ReSemAct: Advancing Fine-Grained Robotic Manipulation via Semantic Structuring and Affordance Refinement
作者: Chenyu Su, Weiwei Shang, Chen Qian, Fei Zhang, Shuang Cong
分类: cs.RO, cs.AI, cs.CV, cs.HC, cs.LG
发布日期: 2025-07-24 (更新: 2025-12-29)
备注: Code and videos: https://github.com/scy-v/ReSemAct and https://resemact.github.io
🔗 代码/项目: GITHUB
💡 一句话要点
ReSemAct:通过语义结构化和行为精细化提升机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 语义理解 行为精细化 多模态学习 大语言模型
📋 核心要点
- 现有方法将自然语言语义压缩为过于简化的行为表示,无法充分利用隐式语义信息,限制了机器人精细操作能力。
- ReSemAct通过语义结构化和行为精细化(SSAR)策略,利用多模态大语言模型和视觉基础模型进行协同推理,提升操作精度。
- 实验表明,ReSemAct在零样本条件下,在家庭和化学实验室等复杂环境中表现出良好的鲁棒性和泛化能力。
📝 摘要(中文)
精细化的机器人操作需要将自然语言指令转化为合适的行为目标。然而,现有方法通常依赖于基础模型,将丰富的语义信息压缩为过于简化的行为表示,阻碍了隐式语义信息的利用。为了解决这些挑战,我们提出了ReSemAct,一种新颖的统一操作框架,它引入了语义结构化和行为精细化(SSAR),由多模态大型语言模型(MLLMs)和视觉基础模型(VFMs)之间的自动协同推理驱动。具体而言,语义结构化模块从自然语言和RGB观测中提取统一的语义行为描述,将行为区域、隐式功能意图和粗略的行为锚点组织成结构化表示,以供下游精细化。在此基础上,行为精细化策略实例化了两个互补的流程,分别专注于几何和位置的优化,从而产生精细的行为目标。这些精细化的目标随后被编码为实时关节空间优化目标,从而在动态环境中实现反应性和鲁棒性的操作。在语义丰富的家庭环境和稀疏的化学实验室环境中进行了广泛的仿真和真实世界实验。结果表明,ReSemAct在零样本条件下执行各种任务,展示了SSAR与基础模型在精细操作中的鲁棒性。
🔬 方法详解
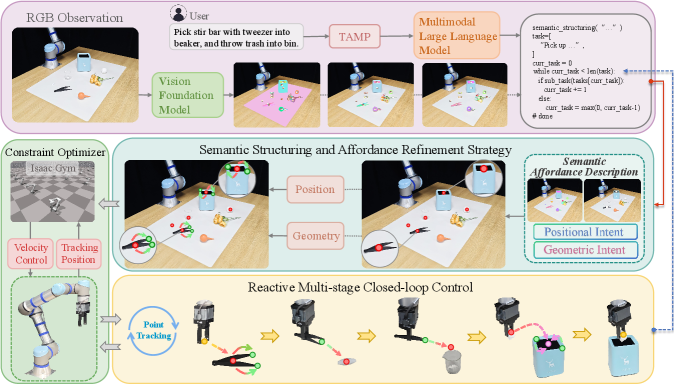
问题定义:现有基于基础模型的机器人操作方法,在将自然语言指令转化为机器人可执行的动作时,往往会过度简化语义信息,导致无法充分利用场景中的隐式语义知识,从而限制了机器人执行精细操作的能力。这些方法难以处理复杂环境和动态变化,缺乏鲁棒性和泛化性。
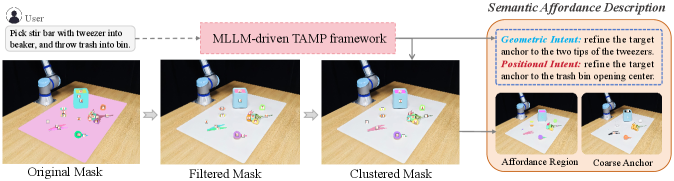
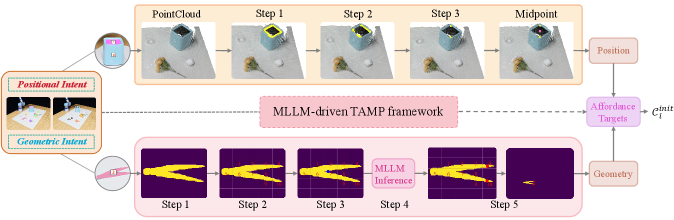
核心思路:ReSemAct的核心思路是通过语义结构化和行为精细化(SSAR)策略,显式地提取和利用场景中的语义信息。首先,将自然语言指令和视觉信息融合,构建结构化的语义表示,包含行为区域、功能意图和粗略锚点。然后,通过几何和位置两个互补的流程,对行为目标进行精细化,生成精确的机器人动作。
技术框架:ReSemAct框架包含两个主要模块:语义结构化(Semantic Structuring)和行为精细化(Affordance Refinement)。语义结构化模块利用多模态大语言模型(MLLMs)和视觉基础模型(VFMs)提取语义信息,构建结构化的语义行为描述。行为精细化模块则基于该描述,通过几何和位置两个流程,生成精细化的行为目标。最终,这些目标被编码为实时关节空间优化目标,驱动机器人执行操作。
关键创新:ReSemAct的关键创新在于SSAR策略,它将语义信息显式地融入到机器人操作流程中。与现有方法相比,ReSemAct能够更好地理解自然语言指令的意图,并利用场景中的隐式语义知识,从而实现更精确、更鲁棒的操作。此外,通过几何和位置两个流程的互补优化,进一步提升了行为目标的精度。
关键设计:语义结构化模块使用MLLMs和VFMs提取语义信息,具体实现细节未知。行为精细化模块包含几何和位置两个流程,分别优化行为目标的形状和位置。几何流程可能使用点云处理或网格变形等技术,位置流程可能使用强化学习或优化算法。最终的关节空间优化目标可能包含位置误差、力矩限制等约束。
🖼️ 关键图片
📊 实验亮点
ReSemAct在仿真和真实世界的实验中均取得了显著成果。在零样本条件下,ReSemAct能够成功执行各种复杂的机器人操作任务,例如在家庭环境中整理物品,在化学实验室中进行实验操作。实验结果表明,ReSemAct具有良好的鲁棒性和泛化能力,能够适应不同的环境和任务。
🎯 应用场景
ReSemAct具有广泛的应用前景,可应用于家庭服务机器人、工业自动化、医疗机器人等领域。例如,在家庭环境中,机器人可以根据自然语言指令完成复杂的家务任务,如整理物品、清洁房间等。在工业自动化领域,机器人可以执行精密的装配、检测等任务。在医疗领域,机器人可以辅助医生进行手术、康复训练等。
📄 摘要(原文)
Fine-grained robotic manipulation requires grounding natural language into appropriate affordance targets. However, most existing methods driven by foundation models often compress rich semantics into oversimplified affordances, preventing exploitation of implicit semantic information. To address these challenges, we present ReSemAct, a novel unified manipulation framework that introduces Semantic Structuring and Affordance Refinement (SSAR), powered by the automated synergistic reasoning between Multimodal Large Language Models (MLLMs) and Vision Foundation Models (VFMs). Specifically, the Semantic Structuring module derives a unified semantic affordance description from natural language and RGB observations, organizing affordance regions, implicit functional intent, and coarse affordance anchors into a structured representation for downstream refinement. Building upon this specification, the Affordance Refinement strategy instantiates two complementary flows that separately specialize geometry and position, yielding fine-grained affordance targets. These refined targets are then encoded as real-time joint-space optimization objectives, enabling reactive and robust manipulation in dynamic environments. Extensive simulation and real-world experiments are conducted in semantically rich household and sparse chemical lab environments. The results demonstrate that ReSemAct performs diverse tasks under zero-shot conditions, showcasing the robustness of SSAR with foundation models in fine-grained manipulation. Code and videos at https://github.com/scy-v/ReSemAct and https://resemact.github.io.