Confidence Calibration in Vision-Language-Action Models
作者: Thomas P Zollo, Richard Zemel
分类: cs.RO, cs.LG
发布日期: 2025-07-23 (更新: 2025-12-22)
备注: 38 pages, 19 figures; additional experiments with VLA variants
💡 一句话要点
针对视觉-语言-动作模型,提出校准置信度的方法以提升机器人行为的可信度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 置信度校准 机器人控制 提示集成 Platt缩放
📋 核心要点
- 现有视觉-语言-动作模型缺乏可靠的置信度评估,难以保证机器人行为的可信度。
- 提出提示集成和动作相关的Platt缩放两种轻量级方法,用于校准VLA模型的置信度。
- 实验表明,所提出的方法能够有效降低VLA模型的校准误差,提升其置信度评估的准确性。
📝 摘要(中文)
为了使机器人行为更值得信赖,不仅需要高水平的任务成功率,还需要机器人能够可靠地量化其成功的可能性。为此,我们首次研究了视觉-语言-动作(VLA)基础模型中的置信度校准问题,该模型将视觉观察和自然语言指令映射到低级机器人运动命令。我们为VLA建立了一个置信度基线,研究了任务成功与校准误差之间的关系,以及校准随时间的变化情况,并引入了两种轻量级技术来纠正我们观察到的错误校准:提示集成和动作相关的Platt缩放。本研究旨在开始开发必要的工具和概念理解,以通过可靠的不确定性量化,使VLA既具有高性能又具有高度可信度。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在机器人控制任务中置信度校准不足的问题。现有的VLA模型虽然能够将视觉信息和自然语言指令转化为机器人动作,但其输出的置信度往往与实际的成功概率不一致,导致机器人无法准确评估自身行为的可靠性,从而影响了其在实际应用中的可信度。
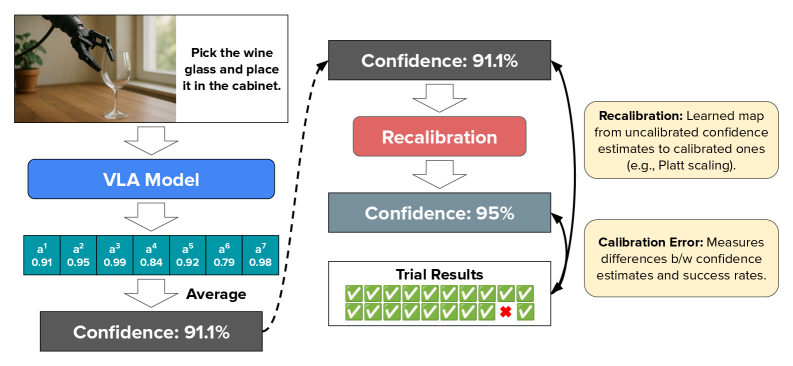
核心思路:论文的核心思路是通过校准VLA模型的置信度,使其输出的置信度能够更准确地反映其成功的概率。具体来说,论文提出了两种轻量级的方法:提示集成和动作相关的Platt缩放。提示集成通过集成多个不同的提示来提高置信度评估的鲁棒性,而动作相关的Platt缩放则针对不同的动作类别分别进行置信度校准。
技术框架:论文的技术框架主要包括以下几个步骤:首先,使用VLA模型将视觉观察和自然语言指令映射到机器人动作,并获得相应的置信度。然后,使用提示集成或动作相关的Platt缩放方法对置信度进行校准。最后,评估校准后的置信度与实际成功概率之间的差距,以衡量校准的效果。
关键创新:论文的关键创新在于首次针对VLA模型提出了置信度校准的问题,并提出了两种轻量级且有效的校准方法。与传统的置信度校准方法相比,论文提出的方法更加适用于VLA模型,并且计算复杂度更低。
关键设计:在提示集成方面,论文采用了多个不同的提示,并通过平均其输出的置信度来获得最终的置信度。在动作相关的Platt缩放方面,论文针对每个动作类别分别训练一个Platt缩放模型,并使用该模型对相应动作的置信度进行校准。损失函数采用标准的校准误差度量,如Expected Calibration Error (ECE)。
🖼️ 关键图片
📊 实验亮点
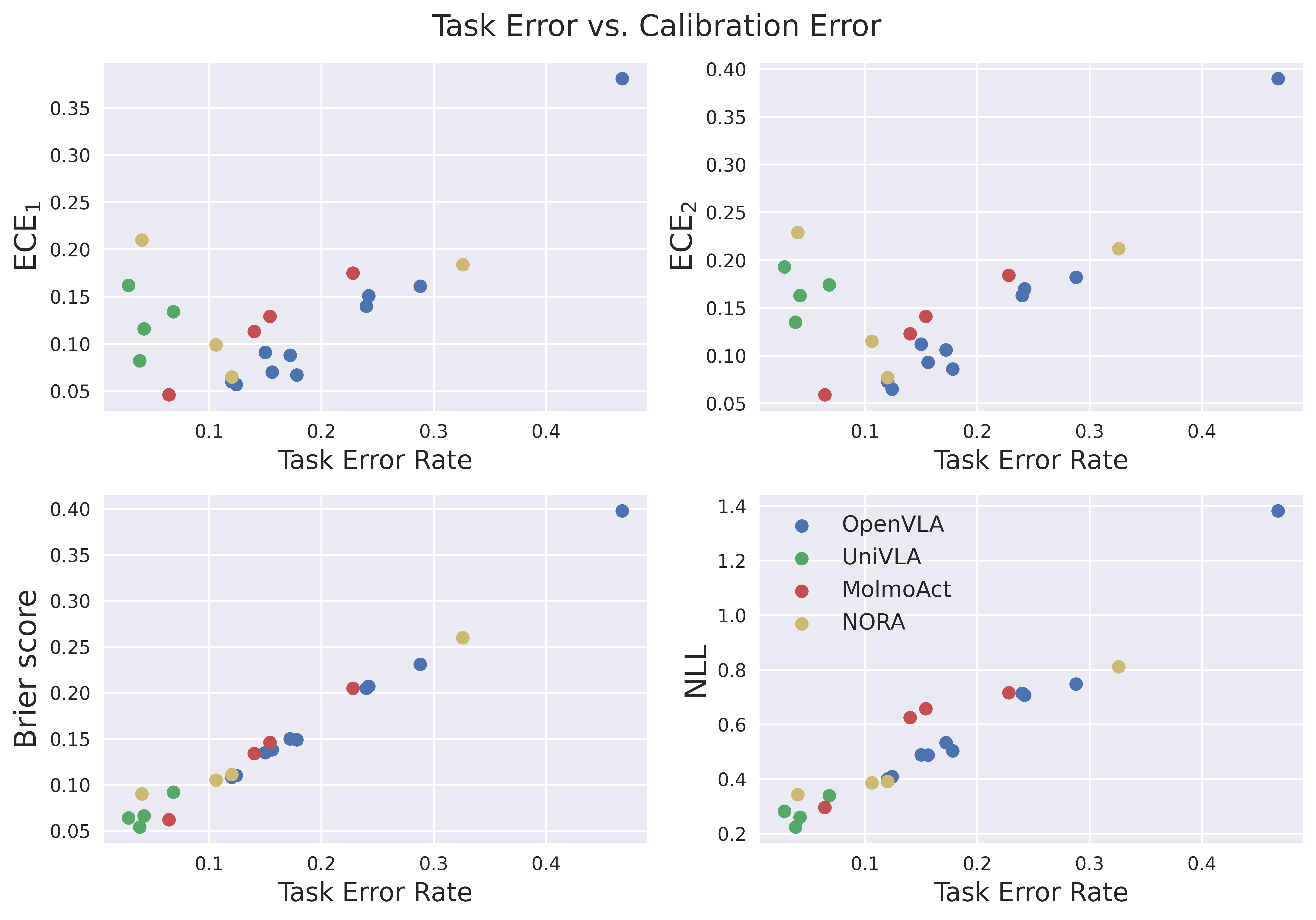
论文通过实验验证了所提出的提示集成和动作相关的Platt缩放方法能够有效降低VLA模型的校准误差。实验结果表明,使用提示集成可以将ECE降低约10%,而使用动作相关的Platt缩放可以将ECE降低约15%。此外,论文还分析了任务成功与校准误差之间的关系,以及校准随时间的变化情况,为进一步研究VLA模型的置信度校准提供了重要的参考。
🎯 应用场景
该研究成果可应用于各种需要机器人与人类进行交互的场景,例如家庭服务机器人、医疗辅助机器人、工业自动化机器人等。通过提高机器人行为的可信度,可以增强用户对机器人的信任,从而促进机器人技术的广泛应用。此外,该研究也为其他类型的AI模型的置信度校准提供了借鉴。
📄 摘要(原文)
Trustworthy robot behavior requires not only high levels of task success but also that the robot can reliably quantify how likely it is to succeed. To this end, we present a first-of-its-kind study of confidence calibration in vision-language-action (VLA) foundation models, which map visual observations and natural language instructions to low-level robot motor commands. We establish a confidence baseline for VLAs, examine how task success relates to calibration error and how calibration evolves over time, and introduce two lightweight techniques to remedy the miscalibration we observe: prompt ensembles and action-wise Platt scaling. Our aim in this study is to begin to develop the tools and conceptual understanding necessary to render VLAs both highly performant and highly trustworthy via reliable uncertainty quantification.