InstructVLA: Vision-Language-Action Instruction Tuning from Understanding to Manipulation
作者: Shuai Yang, Hao Li, Yilun Chen, Bin Wang, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, Jiangmiao Pang
分类: cs.RO, cs.CV
发布日期: 2025-07-23
备注: 38 pages
💡 一句话要点
InstructVLA:通过视觉-语言-动作指令调优实现从理解到操作的机器人控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 指令调优 机器人控制 多模态学习 混合专家 端到端学习 人机交互
📋 核心要点
- 现有VLA模型难以兼顾多模态推理和精确动作生成,且易遗忘预训练的视觉-语言能力。
- InstructVLA提出VLA-IT训练范式,通过混合专家适应的多模态训练,联合优化文本推理和动作生成。
- InstructVLA在SimplerEnv-Instruct基准上显著优于现有方法,并在真实环境中展现了推理时缩放能力。
📝 摘要(中文)
为了在现实世界中有效操作,机器人必须整合多模态推理与精确的动作生成。然而,现有的视觉-语言-动作(VLA)模型通常顾此失彼,将能力局限于特定任务的操作数据,并且遭受预训练视觉-语言能力的灾难性遗忘。为了弥合这一差距,我们引入了InstructVLA,一个端到端的VLA模型,它保留了大型视觉-语言模型(VLM)的灵活推理能力,同时提供了领先的操作性能。InstructVLA引入了一种新的训练范式,即视觉-语言-动作指令调优(VLA-IT),它采用混合专家适应的多模态训练,以在标准VLM语料库和精心策划的650K样本VLA-IT数据集上共同优化文本推理和动作生成。在同域SimplerEnv任务上,InstructVLA比SpatialVLA提高了30.5%。为了评估泛化能力,我们引入了SimplerEnv-Instruct,一个需要闭环控制和高级指令理解的80任务基准,InstructVLA优于微调的OpenVLA 92%,优于GPT-4o辅助的动作专家29%。此外,InstructVLA在多模态任务上超越了基线VLM,并通过利用文本推理来提高模拟和现实环境中的操作性能,从而展示了推理时缩放能力。这些结果证明了InstructVLA在将直观和可控的人机交互与高效策略学习相结合方面的潜力。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人控制中面临多重挑战。一方面,它们难以同时实现对视觉和语言信息的有效推理,以及精确的动作生成,往往顾此失彼。另一方面,这些模型通常针对特定任务进行优化,泛化能力较弱,并且容易遗忘预训练的视觉-语言知识,导致性能下降。
核心思路:InstructVLA的核心思路是通过视觉-语言-动作指令调优(VLA-IT)来解决上述问题。VLA-IT旨在利用大规模的指令数据,引导模型学习如何将视觉和语言信息转化为可执行的动作。通过这种方式,模型可以同时提升推理能力和操作性能,并保留预训练的知识。
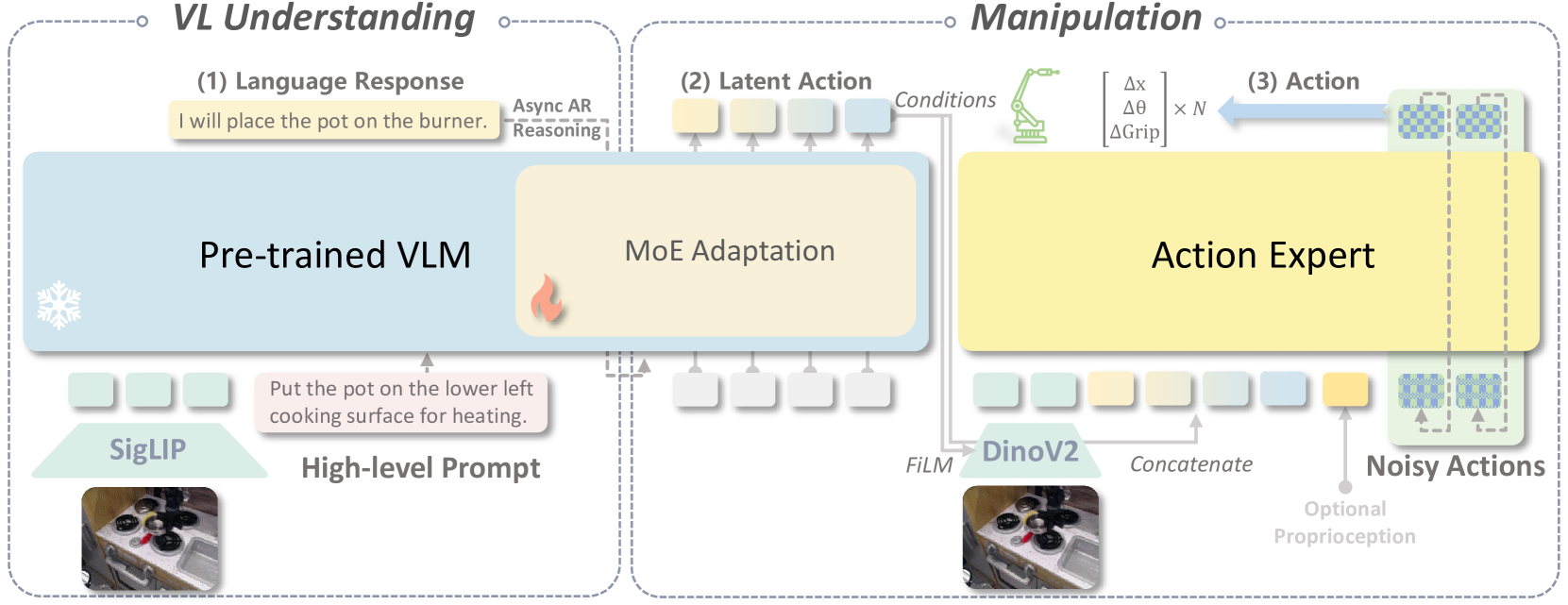
技术框架:InstructVLA采用端到端的架构,包含视觉编码器、语言编码器、动作解码器以及混合专家模块。视觉编码器和语言编码器负责提取视觉和语言特征,动作解码器负责生成动作序列。混合专家模块用于自适应地融合不同模态的信息,并根据任务需求调整模型的行为。VLA-IT训练范式包括两个阶段:首先,在标准VLM语料库上进行预训练,以获得良好的视觉-语言理解能力;然后,在精心策划的VLA-IT数据集上进行微调,以提升操作性能。
关键创新:InstructVLA的关键创新在于VLA-IT训练范式和混合专家模块的设计。VLA-IT通过大规模指令数据,实现了对模型推理和操作能力的联合优化。混合专家模块则允许模型根据任务需求自适应地调整行为,从而提高了模型的泛化能力。
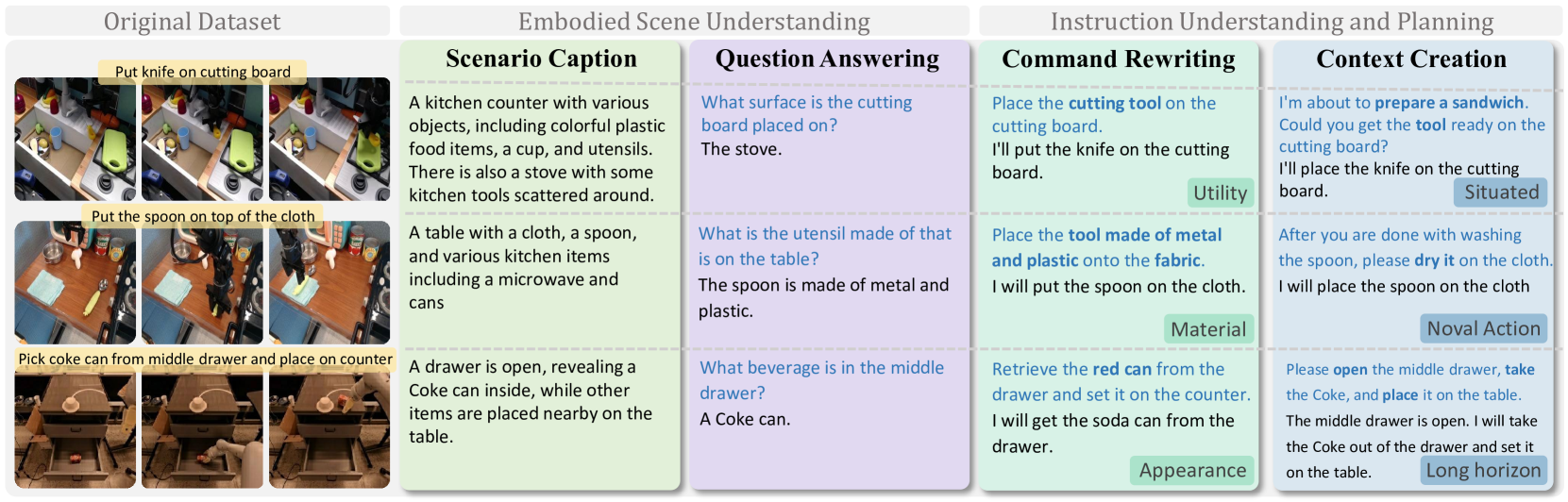
关键设计:VLA-IT数据集包含650K个样本,涵盖了各种机器人操作任务。混合专家模块由多个专家网络组成,每个专家网络负责处理特定类型的任务。模型使用交叉熵损失函数进行训练,并采用Adam优化器进行参数更新。在推理时,模型利用文本推理来指导动作生成,从而实现推理时缩放。
🖼️ 关键图片

📊 实验亮点
InstructVLA在SimplerEnv任务上比SpatialVLA提高了30.5%。在SimplerEnv-Instruct基准上,InstructVLA优于微调的OpenVLA 92%,优于GPT-4o辅助的动作专家29%。此外,InstructVLA在多模态任务上超越了基线VLM,并在模拟和真实环境中展示了推理时缩放能力,证明了其在机器人控制领域的优越性能。
🎯 应用场景
InstructVLA具有广泛的应用前景,可用于开发各种智能机器人系统,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。该模型能够理解人类指令,并执行复杂的任务,从而实现更自然和高效的人机交互。此外,InstructVLA还可以用于开发虚拟助手和智能代理,从而提升人机协作的效率和质量。
📄 摘要(原文)
To operate effectively in the real world, robots must integrate multimodal reasoning with precise action generation. However, existing vision-language-action (VLA) models often sacrifice one for the other, narrow their abilities to task-specific manipulation data, and suffer catastrophic forgetting of pre-trained vision-language capabilities. To bridge this gap, we introduce InstructVLA, an end-to-end VLA model that preserves the flexible reasoning of large vision-language models (VLMs) while delivering leading manipulation performance. InstructVLA introduces a novel training paradigm, Vision-Language-Action Instruction Tuning (VLA-IT), which employs multimodal training with mixture-of-experts adaptation to jointly optimize textual reasoning and action generation on both standard VLM corpora and a curated 650K-sample VLA-IT dataset. On in-domain SimplerEnv tasks, InstructVLA achieves 30.5% improvement over SpatialVLA. To evaluate generalization, we introduce SimplerEnv-Instruct, an 80-task benchmark requiring closed-loop control and high-level instruction understanding, where it outperforms a fine-tuned OpenVLA by 92% and an action expert aided by GPT-4o by 29%. Additionally, InstructVLA surpasses baseline VLMs on multimodal tasks and exhibits inference-time scaling by leveraging textual reasoning to boost manipulation performance in both simulated and real-world settings. These results demonstrate InstructVLA's potential for bridging intuitive and steerable human-robot interaction with efficient policy learning.