Learning to See and Act: Task-Aware Virtual View Exploration for Robotic Manipulation
作者: Yongjie Bai, Zhouxia Wang, Yang Liu, Kaijun Luo, Yifan Wen, Mingtong Dai, Weixing Chen, Ziliang Chen, Lingbo Liu, Guanbin Li, Liang Lin
分类: cs.RO, cs.CV
发布日期: 2025-08-07 (更新: 2025-11-24)
备注: 24 pages, 15 figures, project page: https://hcplab-sysu.github.io/TAVP
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出任务感知虚拟视角探索框架TVVE,提升机器人操作任务中的3D感知和泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 虚拟视角探索 任务感知学习 视觉表征学习 多任务学习
📋 核心要点
- 现有VLA模型依赖静态视角和共享视觉编码器,导致3D感知不足和任务间干扰,限制了鲁棒性和泛化性。
- TVVE框架通过虚拟视角探索获取信息丰富的视角,并利用任务感知的混合专家模型解耦不同任务的视觉特征。
- 实验表明,TVVE在RLBench和RLBench-OG基准测试中显著优于现有方法,并在真实机器人实验中表现出强大的泛化能力。
📝 摘要(中文)
本文提出了一种任务感知的虚拟视角探索(TVVE)框架,旨在克服多任务机器人操作中视觉-语言-动作(VLA)模型依赖静态视角和共享视觉编码器所带来的3D感知局限和任务干扰问题,从而提升模型的鲁棒性和泛化能力。TVVE采用高效的探索策略,并通过新颖的伪环境加速视角获取。此外,引入任务感知的混合专家(TaskMoE)视觉编码器来解耦不同任务的特征,提高表征的保真度和任务泛化能力。TVVE通过任务感知的方式观察世界,生成更完整和具有区分性的视觉表征,显著增强了各种操作任务中的动作预测能力。为了进一步验证TVVE在分布外(OOD)设置下的鲁棒性和泛化能力,构建了具有挑战性的基准RLBench-OG,涵盖各种视觉扰动和相机姿态变化。在RLBench和RLBench-OG上的大量实验表明,TVVE优于最先进的方法。在真实机器人实验中,TVVE表现出卓越的性能,并在包括视觉干扰和未见指令在内的多种OOD设置中表现出强大的泛化能力。
🔬 方法详解
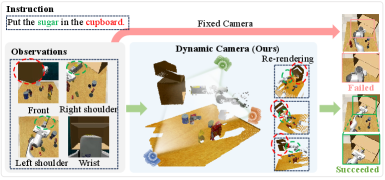
问题定义:现有基于视觉-语言-动作的机器人操作模型,通常依赖于固定的相机视角和共享的视觉编码器。这种方式限制了模型对3D场景的感知能力,并且不同任务之间容易产生特征混淆,导致模型在复杂环境和新任务上的泛化能力较差。
核心思路:论文的核心思路是引入任务感知的虚拟视角探索机制,让机器人能够主动选择更有利于完成特定任务的视角,从而获得更全面、更具区分性的视觉信息。同时,使用任务感知的混合专家模型来解耦不同任务的视觉特征,避免任务间的相互干扰。
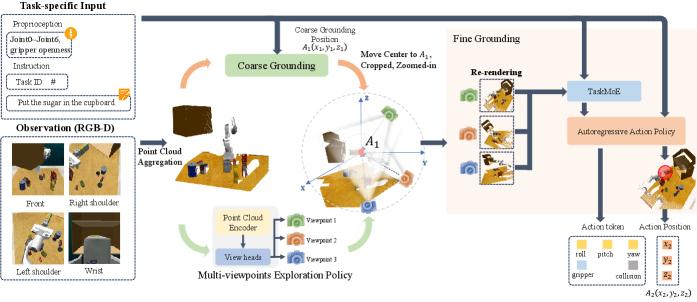
技术框架:TVVE框架主要包含三个核心模块:1) 虚拟视角探索策略:利用伪环境加速探索过程,学习高效的视角选择策略,获取信息量大的视角。2) 任务感知的混合专家(TaskMoE)视觉编码器:针对不同任务学习独立的视觉特征表示,并通过混合专家机制进行融合,提高表征的保真度和任务泛化能力。3) 动作预测模块:基于学习到的视觉表征和任务指令,预测机器人的动作序列。
关键创新:TVVE的关键创新在于将虚拟视角探索与任务感知的表征学习相结合。不同于以往依赖固定视角的做法,TVVE能够根据任务需求动态调整视角,从而获得更有效的视觉信息。TaskMoE视觉编码器则能够有效解耦不同任务的特征,避免任务间的干扰,提升模型的泛化能力。
关键设计:伪环境的设计是加速视角探索的关键。TaskMoE编码器中,每个专家负责学习特定任务的视觉特征,通过门控网络决定每个专家的贡献权重。损失函数包括动作预测损失、视角探索奖励以及TaskMoE的正则化项,用于鼓励视角探索的多样性和TaskMoE的特征解耦。
🖼️ 关键图片

📊 实验亮点
TVVE在RLBench和RLBench-OG基准测试中取得了显著的性能提升,超越了现有的state-of-the-art方法。特别是在RLBench-OG上,TVVE在各种视觉扰动和相机姿态变化下表现出强大的鲁棒性和泛化能力。真实机器人实验也验证了TVVE在实际场景中的有效性,即使在未见过的指令和视觉干扰下,也能成功完成操作任务。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如智能制造、家庭服务、医疗辅助等。通过提升机器人的3D感知和泛化能力,使其能够更好地适应复杂多变的环境,完成更加精细和复杂的任务。未来,该技术有望推动机器人智能化水平的提升,使其在更多领域发挥重要作用。
📄 摘要(原文)
Recent vision-language-action (VLA) models for multi-task robotic manipulation commonly rely on static viewpoints and shared visual encoders, which limit 3D perception and cause task interference, hindering robustness and generalization. In this work, we propose Task-aware Virtual View Exploration (TVVE), a framework designed to overcome these challenges by integrating virtual view exploration with task-specific representation learning. TVVE employs an efficient exploration policy, accelerated by a novel pseudo-environment, to acquire informative views. Furthermore, we introduce a Task-aware Mixture-of-Experts (TaskMoE) visual encoder to disentangle features across different tasks, boosting both representation fidelity and task generalization. By learning to see the world in a task-aware way, TVVE generates more complete and discriminative visual representations, demonstrating significantly enhanced action prediction across a wide array of manipulation challenges. To further validate the robustness and generalization capability of TVVE under out-of-distribution (OOD) settings, we construct a challenging benchmark, RLBench-OG, covering various visual perturbations and camera pose variations. Extensive experiments on RLBench and RLBench-OG show that our TVVE achieves superior performance over state-of-the-art approaches. In real-robot experiments, TVVE demonstrates exceptional performance and generalizes robustly in multiple OOD settings, including visual disturbances and unseen instructions. Visual results and code are provided at: https://hcplab-sysu.github.io/TAVP.