Latent Policy Steering with Embodiment-Agnostic Pretrained World Models
作者: Yiqi Wang, Mrinal Verghese, Jeff Schneider
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-07-17 (更新: 2025-09-21)
💡 一句话要点
提出基于具身无关预训练世界模型的潜在策略引导方法,提升机器人模仿学习效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 模仿学习 世界模型 具身智能 策略引导 光流 多模态学习
📋 核心要点
- 现有模仿学习方法依赖大量真实世界数据,数据收集成本高昂,限制了其应用。
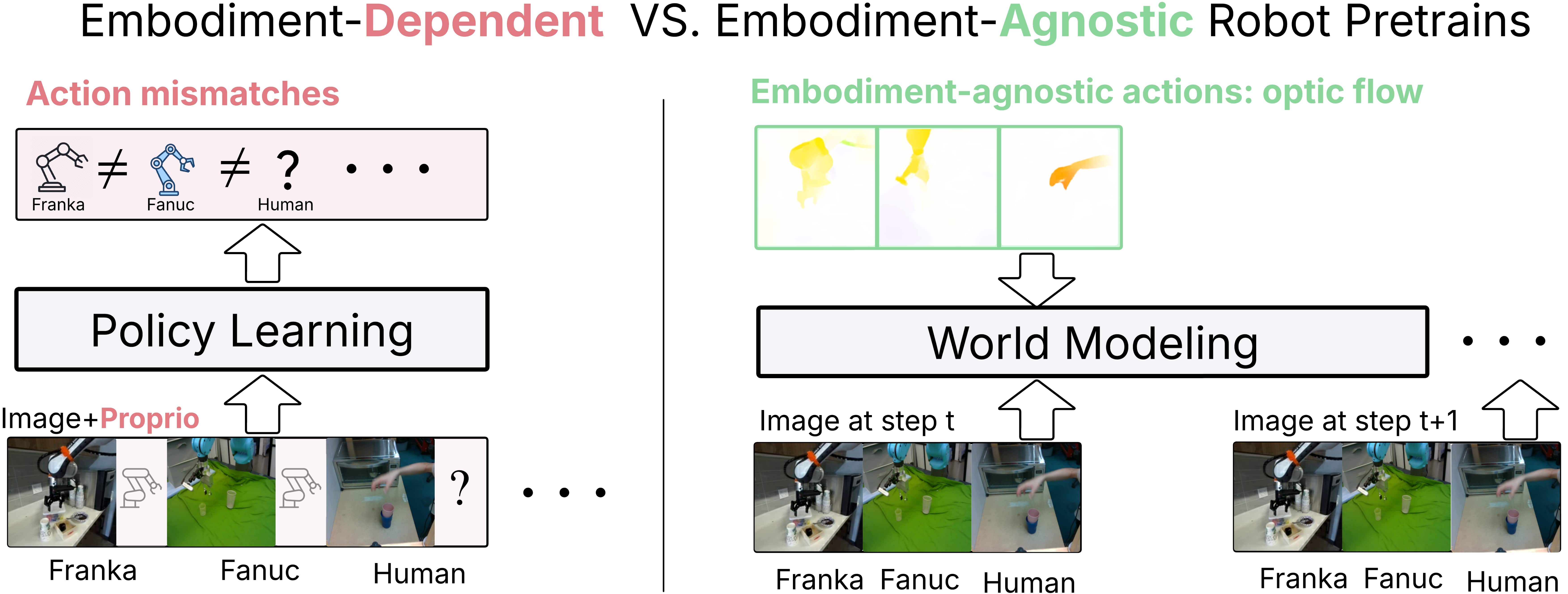
- 利用光流作为具身无关的动作表示,结合预训练世界模型和潜在策略引导,提升策略性能。
- 实验表明,该方法在少量数据下显著提升了机器人策略性能,降低了数据收集需求。
📝 摘要(中文)
本文旨在通过利用来自多种具身的数据(如公共机器人数据集和人类玩耍数据),减少学习机器人视觉运动策略时的数据收集工作。该方法基于两个关键思想:首先,使用光流作为具身无关的动作表示,在多具身数据集上训练世界模型(WM),并在目标具身的一小部分机器人数据上进行微调。其次,开发了一种潜在策略引导(LPS)方法,通过在WM的潜在空间中搜索更好的动作序列来改进行为克隆策略的输出。在真实世界的实验中,通过将策略与在来自不同机器人的现有Open X-embodiment数据集或经济高效的人类玩耍数据集中抽样的两千个episode上预训练的WM相结合,观察到使用少量数据训练的策略性能显著提高(使用30个demonstration时相对改进超过50%,使用50个demonstration时相对改进超过20%)。
🔬 方法详解
问题定义:现有基于模仿学习的机器人视觉运动策略训练,严重依赖于大量真实世界的数据,而这些数据的收集往往成本高昂,限制了策略的泛化能力和实际应用。尤其是在新的机器人平台上,从零开始收集大量数据是不现实的。因此,如何利用已有的、来自不同具身(embodiment)的数据,例如其他机器人平台或人类操作的数据,来提升新机器人的策略学习效率,是一个亟待解决的问题。
核心思路:本文的核心思路是利用具身无关的动作表示(光流)来训练一个通用的世界模型(World Model, WM),该模型能够理解不同具身之间的共性。然后,利用少量目标具身的数据对WM进行微调,使其适应特定任务。最后,通过在WM的潜在空间中搜索更优的动作序列,来引导(Steering)行为克隆策略,从而提升策略的性能。这种方法的核心在于利用预训练的WM来提供先验知识,减少对目标具身数据的依赖。
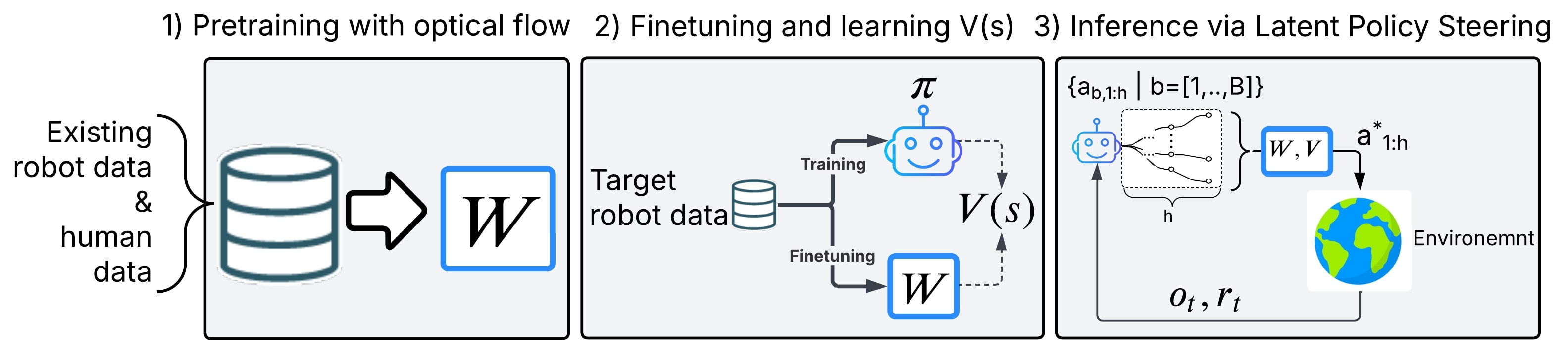
技术框架:该方法主要包含以下几个阶段: 1. 多具身数据收集:收集来自不同机器人平台或人类操作的数据,这些数据包含视觉输入和对应的动作。 2. 具身无关的世界模型训练:使用光流作为动作表示,在多具身数据集上训练一个世界模型。该模型学习从视觉输入预测未来的状态和奖励。 3. 目标具身数据微调:使用少量目标具身的数据对预训练的WM进行微调,使其适应特定任务。 4. 行为克隆策略训练:使用目标具身的数据训练一个行为克隆策略,该策略将视觉输入映射到动作。 5. 潜在策略引导:在WM的潜在空间中搜索更优的动作序列,并利用这些动作序列来引导行为克隆策略的输出。
关键创新:该方法最重要的技术创新点在于提出了“潜在策略引导”(Latent Policy Steering, LPS)的概念。LPS通过在世界模型的潜在空间中搜索更优的动作序列,来改进行为克隆策略的输出。与传统的行为克隆方法相比,LPS能够利用世界模型提供的先验知识,从而在少量数据下获得更好的性能。此外,使用光流作为具身无关的动作表示,使得WM能够跨不同的具身进行训练,进一步提升了数据的利用率。
关键设计: * 光流作为动作表示:使用光流作为动作表示,可以消除不同具身之间的动作空间差异,使得WM能够跨不同的具身进行训练。 * 世界模型结构:世界模型通常采用变分自编码器(VAE)或Transformer结构,用于学习视觉输入的潜在表示和预测未来的状态和奖励。 * 潜在策略引导算法:LPS算法通常采用优化算法(如CEM或进化策略)在WM的潜在空间中搜索更优的动作序列。 * 损失函数:损失函数通常包含重构损失、预测损失和奖励预测损失,用于训练WM和行为克隆策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在真实机器人环境中,使用少量数据(30个demonstration)训练的策略性能相对提升超过50%,使用50个demonstration时相对提升超过20%。这些结果表明,通过结合预训练的世界模型和潜在策略引导,可以显著降低机器人策略学习的数据需求,提升策略的泛化能力。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、游戏AI等领域。通过利用已有的多源数据,可以显著降低新机器人或新任务的数据收集成本,加速机器人技术的落地应用。例如,可以利用人类操作数据训练机器人完成家务任务,或利用其他车辆的驾驶数据训练自动驾驶系统。此外,该方法还可以用于机器人技能迁移和终身学习,使得机器人能够不断学习新的技能并适应新的环境。
📄 摘要(原文)
Learning visuomotor policies via imitation has proven effective across a wide range of robotic domains. However, the performance of these policies is heavily dependent on the number of training demonstrations, which requires expensive data collection in the real world. In this work, we aim to reduce data collection efforts when learning visuomotor robot policies by leveraging existing or cost-effective data from a wide range of embodiments, such as public robot datasets and the datasets of humans playing with objects (human data from play). Our approach leverages two key insights. First, we use optic flow as an embodiment-agnostic action representation to train a World Model (WM) across multi-embodiment datasets, and finetune it on a small amount of robot data from the target embodiment. Second, we develop a method, Latent Policy Steering (LPS), to improve the output of a behavior-cloned policy by searching in the latent space of the WM for better action sequences. In real world experiments, we observe significant improvements in the performance of policies trained with a small amount of data (over 50% relative improvement with 30 demonstrations and over 20% relative improvement with 50 demonstrations) by combining the policy with a WM pretrained on two thousand episodes sampled from the existing Open X-embodiment dataset across different robots or a cost-effective human dataset from play.