Guided Reinforcement Learning for Omnidirectional 3D Jumping in Quadruped Robots
作者: Riccardo Bussola, Michele Focchi, Giulio Turrisi, Claudio Semini, Luigi Palopoli
分类: cs.RO, eess.SY
发布日期: 2025-07-22 (更新: 2025-09-29)
💡 一句话要点
提出基于引导强化学习的四足机器人全向3D跳跃方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 跳跃控制 强化学习 引导学习 贝塞尔曲线 运动规划 机器人运动
📋 核心要点
- 四足机器人跳跃运动控制面临优化方法耗时、对环境参数敏感等挑战,实际应用鲁棒性不足。
- 论文提出一种引导强化学习方法,结合贝塞尔曲线和匀加速直线运动模型,提升跳跃运动的效率和可解释性。
- 仿真和实验结果表明,该方法优于现有方法,在跳跃控制方面具有显著优势。
📝 摘要(中文)
跳跃对于四足机器人来说是一个重要的挑战,尽管它在许多操作场景中至关重要。虽然存在用于控制此类运动的优化方法,但它们通常耗时且需要大量的机器人和地形参数知识,这使得它们在实际场景中的鲁棒性较差。强化学习(RL)正在成为一种可行的替代方案,但传统的端到端方法在样本复杂度方面缺乏效率,需要在模拟中进行大量的训练,并且最终运动的可预测性较差,这使得难以验证最终运动的安全性。为了克服这些限制,本文提出了一种新颖的引导强化学习方法,该方法通过结合贝塞尔曲线和匀加速直线运动(UARM)模型,利用物理直觉来实现高效且可解释的跳跃。大量的仿真和实验结果清楚地证明了我们的方法优于现有的替代方案。
🔬 方法详解
问题定义:四足机器人实现复杂地形下的跳跃运动是一个难题。现有的优化方法需要大量的环境和机器人参数,计算成本高,且对环境变化敏感,难以保证实际应用中的鲁棒性。传统的端到端强化学习方法虽然可以学习复杂的运动策略,但样本效率低,需要大量的训练数据,且学习到的策略难以解释和验证,存在安全隐患。
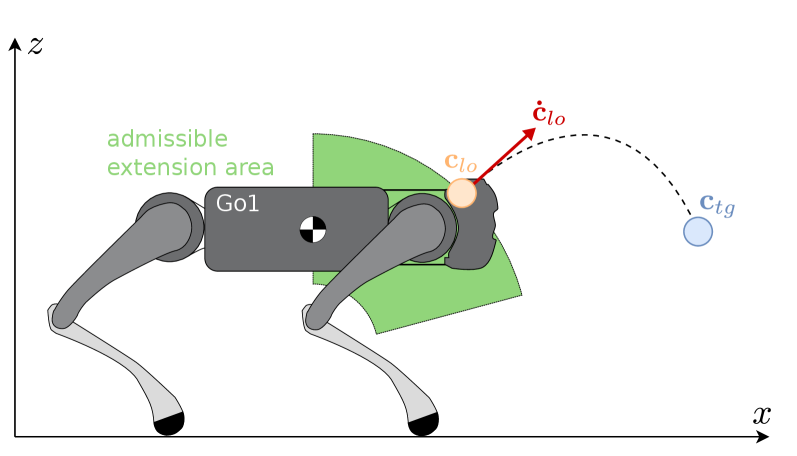
核心思路:论文的核心思路是将先验的物理知识融入到强化学习过程中,通过引导强化学习,提高样本效率和策略的可解释性。具体来说,利用贝塞尔曲线和匀加速直线运动模型对跳跃轨迹进行参数化,将连续的动作空间约束到参数化的空间中,从而降低了强化学习的难度。
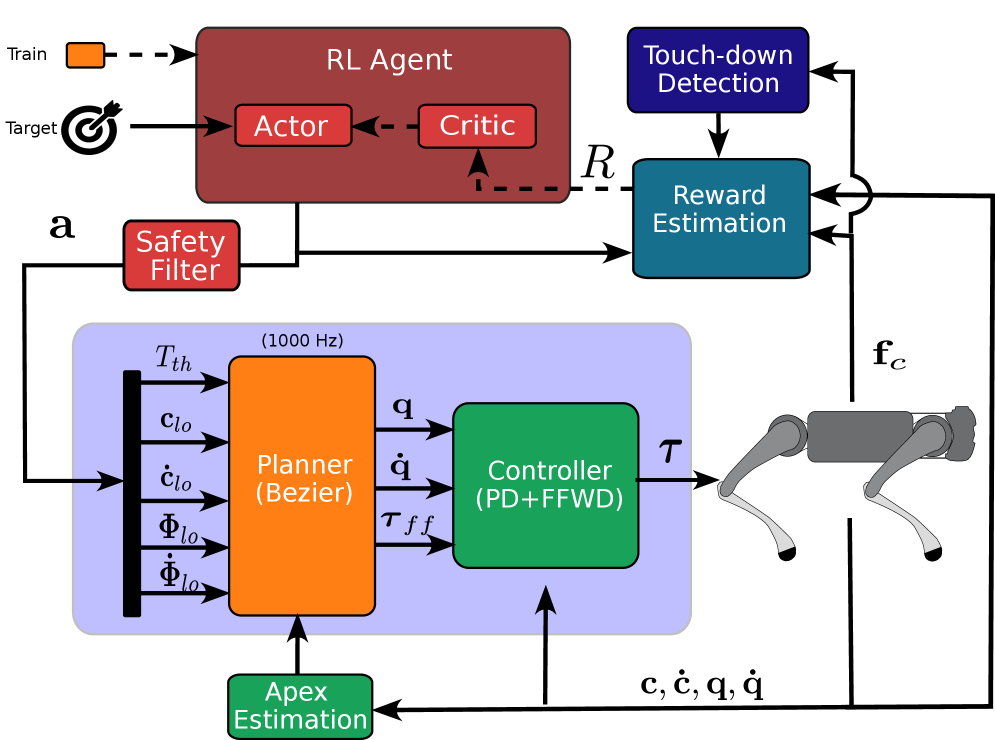
技术框架:该方法的技术框架主要包括以下几个模块:1)跳跃轨迹参数化模块:使用贝塞尔曲线和匀加速直线运动模型对跳跃轨迹进行参数化表示。2)强化学习智能体:使用强化学习算法(具体算法未知)学习最优的轨迹参数。3)环境模型:用于模拟四足机器人的运动和环境交互。整个流程是,强化学习智能体根据当前状态选择轨迹参数,环境模型根据轨迹参数模拟机器人的运动,并返回奖励信号,智能体根据奖励信号更新策略。
关键创新:该方法最重要的技术创新点在于将先验的物理知识融入到强化学习过程中,通过引导强化学习,提高了样本效率和策略的可解释性。与传统的端到端强化学习方法相比,该方法不需要大量的训练数据,且学习到的策略更加可解释和可验证。与传统的优化方法相比,该方法不需要精确的环境和机器人参数,具有更强的鲁棒性。
关键设计:论文的关键设计包括:1)贝塞尔曲线和匀加速直线运动模型的选择:选择合适的贝塞尔曲线和匀加速直线运动模型可以有效地参数化跳跃轨迹,降低强化学习的难度。2)奖励函数的设计:设计合适的奖励函数可以引导强化学习智能体学习到期望的跳跃策略。奖励函数可能包括跳跃距离、跳跃高度、落地稳定性等指标。(具体奖励函数设计未知)3)强化学习算法的选择:选择合适的强化学习算法可以提高学习效率和策略的性能。(具体算法未知)
🖼️ 关键图片

📊 实验亮点
论文通过仿真和实验验证了所提出方法的有效性。实验结果表明,该方法在跳跃距离、跳跃高度和落地稳定性等方面均优于现有的方法。具体的性能数据和对比基线未知,但摘要明确指出该方法优于现有替代方案。
🎯 应用场景
该研究成果可应用于四足机器人在复杂地形下的搜索救援、侦察巡逻、物流运输等领域。通过提高四足机器人的跳跃能力和运动鲁棒性,可以使其在更加复杂和恶劣的环境中执行任务,具有重要的实际应用价值和广阔的应用前景。未来,该方法可以进一步扩展到其他类型的运动控制任务中,例如攀爬、翻越障碍等。
📄 摘要(原文)
Jumping poses a significant challenge for quadruped robots, despite being crucial for many operational scenarios. While optimisation methods exist for controlling such motions, they are often time-consuming and demand extensive knowledge of robot and terrain parameters, making them less robust in real-world scenarios. Reinforcement learning (RL) is emerging as a viable alternative, yet conventional end-to-end approaches lack efficiency in terms of sample complexity, requiring extensive training in simulations, and predictability of the final motion, which makes it difficult to certify the safety of the final motion. To overcome these limitations, this paper introduces a novel guided reinforcement learning approach that leverages physical intuition for efficient and explainable jumping, by combining Bézier curves with a Uniformly Accelerated Rectilinear Motion (UARM) model. Extensive simulation and experimental results clearly demonstrate the advantages of our approach over existing alternatives.