Scalable Multi-Task Reinforcement Learning for Generalizable Spatial Intelligence in Visuomotor Agents
作者: Shaofei Cai, Zhancun Mu, Haiwen Xia, Bowei Zhang, Anji Liu, Yitao Liang
分类: cs.RO, cs.AI
发布日期: 2025-07-31
💡 一句话要点
提出基于Minecraft环境的可扩展多任务强化学习,提升具身智能体的泛化空间推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 具身智能 强化学习 多任务学习 空间推理 零样本泛化
📋 核心要点
- 现有强化学习模型泛化性差,容易过拟合特定任务和环境,限制了其在具身智能体中的应用。
- 论文提出在Minecraft中进行大规模多任务强化学习,通过自动任务生成和跨视角目标规范,提升智能体的空间推理能力。
- 实验表明,该方法显著提高了智能体的交互成功率,并实现了在未见环境中的零样本泛化,包括真实世界。
📝 摘要(中文)
强化学习(RL)在语言建模领域取得了显著成功,但其优势尚未完全转化为具身智能体。RL模型的主要挑战在于容易过度拟合特定任务或环境,从而阻碍了在不同环境中获得可泛化行为。本文通过展示在Minecraft中经过RL微调的具身智能体可以实现对未见世界的零样本泛化,为解决这一挑战提供了一个初步答案。具体而言,我们探索了RL在增强3D世界中可泛化空间推理和交互能力方面的潜力。为了解决多任务RL表示中的挑战,我们分析并建立了跨视角目标规范,作为具身策略的统一多任务目标空间。此外,为了克服手动任务设计的重大瓶颈,我们提出了在高度可定制的Minecraft环境中进行自动任务合成,用于大规模多任务RL训练,并构建了一个高效的分布式RL框架来支持这一点。实验结果表明,RL显著提高了交互成功率4倍,并实现了空间推理在包括真实世界环境在内的各种环境中的零样本泛化。我们的发现强调了在3D模拟环境中进行RL训练的巨大潜力,特别是那些适合大规模任务生成的环境,从而显著提升具身智能体的空间推理能力。
🔬 方法详解
问题定义:现有强化学习方法在具身智能体中面临泛化性挑战,难以适应多样化的环境和任务。手动设计任务耗时耗力,限制了训练数据的规模和多样性。因此,需要一种能够自动生成任务并提升智能体泛化能力的强化学习方法。
核心思路:论文的核心思路是利用Minecraft环境的高度可定制性,自动生成大规模多样的任务,并采用跨视角目标规范作为统一的多任务目标空间,从而训练出具有良好泛化能力的具身智能体。通过这种方式,智能体可以学习到通用的空间推理和交互能力,从而适应未见的环境。
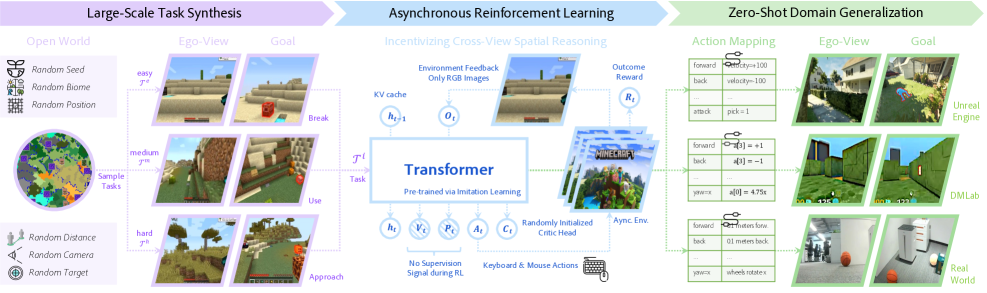
技术框架:整体框架包含三个主要模块:1) 自动任务生成器:在Minecraft环境中自动生成各种空间推理和交互任务。2) 多任务强化学习训练器:使用生成的任务训练具身智能体,采用跨视角目标规范作为统一的目标空间。3) 分布式RL框架:支持大规模任务生成和训练,提高训练效率。智能体通过观察环境,执行动作,并根据任务目标获得奖励,不断优化策略。
关键创新:论文的关键创新在于:1) 提出了一种自动任务生成方法,克服了手动任务设计的瓶颈,实现了大规模多任务训练。2) 提出了跨视角目标规范,作为统一的多任务目标空间,简化了多任务学习的复杂性,提升了泛化能力。3) 验证了在模拟环境中进行大规模RL训练,可以有效提升具身智能体在真实世界中的空间推理能力。
关键设计:论文采用了一种基于规则的自动任务生成方法,可以生成各种空间推理和交互任务,例如导航、物体操作等。跨视角目标规范将不同任务的目标统一表示为智能体在不同视角下的期望状态。损失函数采用标准的强化学习损失函数,例如PPO。网络结构采用常见的卷积神经网络和循环神经网络,用于处理视觉输入和历史信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法显著提高了智能体的交互成功率,达到了4倍的提升。更重要的是,智能体在未见过的Minecraft世界以及真实世界环境中实现了零样本泛化,证明了该方法在提升具身智能体空间推理能力方面的有效性。这些结果表明,大规模多任务强化学习是提升具身智能体泛化能力的一种有效途径。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。通过在模拟环境中进行大规模强化学习训练,可以提升智能体在真实世界中的空间推理和交互能力,从而实现更智能、更自主的机器人系统。未来,该方法有望应用于更复杂的任务和环境,例如家庭服务机器人、工业自动化等。
📄 摘要(原文)
While Reinforcement Learning (RL) has achieved remarkable success in language modeling, its triumph hasn't yet fully translated to visuomotor agents. A primary challenge in RL models is their tendency to overfit specific tasks or environments, thereby hindering the acquisition of generalizable behaviors across diverse settings. This paper provides a preliminary answer to this challenge by demonstrating that RL-finetuned visuomotor agents in Minecraft can achieve zero-shot generalization to unseen worlds. Specifically, we explore RL's potential to enhance generalizable spatial reasoning and interaction capabilities in 3D worlds. To address challenges in multi-task RL representation, we analyze and establish cross-view goal specification as a unified multi-task goal space for visuomotor policies. Furthermore, to overcome the significant bottleneck of manual task design, we propose automated task synthesis within the highly customizable Minecraft environment for large-scale multi-task RL training, and we construct an efficient distributed RL framework to support this. Experimental results show RL significantly boosts interaction success rates by $4\times$ and enables zero-shot generalization of spatial reasoning across diverse environments, including real-world settings. Our findings underscore the immense potential of RL training in 3D simulated environments, especially those amenable to large-scale task generation, for significantly advancing visuomotor agents' spatial reasoning.