Benchmarking Massively Parallelized Multi-Task Reinforcement Learning for Robotics Tasks
作者: Viraj Joshi, Zifan Xu, Bo Liu, Peter Stone, Amy Zhang
分类: cs.RO
发布日期: 2025-07-31 (更新: 2025-08-01)
备注: RLC 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MTBench:大规模并行多任务强化学习机器人任务基准测试平台
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多任务强化学习 机器人 基准测试 大规模并行 IsaacGym
📋 核心要点
- 现有MTRL研究主要集中在低并行度的离策略方法,无法充分利用GPU加速模拟带来的大规模并行能力。
- 论文提出了MTBench,一个包含多种机器人操作和运动任务的开源基准测试平台,并集成了多种RL和MTRL算法。
- 实验表明MTBench能够高效评估MTRL方法,并揭示了大规模并行化与MTRL结合带来的新挑战。
📝 摘要(中文)
多任务强化学习(MTRL)已成为将强化学习(RL)应用于一系列复杂现实机器人任务的关键训练范式,这些任务需要通用且鲁棒的策略。同时,大规模并行训练越来越受欢迎,这不仅通过GPU加速模拟显著加速了数据收集,还通过并行模拟异构场景实现了跨多个任务的多样化数据收集。然而,现有的MTRL研究主要局限于低并行机制下的离策略方法,如SAC。MTRL可以利用on-policy算法更高的渐近性能,因为这些算法的批次需要来自当前策略的数据,从而可以利用GPU加速模拟提供的大规模并行化。为了弥合这一差距,我们引入了一个大规模并行化的机器人多任务基准测试平台(MTBench),这是一个开源基准测试平台,包含50个操作任务和20个运动任务,使用GPU加速模拟器IsaacGym实现。MTBench还包括四种基本RL算法和七种最先进的MTRL算法和架构,为评估它们的性能提供了一个统一的框架。我们广泛的实验突出了使用MTBench评估MTRL方法的优越速度,同时也揭示了将大规模并行化与MTRL相结合所带来的独特挑战。代码可在https://github.com/Viraj-Joshi/MTBench获取。
🔬 方法详解
问题定义:现有的多任务强化学习研究,尤其是在机器人领域,往往受限于计算资源的限制,无法充分利用大规模并行计算的优势。大多数研究集中在低并行度的离策略算法上,而忽略了具有更高渐近性能的on-policy算法,因为后者需要从当前策略收集数据,对并行计算提出了更高的要求。因此,如何高效地利用大规模并行计算来加速多任务强化学习的训练,并充分发挥on-policy算法的潜力,是一个亟待解决的问题。
核心思路:论文的核心思路是构建一个大规模并行化的多任务强化学习基准测试平台,使得研究人员能够方便地评估各种MTRL算法在不同机器人任务上的性能,并探索大规模并行计算与MTRL结合所带来的挑战和机遇。通过提供统一的评估框架和丰富的任务集合,促进MTRL算法的开发和应用。
技术框架:MTBench平台基于GPU加速的IsaacGym模拟器构建,包含50个操作任务和20个运动任务。该平台集成了四种基础强化学习算法(具体算法未知)以及七种最先进的多任务强化学习算法和架构(具体算法未知)。用户可以在该平台上方便地运行各种MTRL算法,并评估其在不同任务上的性能。MTBench提供了一套统一的API和评估指标,方便用户进行算法比较和分析。
关键创新:MTBench的关键创新在于其大规模并行化的设计和丰富的任务集合。通过利用GPU加速的IsaacGym模拟器,MTBench能够高效地模拟大量的机器人环境,从而加速数据收集和算法训练。此外,MTBench提供的任务集合涵盖了多种不同的机器人操作和运动任务,能够更全面地评估MTRL算法的泛化能力和鲁棒性。
关键设计:论文中没有详细描述关键的参数设置、损失函数、网络结构等技术细节。但是,可以推断,该平台的设计需要考虑如何有效地利用GPU资源进行并行计算,如何设计合适的奖励函数来引导智能体学习,以及如何选择合适的网络结构来表示策略和价值函数。此外,如何平衡不同任务之间的学习进度,避免出现负迁移现象,也是一个需要考虑的关键问题。
🖼️ 关键图片

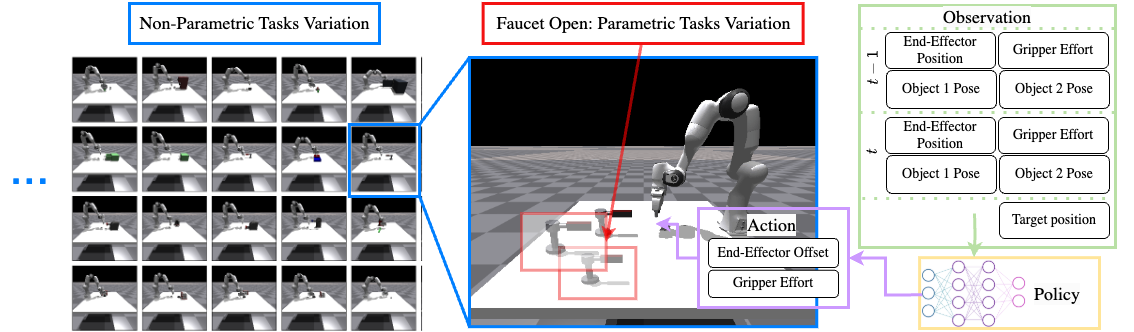
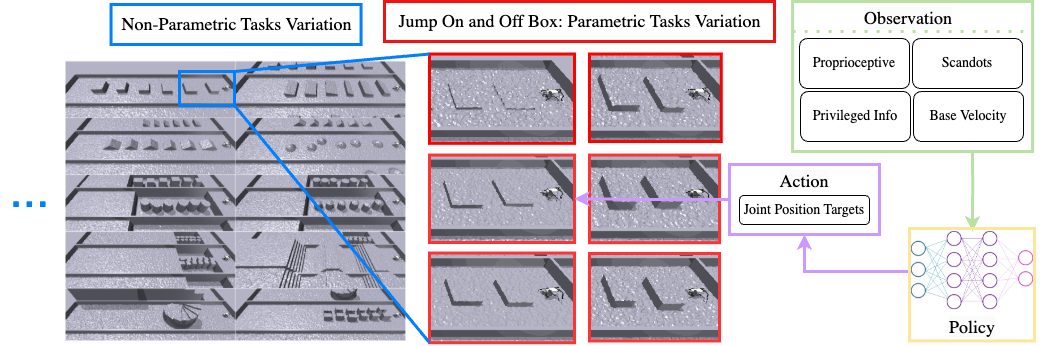
📊 实验亮点
论文的主要亮点在于提出了MTBench这一大规模并行多任务强化学习基准测试平台。实验结果表明,MTBench能够显著加速MTRL算法的评估过程,并揭示了大规模并行化与MTRL结合所带来的独特挑战。具体的性能数据和对比基线在论文中没有详细给出,但强调了MTBench在评估速度上的优势。
🎯 应用场景
该研究成果可应用于机器人自主操作、自动驾驶、智能制造等领域。通过MTBench,研究人员可以更高效地开发和评估多任务强化学习算法,从而提升机器人在复杂环境中的适应性和泛化能力。该平台有望加速机器人技术的进步,并推动其在实际场景中的广泛应用。
📄 摘要(原文)
Multi-task Reinforcement Learning (MTRL) has emerged as a critical training paradigm for applying reinforcement learning (RL) to a set of complex real-world robotic tasks, which demands a generalizable and robust policy. At the same time, \emph{massively parallelized training} has gained popularity, not only for significantly accelerating data collection through GPU-accelerated simulation but also for enabling diverse data collection across multiple tasks by simulating heterogeneous scenes in parallel. However, existing MTRL research has largely been limited to off-policy methods like SAC in the low-parallelization regime. MTRL could capitalize on the higher asymptotic performance of on-policy algorithms, whose batches require data from the current policy, and as a result, take advantage of massive parallelization offered by GPU-accelerated simulation. To bridge this gap, we introduce a massively parallelized $\textbf{M}$ulti-$\textbf{T}$ask $\textbf{Bench}$mark for robotics (MTBench), an open-sourced benchmark featuring a broad distribution of 50 manipulation tasks and 20 locomotion tasks, implemented using the GPU-accelerated simulator IsaacGym. MTBench also includes four base RL algorithms combined with seven state-of-the-art MTRL algorithms and architectures, providing a unified framework for evaluating their performance. Our extensive experiments highlight the superior speed of evaluating MTRL approaches using MTBench, while also uncovering unique challenges that arise from combining massive parallelism with MTRL. Code is available at https://github.com/Viraj-Joshi/MTBench