Towards Multimodal Social Conversations with Robots: Using Vision-Language Models
作者: Ruben Janssens, Tony Belpaeme
分类: cs.RO, cs.CL, cs.HC
发布日期: 2025-07-25 (更新: 2025-08-18)
备注: Accepted at the workshop "Human - Foundation Models Interaction: A Focus On Multimodal Information" (FoMo-HRI) at IEEE RO-MAN 2025 (Camera-ready version)
💡 一句话要点
利用视觉-语言模型,提升社交机器人多模态社交对话能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交机器人 多模态对话 视觉-语言模型 人机交互 社交智能
📋 核心要点
- 现有社交机器人缺乏利用多模态信息进行社交互动的能力,限制了其社交智能。
- 本文提出利用视觉-语言模型处理视觉信息,增强社交机器人理解和响应社交线索的能力。
- 文章探讨了将视觉-语言模型应用于社交机器人对话的技术挑战和评估方法,为未来研究奠定基础。
📝 摘要(中文)
大型语言模型赋予了社交机器人自主进行开放域对话的能力。然而,它们仍然缺乏一项基本的社交技能:利用携带社交互动信息的多模态数据。以往的研究主要集中在需要参考环境或社交互动中特定现象(如对话中断)的任务型交互。本文概述了社交机器人多模态社交对话系统的总体需求,并提出视觉-语言模型能够以足够通用的方式处理各种视觉信息,从而适用于自主社交机器人。文章描述了如何将视觉-语言模型应用于该场景,讨论了仍然存在的技术挑战,并简要讨论了评估方法。
🔬 方法详解
问题定义:现有社交机器人主要依赖大型语言模型进行对话,但忽略了视觉等其他模态的信息,导致无法充分理解和响应人类的社交行为。以往研究侧重于任务型交互,缺乏对通用社交场景下多模态信息处理的关注。
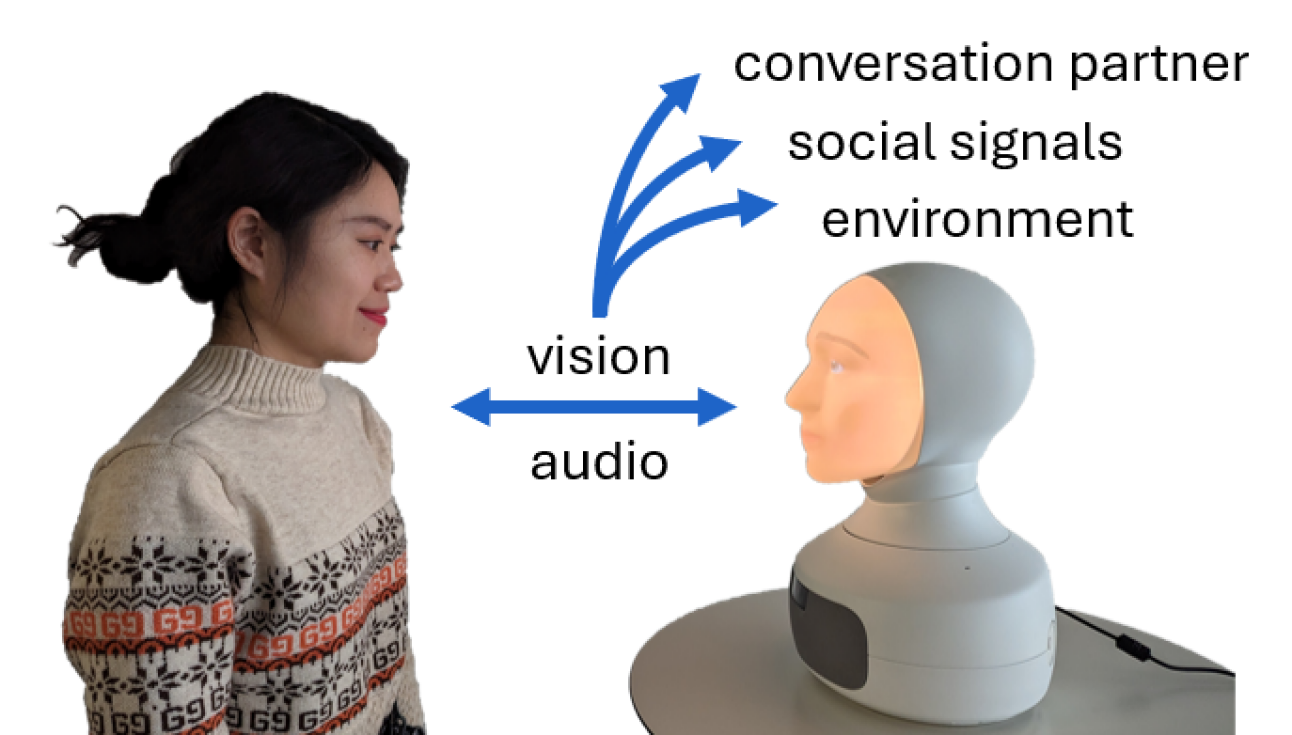
核心思路:本文的核心思路是利用视觉-语言模型(Vision-Language Models, VLMs)来处理社交互动中的视觉信息,从而使社交机器人能够更好地理解人类的情绪、意图和行为。VLMs 具有强大的跨模态理解能力,能够将视觉信息与语言信息关联起来,从而提升社交机器人的对话能力。
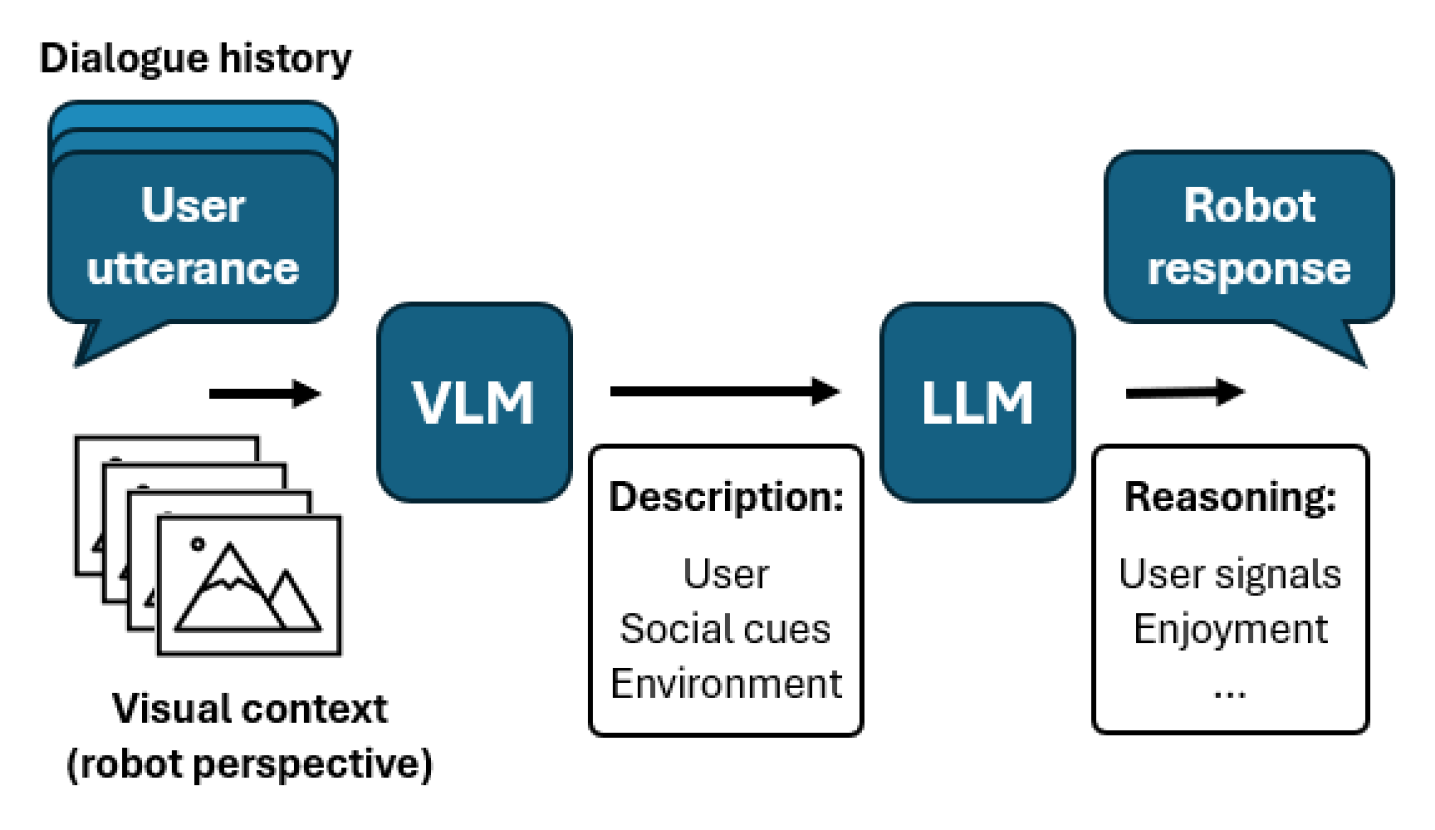
技术框架:文章并未详细描述一个完整的技术框架,而是侧重于论证 VLMs 在社交机器人对话中的潜力。可以预见的技术框架可能包含以下模块:1. 视觉感知模块:负责从摄像头等传感器获取视觉信息,例如人脸、表情、姿态等。2. 视觉-语言融合模块:利用 VLM 将视觉信息与语言信息进行融合,提取多模态特征。3. 对话生成模块:基于融合后的多模态特征,生成合适的对话回复。4. 行为控制模块:控制机器人的肢体语言和语音,使其与对话内容相协调。
关键创新:本文的关键创新在于提出将 VLMs 应用于社交机器人的通用社交对话场景。与以往侧重于任务型交互的研究不同,本文关注如何利用 VLMs 处理更广泛的社交信息,从而提升社交机器人的社交智能。
关键设计:文章并未提供具体的网络结构或参数设置。然而,可以预见的关键设计包括:1. 针对社交场景的 VLM 微调:利用包含视觉和语言信息的社交对话数据集对 VLM 进行微调,使其更好地适应社交场景。2. 多模态特征融合策略:设计有效的多模态特征融合策略,将视觉特征和语言特征进行有效融合。3. 行为生成策略:设计合理的行为生成策略,使机器人的肢体语言和语音与对话内容相协调。
🖼️ 关键图片
📊 实验亮点
由于是概念性论文,并没有具体的实验结果。文章强调了视觉-语言模型在处理社交互动中视觉信息方面的潜力,并指出了将视觉-语言模型应用于社交机器人对话的技术挑战和评估方法,为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于各种需要人机社交互动的场景,例如:陪伴机器人、教育机器人、医疗辅助机器人等。通过提升社交机器人的多模态社交对话能力,可以增强用户体验,提高机器人的实用性和接受度,并有望在情感支持、认知训练等方面发挥重要作用。
📄 摘要(原文)
Large language models have given social robots the ability to autonomously engage in open-domain conversations. However, they are still missing a fundamental social skill: making use of the multiple modalities that carry social interactions. While previous work has focused on task-oriented interactions that require referencing the environment or specific phenomena in social interactions such as dialogue breakdowns, we outline the overall needs of a multimodal system for social conversations with robots. We then argue that vision-language models are able to process this wide range of visual information in a sufficiently general manner for autonomous social robots. We describe how to adapt them to this setting, which technical challenges remain, and briefly discuss evaluation practices.