Quantifying and Visualizing Sim-to-Real Gaps: Physics-Guided Regularization for Reproducibility
作者: Yuta Kawachi
分类: cs.RO, eess.SY
发布日期: 2025-07-31
💡 一句话要点
提出物理引导增益正则化方法,缩小平衡机器人Sim-to-Real差距。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Sim-to-Real 领域随机化 机器人控制 增益正则化 物理引导 平衡机器人
📋 核心要点
- 领域随机化在机器人Sim-to-Real迁移中面临真实环境与仿真环境差异过大导致性能下降的挑战。
- 论文提出一种物理引导的增益正则化方法,通过真实实验获取机器人增益信息,约束控制器学习。
- 实验表明,该方法在平衡机器人上显著缩小了Sim-to-Real差距,优于纯领域随机化方法。
📝 摘要(中文)
本文针对机器人控制中,使用领域随机化进行Sim-to-Real迁移时,在Sim-to-Real差距扩大时性能下降的问题,提出了一种物理引导的增益正则化方案。该方案将传统PID控制器的增益重新解释为复杂、未建模的系统动态的替代品。通过简单的真实世界实验测量机器人的有效比例增益,并在训练期间惩罚神经控制器的局部输入-输出灵敏度与这些值的偏差。为了避免朴素领域随机化的保守偏差,该方法还根据当前的系统参数调节控制器。在具有110:1齿轮比的现成两轮平衡机器人上,该增益正则化、参数条件RNN在硬件中实现了与仿真结果非常接近的角度稳定时间。相比之下,纯粹的领域随机化策略表现出持续的振荡和显著的Sim-to-Real差距。实验结果表明,该方法提供了一个轻量级、可复现的框架,用于缩小经济型机器人硬件上的Sim-to-Real差距。
🔬 方法详解
问题定义:现有的基于领域随机化的Sim-to-Real方法在机器人控制中,当仿真环境与真实环境存在较大差异时,性能会显著下降。特别是在使用高齿轮比的机器人上,由于摩擦、齿隙等未建模的动态特性,导致仿真与真实环境的差异更加明显。因此,如何有效地缩小Sim-to-Real差距,提高控制策略在真实机器人上的泛化能力是一个关键问题。
核心思路:论文的核心思路是将PID控制器的增益视为对复杂、未建模的系统动态的一种近似。通过在真实环境中进行简单的实验,测量机器人的有效比例增益,然后利用这些增益信息来正则化神经控制器的训练过程。这样做的目的是约束控制器学习到的策略,使其在真实环境中的行为与仿真环境中的行为更加一致,从而缩小Sim-to-Real差距。
技术框架:该方法的技术框架主要包括以下几个步骤:1) 在真实机器人上进行实验,测量其有效比例增益;2) 设计一个神经网络控制器,该控制器以当前系统参数为条件输入;3) 在训练过程中,计算神经控制器的局部输入-输出灵敏度,并将其与真实机器人测量的有效比例增益进行比较;4) 使用一个正则化项,惩罚神经控制器的灵敏度与真实增益之间的偏差。
关键创新:该方法最重要的技术创新点在于提出了物理引导的增益正则化方案。与传统的领域随机化方法不同,该方法不是简单地随机化仿真环境的参数,而是利用真实环境中的物理信息来约束控制器的学习过程。这种方法能够更有效地缩小Sim-to-Real差距,提高控制策略在真实机器人上的泛化能力。此外,将PID增益与未建模动态关联也是一个巧妙的洞察。
关键设计:在关键设计方面,论文使用了循环神经网络(RNN)作为控制器,以处理时间序列数据。损失函数包括控制任务的损失和一个正则化项。正则化项惩罚控制器局部输入输出灵敏度与真实机器人有效比例增益的偏差。具体而言,正则化项的形式为:λ * ||J - K||^2,其中J是控制器的雅可比矩阵,K是真实机器人的有效比例增益,λ是正则化系数。此外,控制器以当前系统参数为条件输入,以避免过度保守的领域随机化偏差。
🖼️ 关键图片

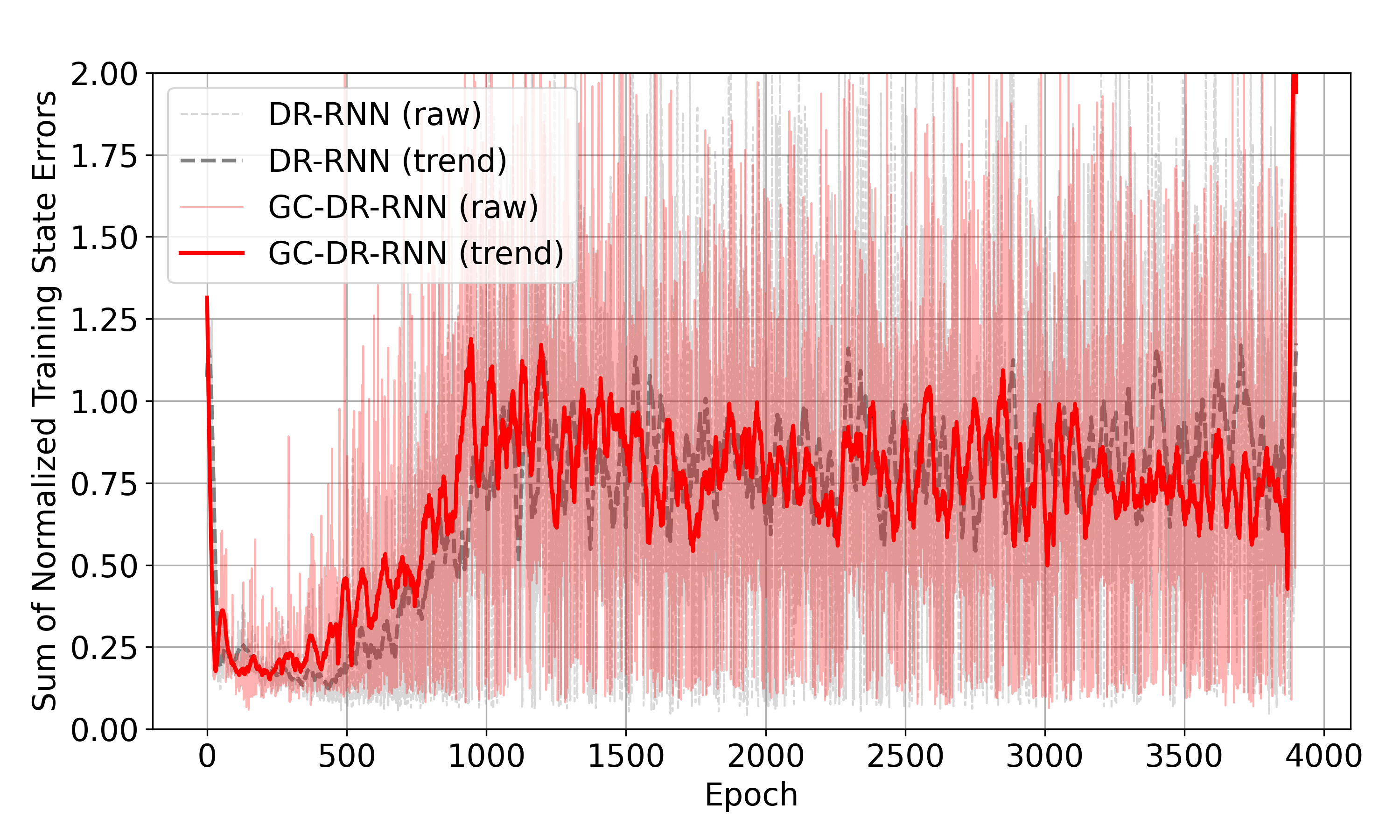
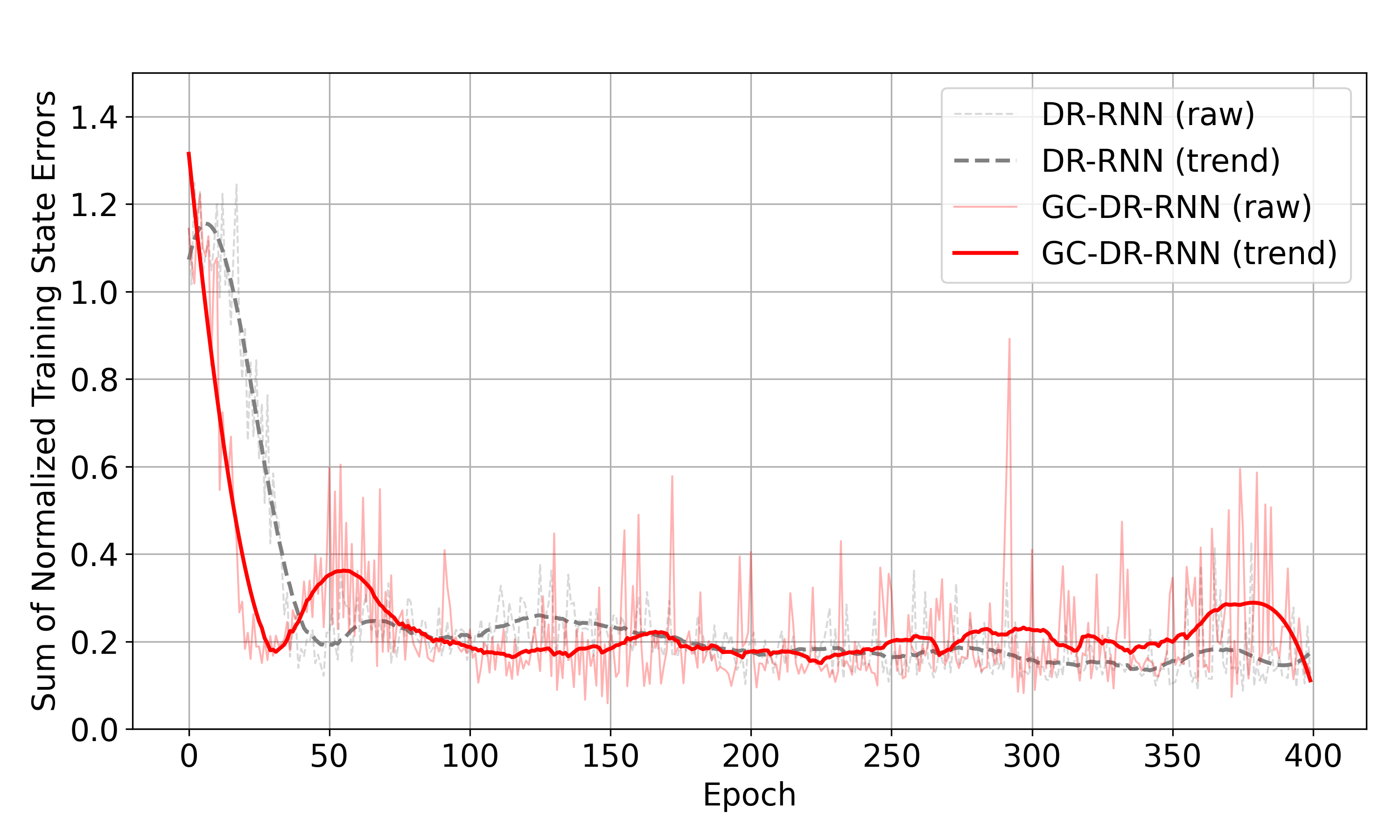
📊 实验亮点
实验结果表明,在两轮平衡机器人上,使用该增益正则化、参数条件RNN在硬件中实现了与仿真结果非常接近的角度稳定时间。相比之下,纯粹的领域随机化策略表现出持续的振荡和显著的Sim-to-Real差距。这表明该方法能够有效地缩小Sim-to-Real差距,提高控制策略在真实机器人上的性能。
🎯 应用场景
该研究成果可应用于各种需要Sim-to-Real迁移的机器人控制任务,尤其适用于那些难以精确建模的复杂系统,例如具有高齿轮比、存在摩擦和齿隙等非线性特性的机器人。该方法能够降低机器人开发的成本和时间,加速机器人技术的应用和普及。未来,该方法可以扩展到更复杂的机器人系统和控制任务中。
📄 摘要(原文)
Simulation-to-real transfer using domain randomization for robot control often relies on low-gear-ratio, backdrivable actuators, but these approaches break down when the sim-to-real gap widens. Inspired by the traditional PID controller, we reinterpret its gains as surrogates for complex, unmodeled plant dynamics. We then introduce a physics-guided gain regularization scheme that measures a robot's effective proportional gains via simple real-world experiments. Then, we penalize any deviation of a neural controller's local input-output sensitivities from these values during training. To avoid the overly conservative bias of naive domain randomization, we also condition the controller on the current plant parameters. On an off-the-shelf two-wheeled balancing robot with a 110:1 gearbox, our gain-regularized, parameter-conditioned RNN achieves angular settling times in hardware that closely match simulation. At the same time, a purely domain-randomized policy exhibits persistent oscillations and a substantial sim-to-real gap. These results demonstrate a lightweight, reproducible framework for closing sim-to-real gaps on affordable robotic hardware.