Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
作者: Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Yue Hu, Jingbin Cai, Si Liu, Jianlan Luo, Liliang Chen, Shuicheng Yan, Maoqing Yao, Guanghui Ren
分类: cs.RO, cs.CV
发布日期: 2025-08-07 (更新: 2025-11-04)
备注: https://genie-envisioner.github.io/
💡 一句话要点
Genie Envisioner:用于机器人操作的统一世界基础平台
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 视频生成模型 扩散模型 具身智能 策略学习 神经模拟 指令条件控制
📋 核心要点
- 现有机器人操作方法在策略学习、评估和仿真方面存在割裂,难以实现通用具身智能。
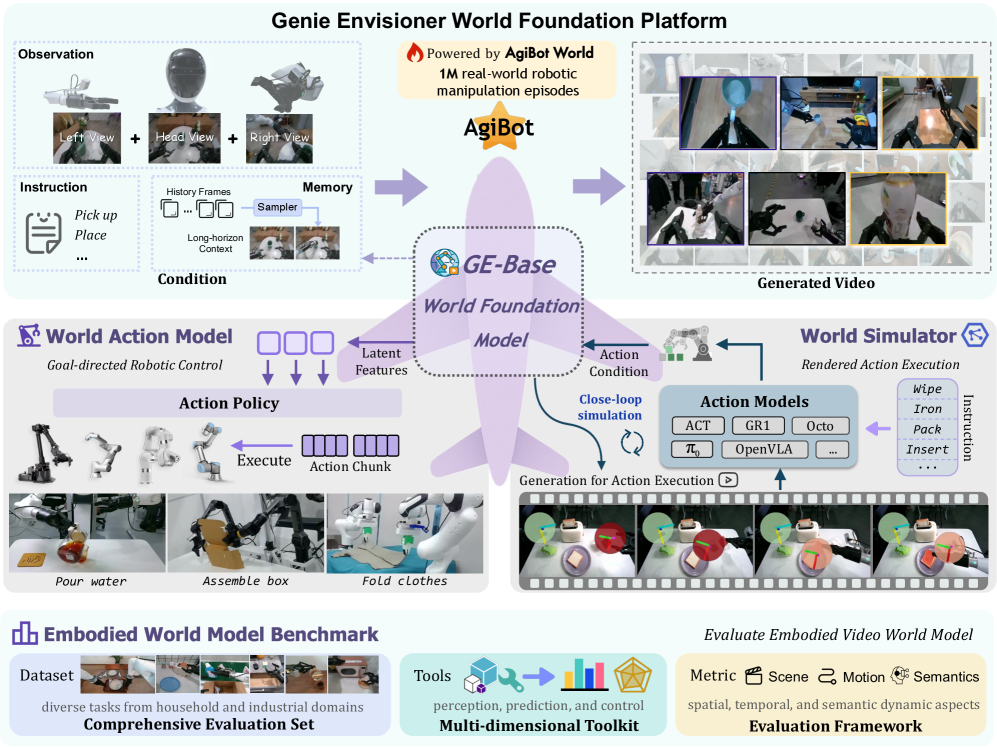
- Genie Envisioner (GE) 提出了一种统一的视频生成框架,集成了策略学习、评估和仿真。
- GE 平台包含大规模视频扩散模型、流匹配解码器和神经模拟器,并提供标准化评测基准。
📝 摘要(中文)
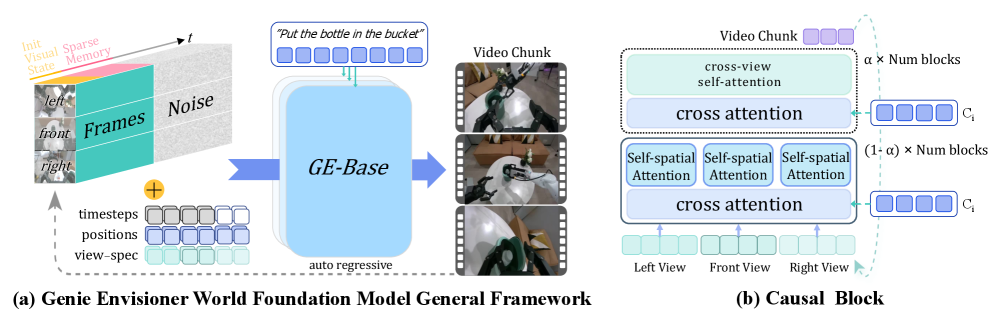
我们介绍了Genie Envisioner (GE),一个统一的世界基础平台,用于机器人操作,它在一个视频生成框架内集成了策略学习、评估和仿真。GE-Base是一个大规模的、指令条件视频扩散模型,它在结构化的潜在空间中捕获真实世界机器人交互的空间、时间和语义动态。在此基础上,GE-Act通过轻量级的、流匹配解码器将潜在表示映射到可执行的动作轨迹,从而在最小监督下实现跨不同形态的精确和可泛化的策略推理。为了支持可扩展的评估和训练,GE-Sim作为一个动作条件神经模拟器,为闭环策略开发产生高保真度的rollout。该平台还配备了EWMBench,一个标准化的基准测试套件,用于测量视觉保真度、物理一致性和指令-动作对齐。总之,这些组件将Genie Envisioner确立为一个可扩展且实用的基础,用于指令驱动的、通用具身智能。所有代码、模型和基准测试都将公开发布。
🔬 方法详解
问题定义:现有机器人操作方法通常将策略学习、评估和仿真视为独立的任务,导致训练和部署之间存在差距,难以实现通用性和可扩展性。此外,缺乏统一的评估标准也阻碍了不同方法之间的比较和进步。
核心思路:Genie Envisioner 的核心思路是构建一个统一的、基于视频生成的框架,将策略学习、评估和仿真整合在一起。通过学习真实世界机器人交互的视频数据,模型能够理解环境的动态特性,并生成与指令相符的动作序列。这种统一的表示方式使得策略可以在不同的机器人形态和任务之间进行泛化。
技术框架:Genie Envisioner 包含三个主要模块:GE-Base、GE-Act 和 GE-Sim。GE-Base 是一个大规模的指令条件视频扩散模型,用于学习真实世界机器人交互的潜在表示。GE-Act 是一个轻量级的流匹配解码器,用于将潜在表示映射到可执行的动作轨迹。GE-Sim 是一个动作条件神经模拟器,用于生成高保真度的 rollout,以支持闭环策略开发。此外,该平台还配备了 EWMBench,一个标准化的基准测试套件,用于评估视觉保真度、物理一致性和指令-动作对齐。
关键创新:Genie Envisioner 的关键创新在于其统一的视频生成框架,它将策略学习、评估和仿真整合在一起。这种统一的表示方式使得策略可以在不同的机器人形态和任务之间进行泛化。此外,该平台还提供了一个标准化的基准测试套件,用于评估不同方法的性能。
关键设计:GE-Base 使用扩散模型来学习视频数据的潜在表示,并使用指令作为条件来控制生成过程。GE-Act 使用流匹配解码器来将潜在表示映射到动作轨迹,这种方法可以有效地学习复杂的动作序列。GE-Sim 使用神经模拟器来生成高保真度的 rollout,这种方法可以有效地模拟真实世界的物理环境。
🖼️ 关键图片

📊 实验亮点
论文提出了 EWMBench 基准测试套件,用于评估视觉保真度、物理一致性和指令-动作对齐。实验结果表明,Genie Envisioner 在多个机器人操作任务上取得了显著的性能提升,证明了其有效性和泛化能力。具体性能数据和对比基线将在后续公开发布的代码和模型中提供。
🎯 应用场景
Genie Envisioner 有潜力应用于各种机器人操作任务,例如家庭服务机器人、工业自动化和医疗机器人。该平台可以帮助机器人更好地理解人类指令,并在复杂环境中执行任务。此外,该平台还可以用于开发新的机器人控制算法和评估现有算法的性能,从而加速机器人技术的发展。
📄 摘要(原文)
We introduce Genie Envisioner (GE), a unified world foundation platform for robotic manipulation that integrates policy learning, evaluation, and simulation within a single video-generative framework. At its core, GE-Base is a large-scale, instruction-conditioned video diffusion model that captures the spatial, temporal, and semantic dynamics of real-world robotic interactions in a structured latent space. Built upon this foundation, GE-Act maps latent representations to executable action trajectories through a lightweight, flow-matching decoder, enabling precise and generalizable policy inference across diverse embodiments with minimal supervision. To support scalable evaluation and training, GE-Sim serves as an action-conditioned neural simulator, producing high-fidelity rollouts for closed-loop policy development. The platform is further equipped with EWMBench, a standardized benchmark suite measuring visual fidelity, physical consistency, and instruction-action alignment. Together, these components establish Genie Envisioner as a scalable and practical foundation for instruction-driven, general-purpose embodied intelligence. All code, models, and benchmarks will be released publicly.