ERR@HRI 2.0 Challenge: Multimodal Detection of Errors and Failures in Human-Robot Conversations
作者: Shiye Cao, Maia Stiber, Amama Mahmood, Maria Teresa Parreira, Wendy Ju, Micol Spitale, Hatice Gunes, Chien-Ming Huang
分类: cs.RO, cs.AI, cs.HC
发布日期: 2025-07-17 (更新: 2025-10-09)
💡 一句话要点
ERR@HRI 2.0挑战赛:多模态检测人机对话中的错误与失败
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 多模态数据 错误检测 大型语言模型 对话机器人
📋 核心要点
- 大型语言模型驱动的对话机器人易出错,如误解意图、过早打断等,影响用户体验和任务完成。
- ERR@HRI 2.0挑战赛提供多模态数据集,包含人机交互中的面部、语音和头部运动特征,用于训练模型。
- 挑战赛鼓励研究者开发机器学习模型,利用多模态数据检测机器人失败,并使用多种指标评估模型性能。
📝 摘要(中文)
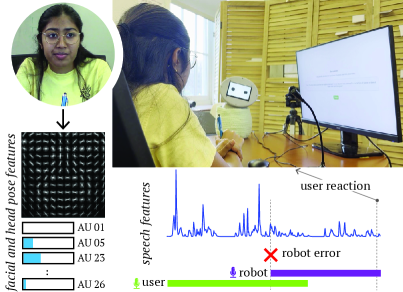
ERR@HRI 2.0挑战赛旨在解决将大型语言模型(LLM)集成到对话机器人中后,机器人容易出现错误的问题。这些错误包括误解用户意图、过早打断用户或完全无法响应。检测和解决这些失败对于防止对话中断、避免任务中断和维持用户信任至关重要。该挑战赛提供了一个多模态数据集,其中包含LLM驱动的对话机器人在人机对话中出现的失败案例,并鼓励研究人员对用于检测机器人失败的机器学习模型进行基准测试。数据集包含16小时的二元人机交互,包括面部、语音和头部运动特征。每次交互都标注了系统角度的机器人错误以及用户纠正机器人行为与用户期望不符的意图。参赛者可以组队开发机器学习模型,利用多模态数据检测这些失败。提交的模型将使用各种性能指标进行评估,包括检测准确率和假阳性率。该挑战赛是利用社会信号分析改进人机交互中失败检测的关键一步。
🔬 方法详解
问题定义:论文旨在解决人机对话中,由大型语言模型驱动的对话机器人出现的各种错误和失败,例如误解用户意图、过早打断用户、无法响应等。现有方法难以有效检测这些错误,导致对话中断、任务失败和用户信任度下降。
核心思路:论文的核心思路是利用多模态数据(包括面部表情、语音和头部运动)来检测人机对话中的机器人失败。通过分析这些社会信号,可以更准确地判断机器人是否出现了错误,以及用户是否试图纠正这些错误。
技术框架:ERR@HRI 2.0挑战赛提供了一个包含16小时人机交互的多模态数据集。该数据集包含面部、语音和头部运动特征,并标注了机器人错误和用户纠正意图。参赛者需要利用该数据集训练机器学习模型,用于检测机器人失败。评估指标包括检测准确率和假阳性率。
关键创新:该研究的关键创新在于利用多模态数据进行机器人失败检测。传统的错误检测方法主要依赖于文本分析,而忽略了非语言交流信号。通过融合面部表情、语音和头部运动等信息,可以更全面地理解人机交互过程,从而提高错误检测的准确性。
关键设计:数据集包含16小时的二元人机交互数据,涵盖多种场景和用户。标注信息包括系统角度的机器人错误和用户纠正意图。挑战赛鼓励参赛者探索各种机器学习模型,包括但不限于深度学习模型,并优化模型参数以提高检测性能。具体的损失函数和网络结构由参赛者自行设计。
🖼️ 关键图片
📊 实验亮点
ERR@HRI 2.0挑战赛提供了一个大规模多模态数据集,为机器人失败检测研究提供了宝贵的资源。通过该挑战赛,研究人员可以比较不同机器学习模型在机器人失败检测任务上的性能,并推动该领域的发展。具体的性能数据和对比基线将在挑战赛结束后公布。
🎯 应用场景
该研究成果可应用于各种人机交互场景,例如智能客服、教育机器人、医疗辅助机器人等。通过提高机器人错误检测的准确性,可以改善用户体验,提高任务完成效率,并增强用户对机器人的信任。未来,该技术有望应用于更复杂的机器人系统,例如自动驾驶汽车和智能家居。
📄 摘要(原文)
The integration of large language models (LLMs) into conversational robots has made human-robot conversations more dynamic. Yet, LLM-powered conversational robots remain prone to errors, e.g., misunderstanding user intent, prematurely interrupting users, or failing to respond altogether. Detecting and addressing these failures is critical for preventing conversational breakdowns, avoiding task disruptions, and sustaining user trust. To tackle this problem, the ERR@HRI 2.0 Challenge provides a multimodal dataset of LLM-powered conversational robot failures during human-robot conversations and encourages researchers to benchmark machine learning models designed to detect robot failures. The dataset includes 16 hours of dyadic human-robot interactions, incorporating facial, speech, and head movement features. Each interaction is annotated with the presence or absence of robot errors from the system perspective, and perceived user intention to correct for a mismatch between robot behavior and user expectation. Participants are invited to form teams and develop machine learning models that detect these failures using multimodal data. Submissions will be evaluated using various performance metrics, including detection accuracy and false positive rate. This challenge represents another key step toward improving failure detection in human-robot interaction through social signal analysis.