Think, Act, Learn: A Framework for Autonomous Robotic Agents using Closed-Loop Large Language Models
作者: Anjali R. Menon, Rohit K. Sharma, Priya Singh, Chengyu Wang, Aurora M. Ferreira, Mateja Novak
分类: cs.RO, cs.HC
发布日期: 2025-07-26 (更新: 2025-12-29)
备注: 13 pages, 7 figures
💡 一句话要点
提出Think, Act, Learn框架,利用闭环LLM提升机器人自主学习和适应能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 闭环控制 大型语言模型 机器人学习 自主导航 具身智能 经验记忆 自我反思
📋 核心要点
- 现有机器人系统依赖开放循环LLM,缺乏对动态环境的适应性,鲁棒性不足。
- T-A-L框架通过闭环反馈,使LLM能够反思失败、学习经验,并持续优化策略。
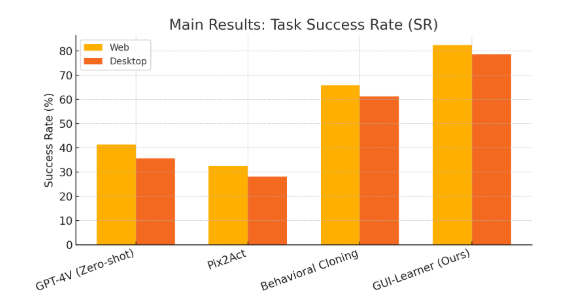
- 实验表明,T-A-L框架在成功率、收敛速度和泛化能力方面均优于传统方法。
📝 摘要(中文)
本文提出了一种名为“Think, Act, Learn”(T-A-L)的框架,旨在使具身智能体能够通过持续交互自主学习和改进其策略。该框架建立了一个闭环循环,其中LLM首先“思考”,将高层命令分解为可执行的计划。然后,机器人“行动”,执行这些计划并收集丰富的多模态感官反馈。关键在于,“学习”模块处理这些反馈,促进LLM驱动的自我反思,使智能体能够对其失败进行因果分析并生成纠正策略。这些见解存储在经验记忆中,以指导未来的规划循环。在模拟和真实世界的实验表明,T-A-L智能体显著优于基线方法,包括开放循环LLM、行为克隆和传统强化学习。该框架在复杂的长时程任务中实现了超过97%的成功率,平均仅需9次试验即可收敛到稳定的策略,并表现出对未见任务的显著泛化能力。这项工作朝着开发更鲁棒、适应性更强和真正自主的机器人智能体迈出了重要一步。
🔬 方法详解
问题定义:现有基于LLM的机器人控制系统通常采用开放循环模式,即LLM一次性生成行动计划,机器人执行。这种方式无法应对动态环境中出现的意外情况,缺乏自适应性和鲁棒性。因此,需要一种能够使机器人自主学习和适应环境变化的闭环控制框架。
核心思路:T-A-L框架的核心思想是建立一个“思考-行动-学习”的闭环反馈系统。LLM负责高层规划(思考),机器人执行计划并收集环境反馈(行动),然后LLM利用这些反馈进行自我反思和策略改进(学习)。通过不断迭代,机器人可以逐渐掌握更有效的行动策略。
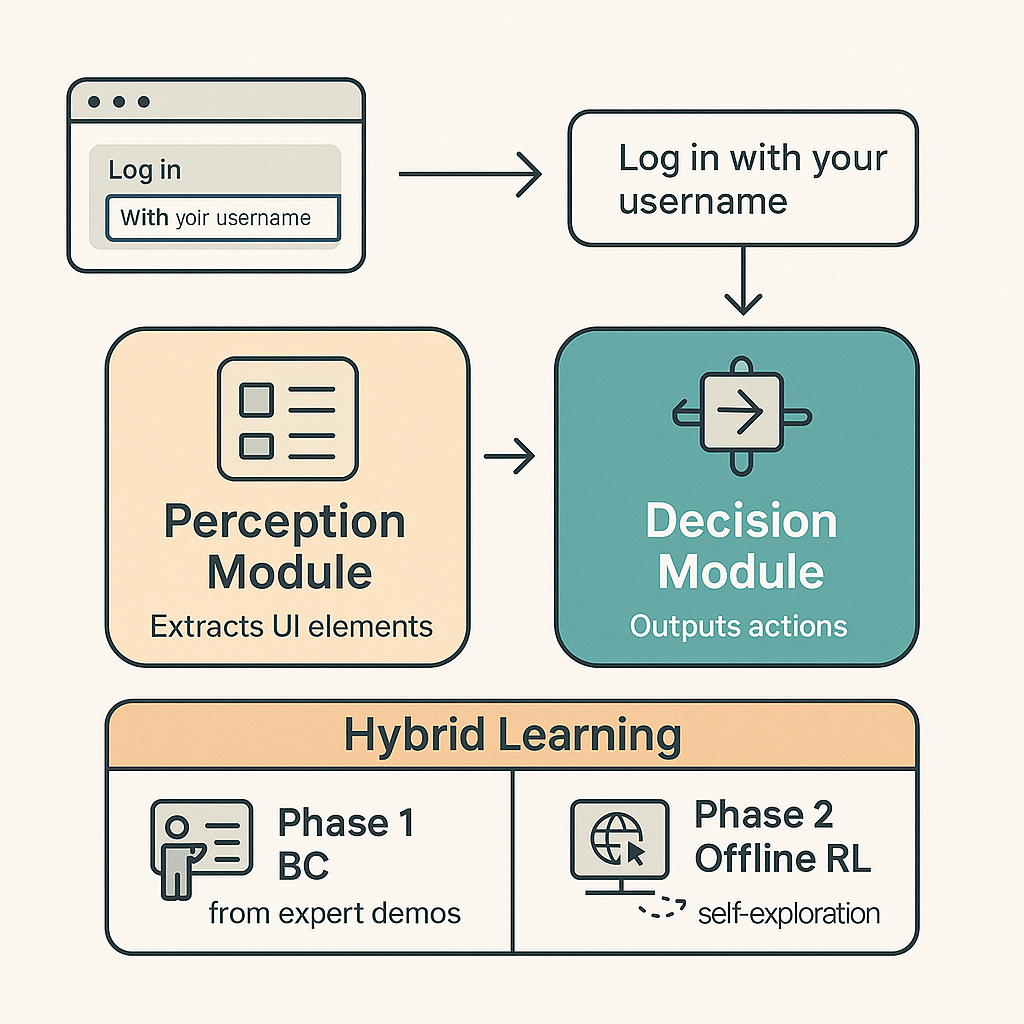
技术框架:T-A-L框架包含三个主要模块:1) 思考(Think):LLM将高层指令分解为一系列可执行的动作序列。2) 行动(Act):机器人执行这些动作,并收集多模态感官数据,例如图像、深度信息和力矩。3) 学习(Learn):该模块处理感官数据,评估行动效果,并利用LLM进行因果分析,找出失败原因并生成改进策略。这些策略被存储在经验记忆中,用于指导未来的规划过程。
关键创新:T-A-L框架的关键创新在于将LLM与闭环反馈机制相结合,使机器人能够进行自我反思和持续学习。与传统的开放循环方法相比,T-A-L框架能够更好地适应动态环境,并提高任务完成的成功率。此外,经验记忆的设计使得机器人能够从过去的经验中学习,加速策略的收敛。
关键设计:论文中没有详细描述具体的参数设置、损失函数或网络结构。LLM的选择和提示工程是关键,需要根据具体任务进行调整。经验记忆的存储和检索机制也需要精心设计,以保证能够有效地利用历史经验。学习模块中,如何利用LLM进行有效的因果分析和策略生成也是一个重要的设计考虑。
🖼️ 关键图片
📊 实验亮点
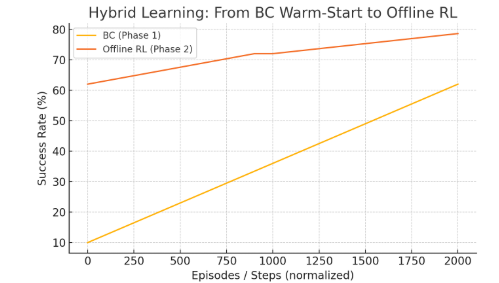
实验结果表明,T-A-L框架在复杂的长时程任务中实现了超过97%的成功率,显著优于开放循环LLM、行为克隆和传统强化学习等基线方法。此外,T-A-L框架平均仅需9次试验即可收敛到稳定的策略,并表现出对未见任务的良好泛化能力。这些结果验证了T-A-L框架的有效性和优越性。
🎯 应用场景
T-A-L框架具有广泛的应用前景,例如家庭服务机器人、工业自动化、自主导航和探索等领域。它可以使机器人在复杂和动态的环境中自主完成任务,减少对人工干预的依赖。此外,该框架还可以用于训练机器人执行新的任务,提高机器人的通用性和适应性。未来,T-A-L框架有望推动机器人技术的发展,使其在更多领域发挥重要作用。
📄 摘要(原文)
The integration of Large Language Models (LLMs) into robotics has unlocked unprecedented capabilities in high-level task planning. However, most current systems operate in an open-loop fashion, where LLMs act as one-shot planners, rendering them brittle and unable to adapt to unforeseen circumstances in dynamic physical environments. To overcome this limitation, this paper introduces the "Think, Act, Learn" (T-A-L) framework, a novel architecture that enables an embodied agent to autonomously learn and refine its policies through continuous interaction. Our framework establishes a closed-loop cycle where an LLM first "thinks" by decomposing high-level commands into actionable plans. The robot then "acts" by executing these plans while gathering rich, multimodal sensory feedback. Critically, the "learn" module processes this feedback to facilitate LLM-driven self-reflection, allowing the agent to perform causal analysis on its failures and generate corrective strategies. These insights are stored in an experiential memory to guide future planning cycles. We demonstrate through extensive experiments in both simulation and the real world that our T-A-L agent significantly outperforms baseline methods, including open-loop LLMs, Behavioral Cloning, and traditional Reinforcement Learning. Our framework achieves over a 97% success rate on complex, long-horizon tasks, converges to a stable policy in an average of just 9 trials, and exhibits remarkable generalization to unseen tasks. This work presents a significant step towards developing more robust, adaptive, and truly autonomous robotic agents.