Can LLM-Reasoning Models Replace Classical Planning? A Benchmark Study
作者: Kai Goebel, Patrik Zips
分类: cs.RO, cs.AI
发布日期: 2025-07-31
💡 一句话要点
评估LLM在机器人规划中的能力:能否替代经典规划器?
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器人规划 任务规划 经典规划器 规划领域定义语言
📋 核心要点
- 现有机器人任务规划方法在处理复杂场景时面临挑战,尤其是在精确资源管理和状态跟踪方面。
- 论文探索直接使用大型语言模型(LLM)进行机器人任务规划,利用其生成能力生成可执行的计划。
- 实验表明,LLM在简单任务中表现良好,但在复杂任务中仍逊于经典规划器,揭示了LLM在机器人规划中的局限性。
📝 摘要(中文)
大型语言模型(LLM)的最新进展激发了人们对其在机器人任务规划中潜力的兴趣。虽然这些模型表现出强大的生成能力,但它们在生成结构化和可执行计划方面的有效性仍然不确定。本文系统地评估了当前最先进的各种语言模型,每个模型都直接使用规划领域定义语言(PDDL)的领域和问题文件进行提示,并将它们的规划性能与Fast Downward规划器在各种基准测试中进行比较。除了测量成功率之外,我们还评估了生成的计划如何忠实地转化为可以实际执行的动作序列,从而确定了在这种情况下使用这些模型的优势和局限性。我们的研究结果表明,虽然这些模型在较简单的规划任务中表现良好,但它们在需要精确资源管理、一致状态跟踪和严格约束遵守的更复杂场景中仍然面临挑战。这些结果强调了将语言模型应用于现实世界环境中机器人规划的根本挑战。通过概述执行过程中出现的差距,我们旨在指导未来的研究,使其朝着将语言模型与经典规划器相结合的组合方法发展,从而提高自主机器人规划的可靠性和可扩展性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在机器人任务规划领域,能否替代传统的经典规划器。现有经典规划器在处理复杂、约束严格的规划问题时,计算复杂度高,难以扩展。而LLM虽然具备强大的生成能力,但其生成计划的可靠性和可执行性尚不明确。
核心思路:论文的核心思路是直接利用LLM的文本生成能力,将规划问题转化为文本输入,并期望LLM能够生成符合规划领域定义语言(PDDL)规范的可执行计划。通过对比LLM与经典规划器在不同复杂程度任务上的表现,评估LLM在机器人规划中的潜力。
技术框架:论文采用直接提示(Direct Prompting)的方式,将PDDL格式的领域和问题文件作为输入,输入到不同的LLM中。LLM生成规划方案,然后对生成的方案进行解析,并评估其是否能够成功执行。同时,使用Fast Downward规划器作为基线,对比LLM与经典规划器在不同任务上的成功率和执行效果。
关键创新:论文的关键创新在于直接评估了现有LLM在机器人规划任务中的能力,并系统地分析了LLM在不同复杂程度任务上的表现。通过实验,揭示了LLM在处理复杂规划问题时存在的局限性,为未来结合LLM与经典规划器的研究方向提供了指导。
关键设计:论文的关键设计包括:1) 选取了多个代表性的LLM进行评估,包括不同规模和架构的模型;2) 使用PDDL作为统一的输入格式,保证了实验的可重复性和可比性;3) 设计了多种不同复杂程度的规划任务,以评估LLM在不同场景下的表现;4) 采用成功率和执行效果作为评估指标,全面衡量LLM的规划能力。
🖼️ 关键图片

📊 实验亮点
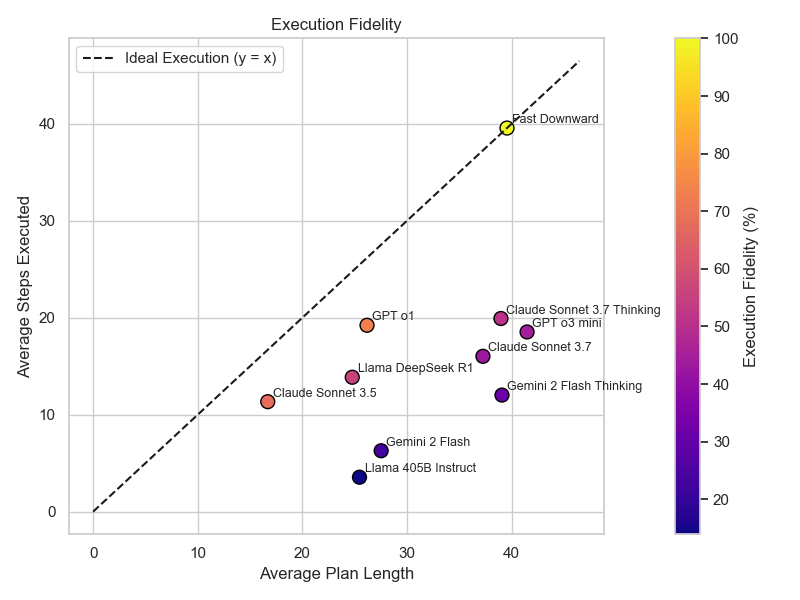
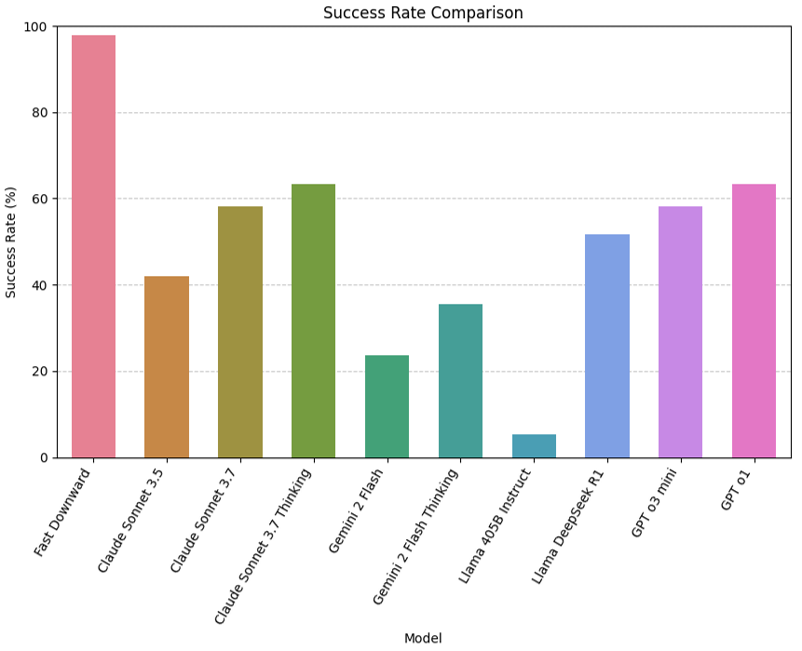
实验结果表明,LLM在简单的规划任务中表现出一定的能力,但在需要精确资源管理、状态跟踪和严格约束遵守的复杂任务中,其性能远低于Fast Downward规划器。例如,在涉及多个步骤和复杂依赖关系的任务中,LLM生成的计划经常出现逻辑错误和执行失败的情况。这表明,当前的LLM还无法完全替代经典规划器。
🎯 应用场景
该研究成果可应用于自主机器人、智能制造、自动驾驶等领域。通过结合LLM的生成能力和经典规划器的可靠性,可以开发出更智能、更灵活的机器人任务规划系统。未来的研究方向包括如何利用LLM进行任务分解、约束推理和异常处理,从而提高机器人规划的鲁棒性和适应性。
📄 摘要(原文)
Recent advancements in Large Language Models have sparked interest in their potential for robotic task planning. While these models demonstrate strong generative capabilities, their effectiveness in producing structured and executable plans remains uncertain. This paper presents a systematic evaluation of a broad spectrum of current state of the art language models, each directly prompted using Planning Domain Definition Language domain and problem files, and compares their planning performance with the Fast Downward planner across a variety of benchmarks. In addition to measuring success rates, we assess how faithfully the generated plans translate into sequences of actions that can actually be executed, identifying both strengths and limitations of using these models in this setting. Our findings show that while the models perform well on simpler planning tasks, they continue to struggle with more complex scenarios that require precise resource management, consistent state tracking, and strict constraint compliance. These results underscore fundamental challenges in applying language models to robotic planning in real world environments. By outlining the gaps that emerge during execution, we aim to guide future research toward combined approaches that integrate language models with classical planners in order to enhance the reliability and scalability of planning in autonomous robotics.