GR-3 Technical Report
作者: Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, Yichu Yang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-07-21 (更新: 2025-07-22)
备注: Tech report. Authors are listed in alphabetical order. Project page: https://seed.bytedance.com/GR3/
💡 一句话要点
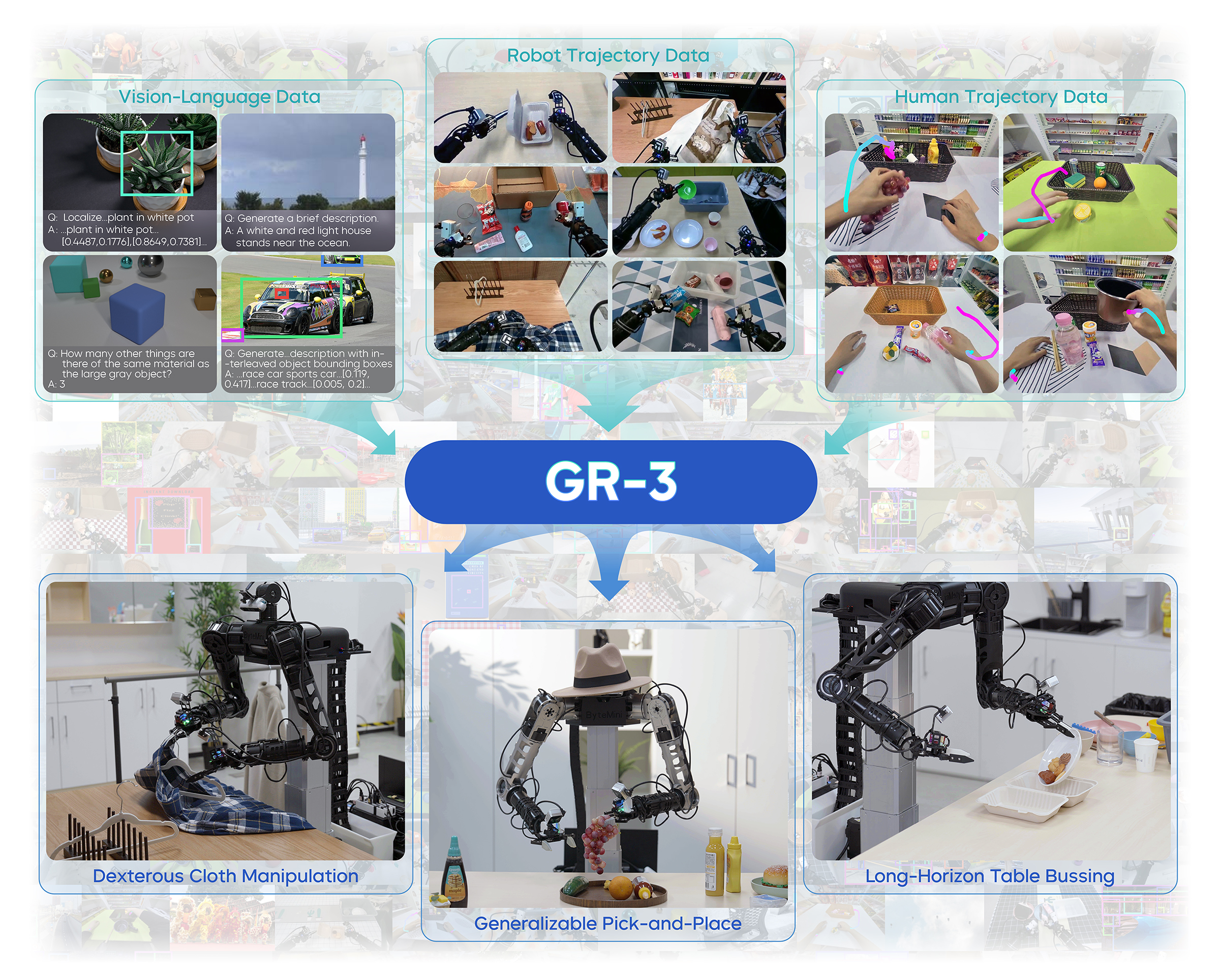
GR-3:基于大规模视觉-语言-动作模型的通用机器人策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 通用机器人 视觉-语言-动作模型 模仿学习 机器人控制 多模态学习
📋 核心要点
- 现有机器人策略在泛化性、适应性和处理复杂任务方面存在不足,难以应对真实世界的多样性。
- GR-3通过大规模VLA模型、协同训练、高效微调和模仿学习,提升了机器人策略的泛化能力和适应性。
- GR-3在真实世界实验中超越了现有基线方法,展示了其在长时程和灵巧任务上的强大性能。
📝 摘要(中文)
本文介绍了通用机器人策略GR-3的最新进展。GR-3是一个大规模视觉-语言-动作(VLA)模型,在泛化到新物体、环境和涉及抽象概念的指令方面表现出卓越的能力。此外,它可以通过最少的人工轨迹数据进行高效微调,从而能够快速且经济高效地适应新环境。GR-3还擅长处理长时程和灵巧的任务,包括需要双手操作和移动的任务,展现出强大而可靠的性能。这些能力是通过多方面的训练方法实现的,包括与网络规模的视觉-语言数据进行协同训练,通过VR设备收集的人工轨迹数据进行高效微调,以及通过机器人轨迹数据进行有效的模仿学习。此外,我们还介绍了一种多功能的双手移动机器人ByteMini,它具有出色的灵活性和可靠性,与GR-3集成后能够完成各种任务。通过广泛的真实世界实验,我们表明GR-3在各种具有挑战性的任务上超越了最先进的基线方法$π_0$。我们希望GR-3能够成为构建能够协助人类日常生活的通用机器人的垫脚石。
🔬 方法详解
问题定义:现有机器人策略难以泛化到新的物体、环境和指令,需要大量人工数据进行训练,并且在处理长时程和灵巧任务时表现不佳。痛点在于缺乏一个能够理解视觉、语言并执行复杂动作的通用模型。
核心思路:论文的核心思路是构建一个大规模的视觉-语言-动作(VLA)模型,通过多模态数据的联合训练,使机器人能够理解人类指令,并将其转化为具体的动作序列。通过模仿学习和微调,进一步提升模型的性能和适应性。
技术框架:GR-3的技术框架包含以下几个主要模块:1) 大规模VLA模型:用于理解视觉和语言信息,并生成相应的动作指令。2) 协同训练:利用网络规模的视觉-语言数据进行预训练,提升模型的泛化能力。3) 高效微调:使用少量人工轨迹数据进行微调,使模型能够快速适应新的环境和任务。4) 模仿学习:利用机器人轨迹数据进行训练,提升模型的动作执行能力。5) ByteMini机器人平台:一个灵活可靠的双手移动机器人,用于执行GR-3生成的动作指令。
关键创新:GR-3的关键创新在于其多方面的训练方法,包括:1) 与网络规模的视觉-语言数据进行协同训练,提升模型的泛化能力。2) 通过VR设备收集的人工轨迹数据进行高效微调,降低了数据收集成本。3) 利用机器人轨迹数据进行有效的模仿学习,提升了模型的动作执行能力。此外,ByteMini机器人的设计也提升了GR-3的实际应用能力。
关键设计:论文中提到使用网络规模的视觉-语言数据进行预训练,但未具体说明使用的网络结构、损失函数和训练细节。VR设备收集人工轨迹数据,具体收集方式和数据格式未知。机器人轨迹数据的模仿学习方法也未详细描述。ByteMini机器人的具体参数和结构设计也未知。
🖼️ 关键图片


📊 实验亮点
GR-3在各种具有挑战性的真实世界任务中超越了最先进的基线方法$π_0$,展示了其在泛化性、适应性和处理复杂任务方面的卓越性能。具体性能数据和提升幅度未在摘要中给出,需要查阅完整论文。
🎯 应用场景
GR-3具有广泛的应用前景,可应用于家庭服务、工业自动化、医疗辅助等领域。例如,它可以帮助老年人完成日常任务,在工厂中执行复杂的装配工作,或在医院中协助医生进行手术。该研究有望推动通用机器人的发展,使机器人能够更好地服务于人类社会。
📄 摘要(原文)
We report our recent progress towards building generalist robot policies, the development of GR-3. GR-3 is a large-scale vision-language-action (VLA) model. It showcases exceptional capabilities in generalizing to novel objects, environments, and instructions involving abstract concepts. Furthermore, it can be efficiently fine-tuned with minimal human trajectory data, enabling rapid and cost-effective adaptation to new settings. GR-3 also excels in handling long-horizon and dexterous tasks, including those requiring bi-manual manipulation and mobile movement, showcasing robust and reliable performance. These capabilities are achieved through a multi-faceted training recipe that includes co-training with web-scale vision-language data, efficient fine-tuning from human trajectory data collected via VR devices, and effective imitation learning with robot trajectory data. In addition, we introduce ByteMini, a versatile bi-manual mobile robot designed with exceptional flexibility and reliability, capable of accomplishing a wide range of tasks when integrated with GR-3. Through extensive real-world experiments, we show GR-3 surpasses the state-of-the-art baseline method, $π_0$, on a wide variety of challenging tasks. We hope GR-3 can serve as a step towards building generalist robots capable of assisting humans in daily life.