Evaluating Uncertainty and Quality of Visual Language Action-enabled Robots
作者: Pablo Valle, Chengjie Lu, Shaukat Ali, Aitor Arrieta
分类: cs.SE, cs.RO
发布日期: 2025-07-22 (更新: 2025-07-31)
💡 一句话要点
针对视觉语言动作机器人,提出不确定性和质量评估指标,提升任务执行监控与自适应增强能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 机器人操作 不确定性评估 质量评估 多模态学习
📋 核心要点
- 现有VLA模型评估主要依赖成功率,忽略了任务执行质量和模型置信度。
- 提出针对VLA机器人的不确定性和质量评估指标,以更全面地评估模型性能。
- 实验结果表明,所提出的指标与人类评估具有相关性,可用于区分不同质量的任务执行。
📝 摘要(中文)
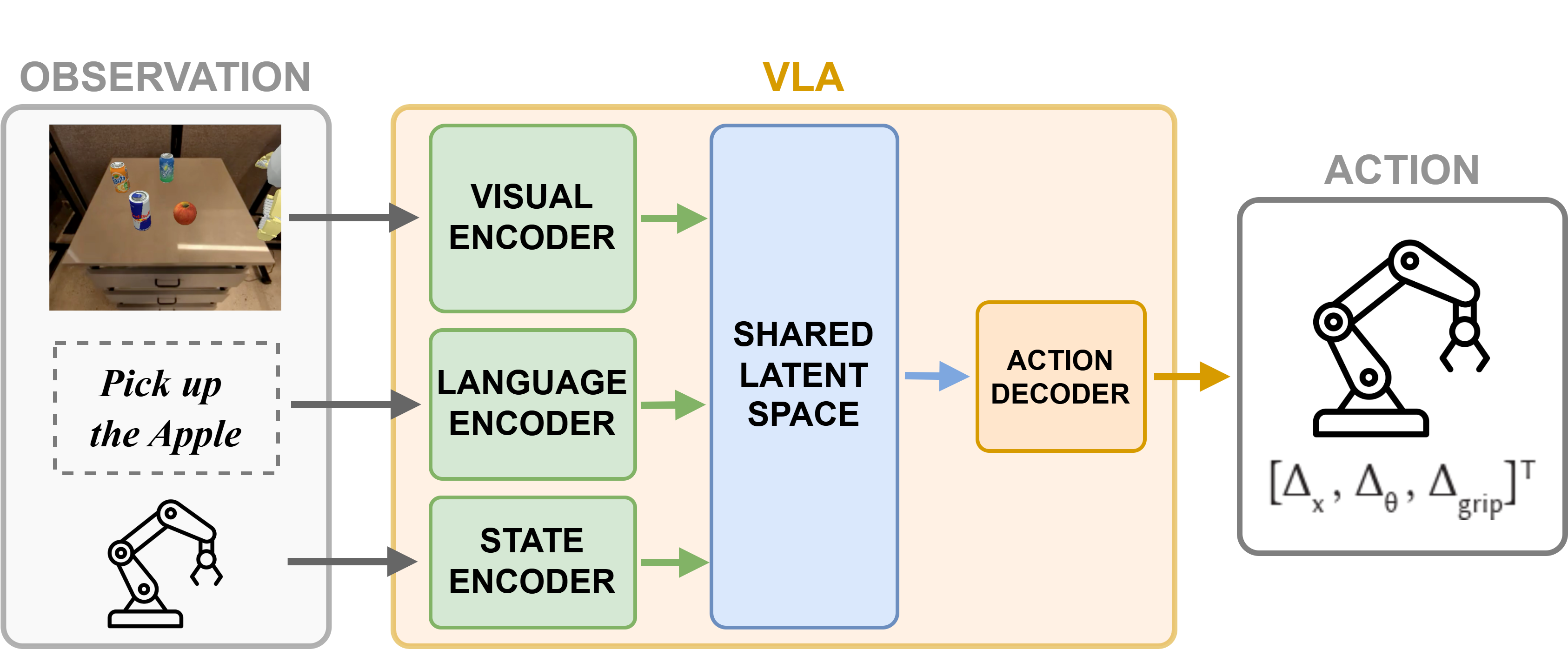
视觉语言动作(VLA)模型是一类多模态人工智能系统,它集成了视觉感知、自然语言理解和动作规划,使智能体能够理解环境、理解指令并自主执行具身任务。近年来,该领域取得了显著进展。然而,这些模型通常通过任务成功率进行评估,这无法捕捉任务执行的质量以及模型对其决策的置信度。本文针对机器人操作任务中的VLA模型,提出了八个不确定性指标和五个质量指标。我们通过一项大规模实证研究评估了它们的有效性,该研究涉及来自三个最先进的VLA模型在四个代表性机器人操作任务中的908次成功任务执行。领域专家手动标记了任务质量,使我们能够分析我们提出的指标与专家判断之间的相关性。结果表明,一些指标与人类评估表现出中等到强的相关性,突出了它们在评估任务质量和模型置信度方面的效用。此外,我们发现一些指标可以区分来自不成功任务的高、中、低质量执行,这在测试预言机不可用时可能很有趣。我们的发现挑战了当前仅依赖于二元成功率的评估实践的充分性,并为改进VLA机器人系统的实时监控和自适应增强铺平了道路。
🔬 方法详解
问题定义:现有视觉语言动作(VLA)模型的评估主要依赖于任务成功率,这种二元评估方式无法捕捉任务执行的质量,也无法反映模型对于其决策的置信程度。这使得我们难以深入了解模型的行为,也阻碍了对模型进行实时监控和自适应增强。
核心思路:本文的核心思路是设计一系列能够量化VLA模型在执行任务过程中的不确定性和任务执行质量的指标。通过这些指标,可以更细粒度地评估模型的性能,并为模型的改进提供更丰富的信息。这样设计的目的是为了弥补现有评估方法的不足,提供更全面的模型评估。
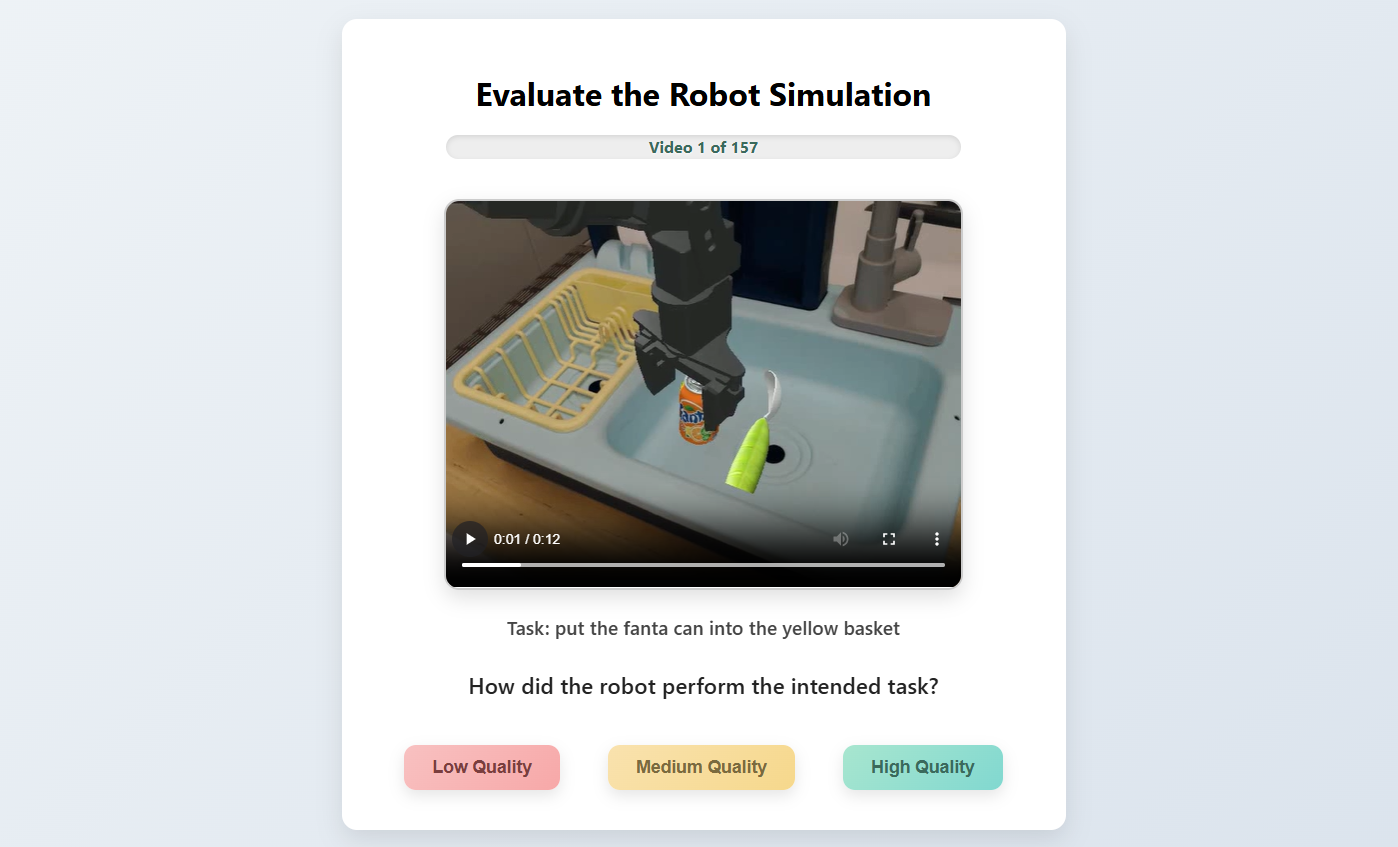
技术框架:本文提出的评估框架主要包含以下几个步骤:1) 定义不确定性指标和质量指标;2) 使用VLA模型执行机器人操作任务;3) 收集模型执行过程中的数据,并计算所提出的指标;4) 领域专家手动标注任务执行质量;5) 分析指标与专家标注之间的相关性,评估指标的有效性。其中,不确定性指标包括基于动作概率的指标,质量指标则侧重于任务完成的平滑性和效率。
关键创新:本文的关键创新在于提出了专门针对VLA机器人操作任务的不确定性和质量评估指标。这些指标不仅考虑了任务是否成功完成,还考虑了任务执行的质量和模型决策的置信度。此外,通过与人类专家评估的对比,验证了这些指标的有效性,为VLA模型的评估提供了一种新的思路。
关键设计:论文中设计了8个不确定性指标和5个质量指标。不确定性指标包括:Action Entropy, Trajectory Entropy, Action Log Probability, Trajectory Log Probability, Action Confidence, Trajectory Confidence, Action Variance, Trajectory Variance。质量指标包括:Smoothness, Efficiency, Stability, Accuracy, Completeness。这些指标的计算依赖于VLA模型在执行任务过程中产生的动作序列和状态序列。例如,Smoothness指标衡量机器人运动的平滑程度,Efficiency指标衡量任务完成的效率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所提出的不确定性和质量指标与人类专家评估具有中等到强的相关性。例如,某些指标能够有效区分高、中、低质量的任务执行,即使在任务失败的情况下也能提供有价值的信息。这表明这些指标不仅可以用于评估任务成功率,还可以用于更细粒度地评估任务执行的质量。
🎯 应用场景
该研究成果可应用于机器人操作、自动化生产线、智能家居等领域。通过实时监测VLA机器人的不确定性和任务执行质量,可以及时发现潜在问题,并采取相应的纠正措施,从而提高系统的可靠性和效率。此外,这些指标还可以用于模型的训练和优化,提升VLA机器人的整体性能。
📄 摘要(原文)
Visual Language Action (VLA) models are a multi-modal class of Artificial Intelligence (AI) systems that integrate visual perception, natural language understanding, and action planning to enable agents to interpret their environment, comprehend instructions, and perform embodied tasks autonomously. Recently, significant progress has been made to advance this field. These kinds of models are typically evaluated through task success rates, which fail to capture the quality of task execution and the mode's confidence in its decisions. In this paper, we propose eight uncertainty metrics and five quality metrics specifically designed for VLA models for robotic manipulation tasks. We assess their effectiveness through a large-scale empirical study involving 908 successful task executions from three state-of-the-art VLA models across four representative robotic manipulation tasks. Human domain experts manually labeled task quality, allowing us to analyze the correlation between our proposed metrics and expert judgments. The results reveal that several metrics show moderate to strong correlation with human assessments, highlighting their utility for evaluating task quality and model confidence. Furthermore, we found that some of the metrics can discriminate between high-, medium-, and low-quality executions from unsuccessful tasks, which can be interesting when test oracles are not available. Our findings challenge the adequacy of current evaluation practices that rely solely on binary success rates and pave the way for improved real-time monitoring and adaptive enhancement of VLA-enabled robotic systems.