villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
作者: Xiaoyu Chen, Hangxing Wei, Pushi Zhang, Chuheng Zhang, Kaixin Wang, Yanjiang Guo, Rushuai Yang, Yucen Wang, Xinquan Xiao, Li Zhao, Jianyu Chen, Jiang Bian
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-07-31 (更新: 2025-09-25)
备注: Project page: https://aka.ms/villa-x
💡 一句话要点
villa-X:增强视觉-语言-动作模型中的潜在动作建模,提升机器人操作策略泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 潜在动作建模 机器人操作 零样本泛化 强化学习
📋 核心要点
- 现有VLA模型在处理复杂任务和泛化到新环境时面临挑战,尤其是在动作表示方面。
- villa-X通过改进潜在动作的学习和集成方式,增强了VLA模型的动作表示能力和泛化性能。
- 实验表明,villa-X在模拟和真实机器人任务中均表现出色,尤其在零样本泛化方面。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为学习机器人操作策略的一种流行范式,该策略可以遵循语言指令并泛化到新的场景。最近的研究开始探索将潜在动作(即两帧之间运动的抽象表示)纳入VLA预训练。本文介绍了一种新的视觉-语言-潜在-动作(ViLLA)框架villa-X,它改进了潜在动作建模,以学习可泛化的机器人操作策略。我们的方法改进了潜在动作的学习方式以及它们如何被纳入VLA预训练。我们证明了villa-X能够以零样本方式生成潜在动作计划,即使对于未见过的机器人形态和开放词汇的符号理解也是如此。这种能力使villa-X能够在SIMPLER中的各种模拟任务以及涉及夹爪和灵巧手操作的两个真实世界机器人设置中实现卓越的性能。这些结果确立了villa-X作为学习可泛化机器人操作策略的原则性和可扩展的范例。我们相信它为未来的研究提供了坚实的基础。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在机器人操作任务中,难以有效地表示和泛化动作。它们通常依赖于直接预测低级别的动作指令,这限制了模型对新环境和新任务的适应性。痛点在于缺乏一种能够抽象和泛化的动作表示方法,使得模型难以理解语言指令中的高级意图,并将其转化为具体的动作序列。
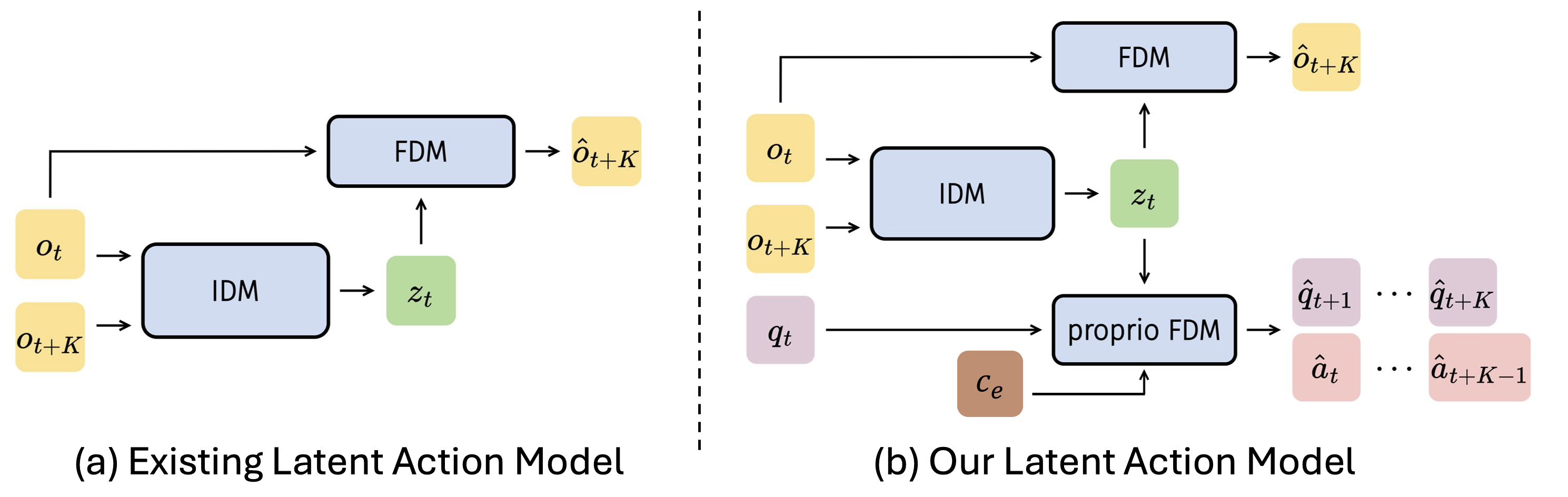
核心思路:villa-X的核心思路是通过引入和改进潜在动作建模,来提升VLA模型的泛化能力。潜在动作是指对两帧之间运动的抽象表示,它能够捕捉动作的本质特征,而忽略具体的执行细节。通过学习这种抽象的动作表示,模型可以更好地理解语言指令,并将其转化为一系列可执行的潜在动作计划。这种方法的关键在于如何有效地学习和利用这些潜在动作。
技术框架:villa-X框架包含视觉编码器、语言编码器、潜在动作编码器和动作解码器等主要模块。视觉编码器负责提取图像特征,语言编码器负责提取语言指令特征,潜在动作编码器负责学习和表示潜在动作,动作解码器负责将潜在动作解码为具体的动作指令。整个流程包括:1) 视觉和语言信息的编码;2) 基于编码信息的潜在动作规划;3) 将潜在动作解码为可执行的机器人动作。
关键创新:villa-X的关键创新在于其潜在动作建模方法。它不仅改进了潜在动作的学习方式,还优化了潜在动作在VLA预训练中的集成方式。具体来说,villa-X可能采用了更有效的损失函数、更强大的网络结构或更精细的训练策略,以提高潜在动作的表达能力和泛化性能。与现有方法相比,villa-X能够生成更准确、更鲁棒的潜在动作计划,从而提升了机器人在新环境和新任务中的表现。
关键设计:具体的参数设置、损失函数和网络结构等技术细节在论文中应该有详细描述,但根据摘要信息无法得知。可能涉及的关键设计包括:潜在动作编码器的网络结构(例如,Transformer或卷积神经网络)、用于学习潜在动作的损失函数(例如,对比损失或生成对抗损失)、以及用于将潜在动作解码为具体动作指令的解码器设计。这些细节对于理解villa-X的性能至关重要,需要在论文中进一步研究。
🖼️ 关键图片

📊 实验亮点
villa-X在SIMPLER模拟环境和真实机器人实验中均取得了显著的性能提升。尤其值得一提的是,villa-X能够以零样本方式生成潜在动作计划,即使对于未见过的机器人形态和开放词汇的符号理解也是如此。这表明villa-X具有很强的泛化能力和适应性,能够应对各种复杂的机器人操作任务。
🎯 应用场景
villa-X在机器人操作领域具有广泛的应用前景,可用于开发能够理解自然语言指令并执行复杂任务的智能机器人。例如,它可以应用于家庭服务机器人、工业自动化机器人、医疗辅助机器人等领域,提高机器人的智能化水平和服务能力。该研究的突破将推动机器人技术的发展,并为人类创造更便捷、更智能的生活。
📄 摘要(原文)
Vision-Language-Action (VLA) models have emerged as a popular paradigm for learning robot manipulation policies that can follow language instructions and generalize to novel scenarios. Recent works have begun to explore the incorporation of latent actions, abstract representations of motion between two frames, into VLA pre-training. In this paper, we introduce villa-X, a novel Vision-Language-Latent-Action (ViLLA) framework that advances latent action modeling for learning generalizable robot manipulation policies. Our approach improves both how latent actions are learned and how they are incorporated into VLA pre-training. We demonstrate that villa-X can generate latent action plans in a zero-shot fashion, even for unseen embodiments and open-vocabulary symbolic understanding. This capability enables villa-X to achieve superior performance across diverse simulation tasks in SIMPLER and on two real-world robotic setups involving both gripper and dexterous hand manipulation. These results establish villa-X as a principled and scalable paradigm for learning generalizable robot manipulation policies. We believe it provides a strong foundation for future research.