精度受限。
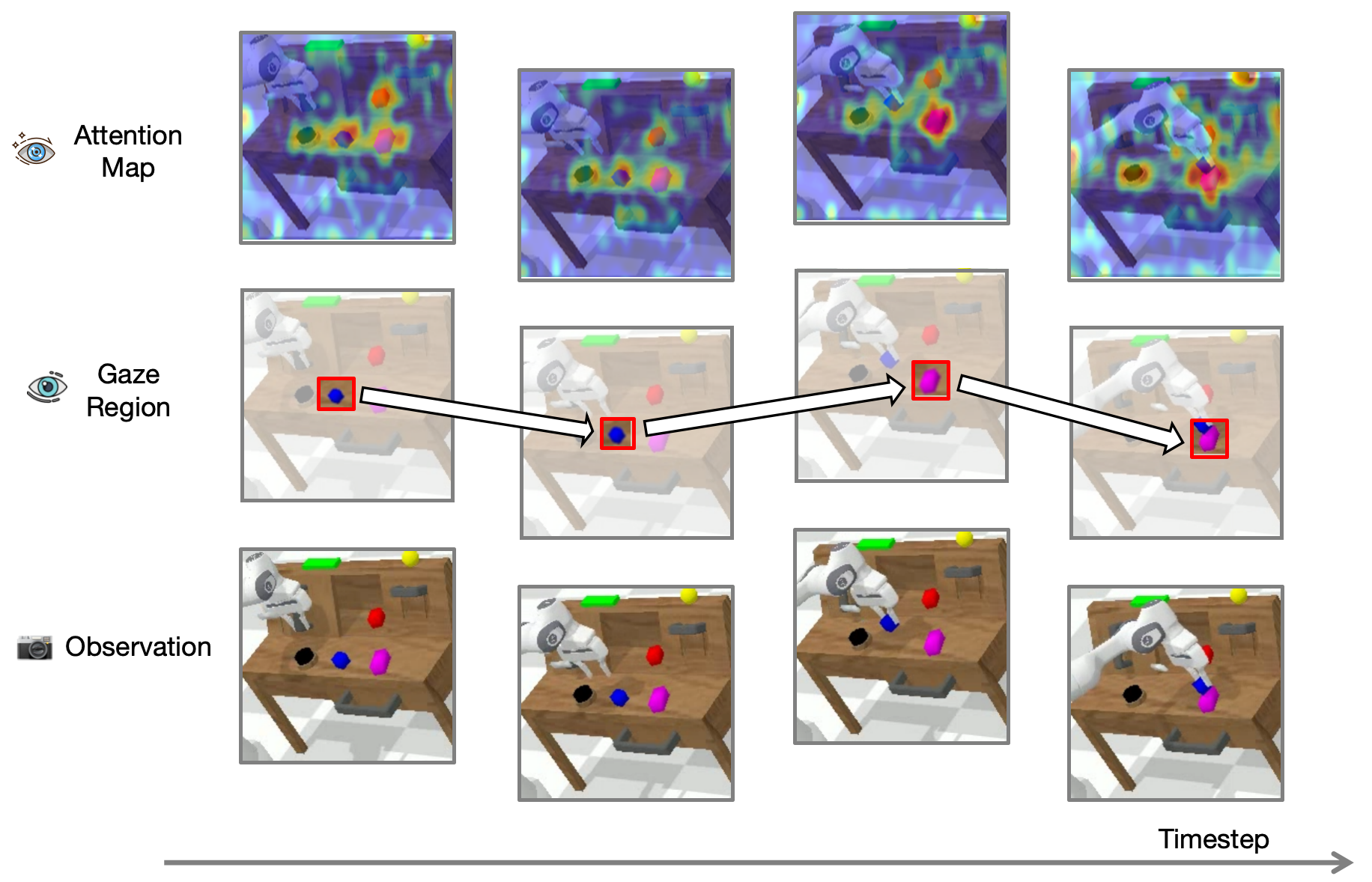
- ReconVLA通过重建图像注视区域,隐式引导模型学习细粒度视觉表示,从而提升注意力定位的准确性。
- 实验结果表明,ReconVLA在模拟和真实环境中均表现出优越的性能,实现了更精确的操作和更好的泛化能力。
📝 摘要(中文)
视觉-语言-动作(VLA)模型的最新进展使机器人能够整合多模态理解和动作执行。然而,经验分析表明,当前的VLA模型难以将视觉注意力集中在目标区域,而是分散注意力。为了引导视觉注意力正确地定位目标,我们提出了ReconVLA,一种具有隐式定位范式的重建式VLA模型。该模型利用扩散Transformer,以视觉输出为条件,重建图像的注视区域,该区域对应于被操纵的目标对象。这个过程促使VLA模型学习细粒度的表示,并准确地分配视觉注意力,从而有效地利用特定任务的视觉信息并进行精确的操作。此外,我们从开源机器人数据集中整理了一个包含超过10万条轨迹和200万个数据样本的大规模预训练数据集,进一步提高了模型在视觉重建中的泛化能力。在模拟和真实环境中的大量实验证明了我们的隐式定位方法的优越性,展示了其精确操作和泛化能力。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,无法准确地将视觉注意力集中在目标物体上,导致模型难以提取有效的视觉特征,进而影响操作的精度和泛化能力。现有方法通常采用显式的注意力机制,但效果有限,仍然存在注意力分散的问题。
核心思路:ReconVLA的核心思路是通过引入一个重建任务,迫使模型学习更细粒度的视觉表示,从而隐式地引导视觉注意力的分配。具体来说,模型以自身的视觉输出为条件,重建图像中与目标物体相关的注视区域。这种重建过程促使模型关注关键区域,并学习更具判别性的特征。
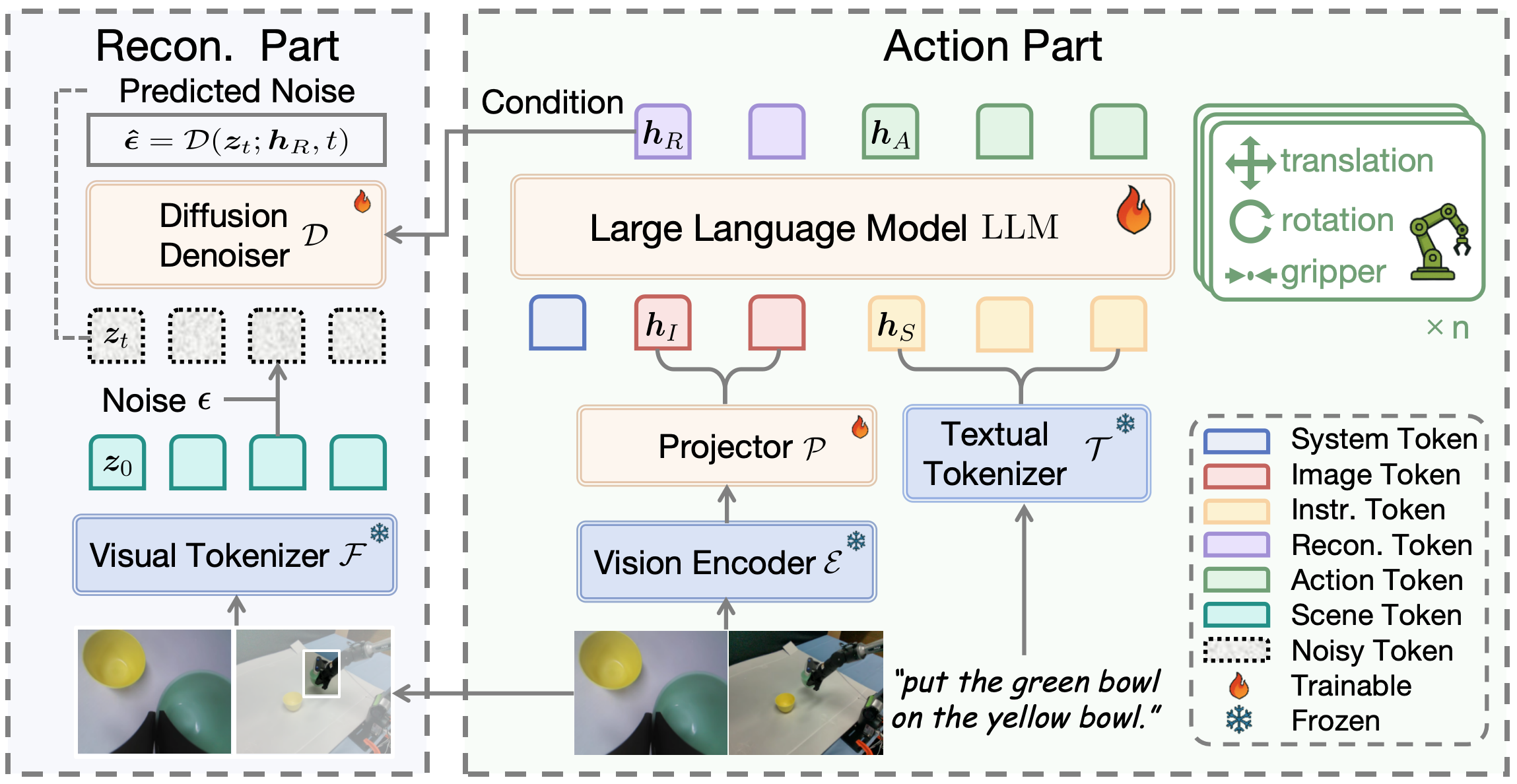
技术框架:ReconVLA的整体框架包括一个VLA模型和一个扩散Transformer。VLA模型负责提取图像和语言指令的特征,并生成动作序列。扩散Transformer以VLA模型的视觉输出为条件,重建图像的注视区域。整个训练过程采用端到端的方式,VLA模型和扩散Transformer共同优化。
关键创新:ReconVLA的关键创新在于其隐式的注意力引导范式。与显式的注意力机制不同,ReconVLA通过重建任务来隐式地引导模型关注目标区域,从而避免了注意力分散的问题。此外,利用扩散模型进行图像重建,能够生成更逼真的重建结果,进一步提升模型的性能。
关键设计:ReconVLA的关键设计包括:1) 使用扩散Transformer进行图像重建,扩散Transformer的具体结构未知;2) 构建大规模预训练数据集,包含超过10万条轨迹和200万个数据样本,用于提升模型的泛化能力;3) 损失函数包含VLA模型的动作预测损失和扩散Transformer的重建损失,具体形式未知。
🖼️ 关键图片

📊 实验亮点
ReconVLA在模拟和真实环境中的实验结果表明,该模型能够显著提升机器人的操作精度和泛化能力。具体性能数据未知,但论文强调了ReconVLA在精确操作和泛化能力方面的优越性,证明了隐式注意力引导范式的有效性。大规模预训练数据集的构建也为模型的性能提升做出了重要贡献。
🎯 应用场景
ReconVLA模型可应用于各种机器人操作任务,例如物体抓取、装配、导航等。该模型能够提升机器人在复杂环境中的感知能力和操作精度,具有广泛的应用前景。未来,该技术有望应用于智能制造、医疗机器人、家庭服务机器人等领域,实现更智能、更高效的自动化操作。
📄 摘要(原文)
Recent advances in Vision-Language-Action (VLA) models have enabled robotic agents to integrate multimodal understanding with action execution. However, our empirical analysis reveals that current VLAs struggle to allocate visual attention to target regions. Instead, visual attention is always dispersed. To guide the visual attention grounding on the correct target, we propose ReconVLA, a reconstructive VLA model with an implicit grounding paradigm. Conditioned on the model's visual outputs, a diffusion transformer aims to reconstruct the gaze region of the image, which corresponds to the target manipulated objects. This process prompts the VLA model to learn fine-grained representations and accurately allocate visual attention, thus effectively leveraging task-specific visual information and conducting precise manipulation. Moreover, we curate a large-scale pretraining dataset comprising over 100k trajectories and 2 million data samples from open-source robotic datasets, further boosting the model's generalization in visual reconstruction. Extensive experiments in simulation and the real world demonstrate the superiority of our implicit grounding method, showcasing its capabilities of precise manipulation and generalization. Our project page is https://zionchow.github.io/ReconVLA/.