DistillDrive: End-to-End Multi-Mode Autonomous Driving Distillation by Isomorphic Hetero-Source Planning Model
作者: Rui Yu, Xianghang Zhang, Runkai Zhao, Huaicheng Yan, Meng Wang
分类: cs.RO, cs.CV
发布日期: 2025-08-07
🔗 代码/项目: GITHUB
💡 一句话要点
DistillDrive:基于同构异源规划模型的端到端多模态自动驾驶知识蒸馏
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 知识蒸馏 端到端学习 规划模型 强化学习 多模态融合 行为决策
📋 核心要点
- 现有端到端自动驾驶方法过度关注自车状态,缺乏面向规划的理解,限制了决策的鲁棒性。
- DistillDrive利用规划模型的规划实例作为多目标学习目标,并通过强化学习和生成模型增强学习效果。
- 实验表明,DistillDrive在nuScenes和NAVSIM数据集上显著降低了碰撞率并提升了闭环性能。
📝 摘要(中文)
本文提出DistillDrive,一个基于知识蒸馏的端到端自动驾驶模型,它利用多样化的实例模仿来增强多模态运动特征学习。具体来说,我们采用基于结构化场景表示的规划模型作为教师模型,利用其多样化的规划实例作为端到端模型的多目标学习目标。此外,我们结合强化学习来增强状态到决策映射的优化,同时利用生成模型来构建面向规划的实例,从而促进潜在空间内的复杂交互。我们在nuScenes和NAVSIM数据集上验证了我们的模型,与基线模型相比,碰撞率降低了50%,闭环性能提高了3个点。
🔬 方法详解
问题定义:现有端到端自动驾驶方法主要关注自车状态,缺乏对环境的规划理解,导致决策鲁棒性不足,容易发生碰撞等问题。论文旨在解决端到端自动驾驶中缺乏规划能力的问题,提升决策的安全性与可靠性。
核心思路:论文的核心思路是利用知识蒸馏,将规划模型的知识迁移到端到端模型中。具体来说,将规划模型产生的多样化规划实例作为端到端模型的学习目标,从而使端到端模型能够学习到更丰富的环境信息和更合理的驾驶策略。
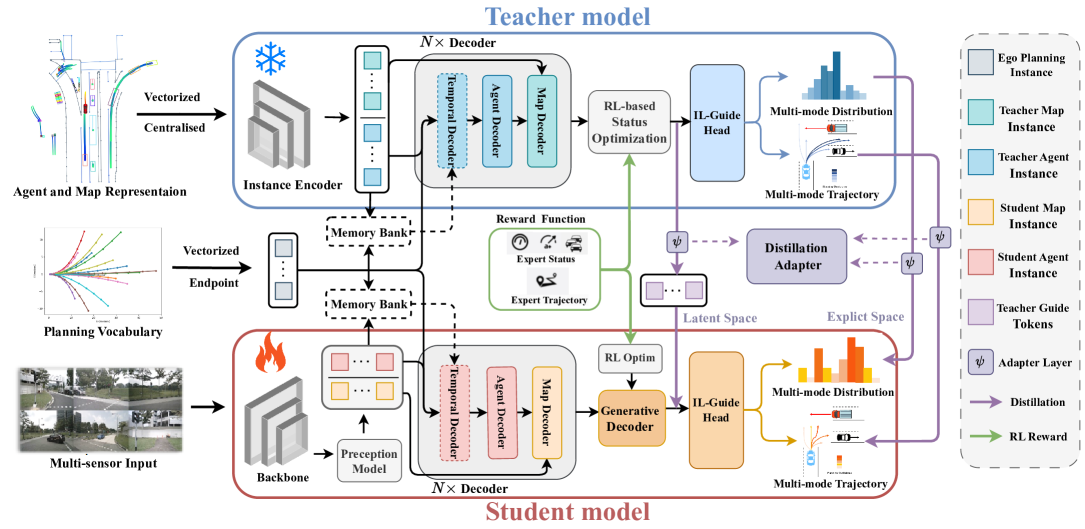
技术框架:DistillDrive的整体框架包含一个教师模型(规划模型)和一个学生模型(端到端模型)。教师模型基于结构化场景表示进行规划,生成多样化的规划实例。学生模型通过模仿教师模型的规划实例进行学习,同时结合强化学习来优化状态到决策的映射。此外,论文还利用生成模型来构建面向规划的实例,增强潜在空间内的交互。
关键创新:DistillDrive的关键创新在于利用规划模型的规划实例作为端到端模型的学习目标,从而将规划知识有效地迁移到端到端模型中。此外,结合强化学习和生成模型进一步提升了学习效果,使得端到端模型能够学习到更鲁棒的驾驶策略。与现有方法相比,DistillDrive更加注重规划能力,从而提升了决策的安全性与可靠性。
关键设计:论文中,教师模型采用基于结构化场景表示的规划模型,能够有效地提取环境信息并进行规划。学生模型采用端到端网络结构,能够直接从传感器数据映射到驾驶决策。损失函数包括模仿学习损失和强化学习损失,用于指导学生模型学习教师模型的规划策略和优化自身决策。生成模型用于生成面向规划的实例,增强潜在空间内的交互,提升模型的泛化能力。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
DistillDrive在nuScenes和NAVSIM数据集上进行了验证,实验结果表明,与基线模型相比,DistillDrive的碰撞率降低了50%,闭环性能提高了3个点。这些结果表明,DistillDrive能够有效地提升自动驾驶系统的安全性与可靠性。
🎯 应用场景
DistillDrive具有广泛的应用前景,可应用于各种自动驾驶场景,例如城市道路、高速公路和越野环境。该研究成果有助于提升自动驾驶系统的安全性、可靠性和鲁棒性,加速自动驾驶技术的商业化落地,并为未来的智能交通系统发展提供技术支撑。
📄 摘要(原文)
End-to-end autonomous driving has been recently seen rapid development, exerting a profound influence on both industry and academia. However, the existing work places excessive focus on ego-vehicle status as their sole learning objectives and lacks of planning-oriented understanding, which limits the robustness of the overall decision-making prcocess. In this work, we introduce DistillDrive, an end-to-end knowledge distillation-based autonomous driving model that leverages diversified instance imitation to enhance multi-mode motion feature learning. Specifically, we employ a planning model based on structured scene representations as the teacher model, leveraging its diversified planning instances as multi-objective learning targets for the end-to-end model. Moreover, we incorporate reinforcement learning to enhance the optimization of state-to-decision mappings, while utilizing generative modeling to construct planning-oriented instances, fostering intricate interactions within the latent space. We validate our model on the nuScenes and NAVSIM datasets, achieving a 50\% reduction in collision rate and a 3-point improvement in closed-loop performance compared to the baseline model. Code and model are publicly available at https://github.com/YuruiAI/DistillDrive