LLM-based ambiguity detection in natural language instructions for collaborative surgical robots
作者: Ana Davila, Jacinto Colan, Yasuhisa Hasegawa
分类: cs.RO, cs.HC
发布日期: 2025-07-15
备注: Accepted at 2025 IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
期刊: 2025 IEEE International Conference on Robot and Human Interactive Communication (ROMAN)
💡 一句话要点
提出基于LLM的歧义检测框架,用于提升协作手术机器人自然语言指令的安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 人机交互 协作机器人 大型语言模型 歧义检测
📋 核心要点
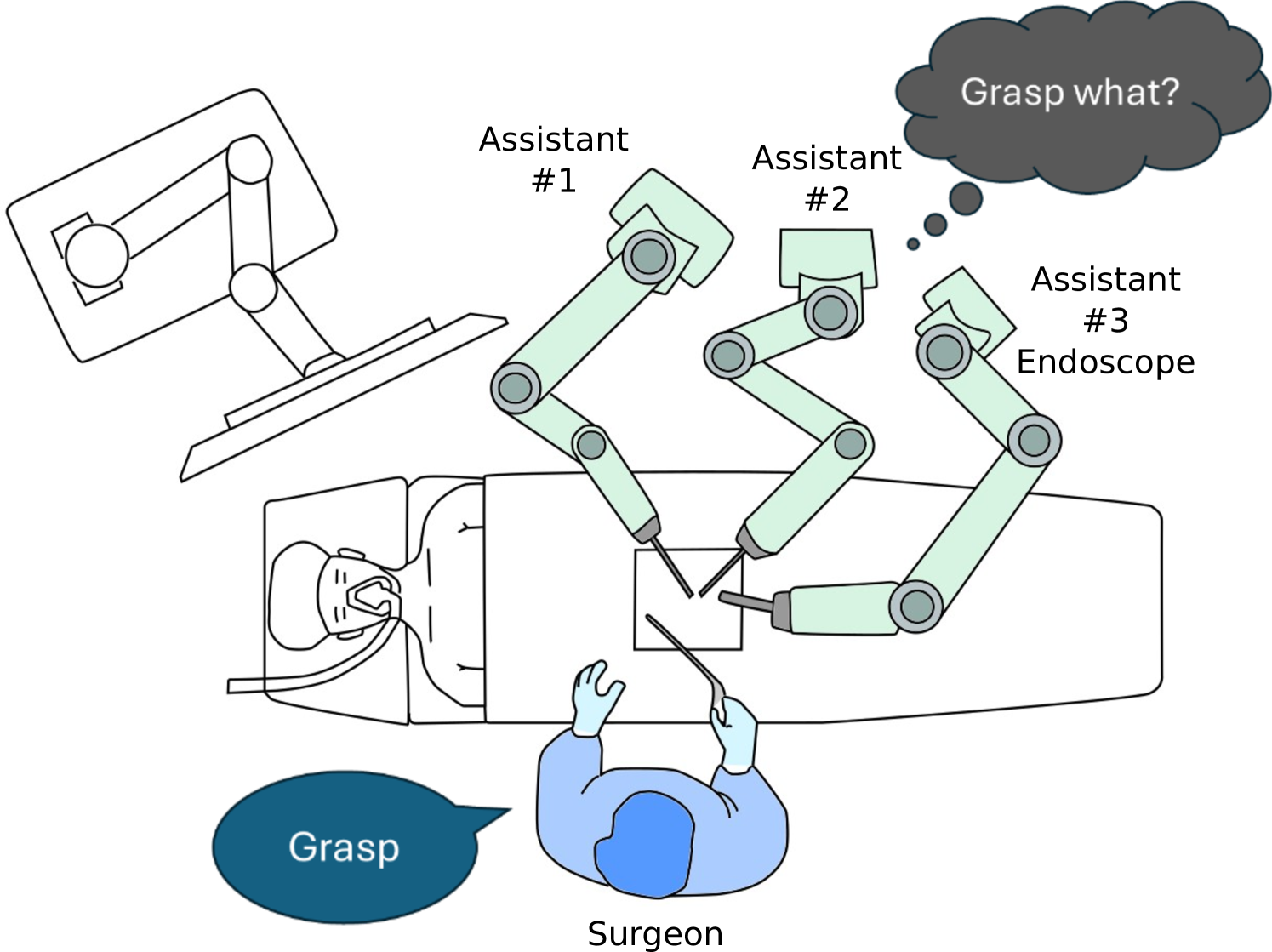
- 自然语言指令中的歧义性对安全至关重要的人机交互构成风险,尤其是在手术等领域,现有方法难以有效识别这些歧义。
- 本研究提出一种基于LLM的歧义检测框架,通过集成多个LLM评估器并结合保角预测,全面评估指令的潜在歧义。
- 实验结果表明,该方法在区分模糊和非模糊手术指令方面,分类准确率超过60%,显著提升了人机协作的安全性。
📝 摘要(中文)
本研究提出了一种基于大型语言模型(LLM)的歧义检测框架,专门用于协作手术场景,旨在解决自然语言指令中的歧义问题,该问题在安全攸关的人机交互中构成重大风险。该方法采用LLM评估器集成,每个评估器配置不同的提示技术,以识别语言、上下文、程序和关键歧义。其中包含一个思维链评估器,用于系统地分析指令结构中潜在的问题。通过保角预测综合各个评估器的评估结果,基于与标记的校准数据集的比较,产生非一致性分数。对Llama 3.2 11B和Gemma 3 12B的评估表明,在区分模糊和非模糊手术指令方面,分类准确率超过60%。该方法通过提供一种在机器人执行动作之前识别潜在歧义指令的机制,提高了手术中人机协作的安全性和可靠性。
🔬 方法详解
问题定义:论文旨在解决协作手术机器人场景下,自然语言指令中存在的歧义性问题。现有方法难以有效识别指令中的语言歧义、上下文歧义、程序歧义和关键歧义,这可能导致机器人执行错误操作,对患者安全构成威胁。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解能力,构建一个集成的歧义检测框架。通过设计不同的提示策略,引导LLM从多个角度评估指令的歧义性,并利用保角预测方法综合各个评估器的结果,从而提高歧义检测的准确性和可靠性。
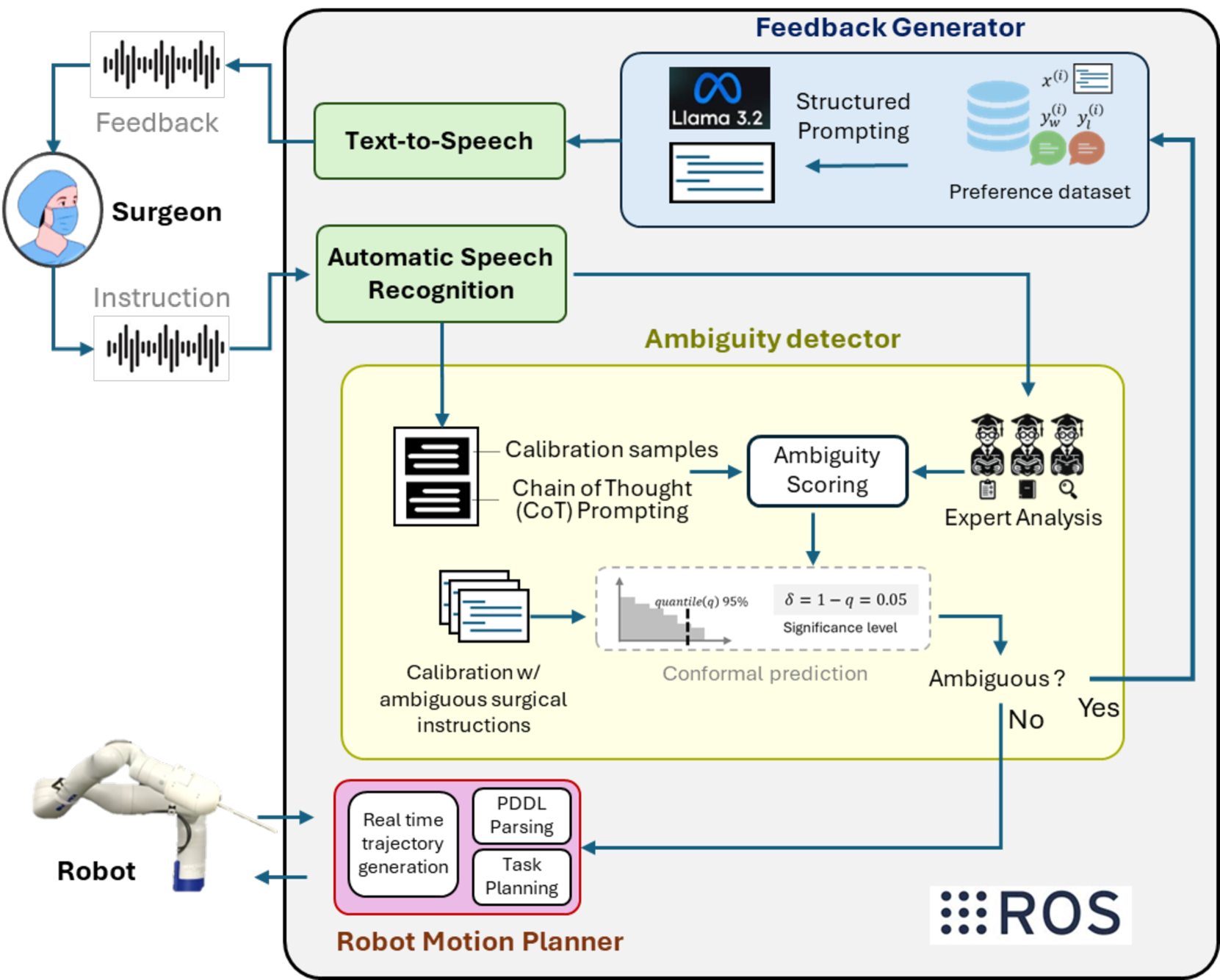
技术框架:该框架包含以下主要模块:1) LLM评估器集成:使用多个LLM评估器,每个评估器采用不同的提示技术,分别针对语言歧义、上下文歧义、程序歧义和关键歧义进行评估。2) 思维链评估器:采用思维链(Chain-of-Thought)方法,系统地分析指令结构,识别潜在的问题。3) 保角预测:利用保角预测方法,将各个评估器的评估结果进行综合,生成非一致性分数,用于判断指令是否存在歧义。
关键创新:该方法的主要创新点在于:1) 提出了一种基于LLM集成的歧义检测框架,能够全面评估指令的多种歧义性。2) 采用了保角预测方法,能够有效地综合各个评估器的结果,提高歧义检测的准确性和鲁棒性。3) 针对手术场景,设计了特定的提示策略和评估指标,提高了方法的实用性。
关键设计:论文中,LLM评估器使用了不同的提示策略,例如,针对语言歧义,可以使用“这个指令是否有多种解释?”等提示语;针对上下文歧义,可以使用“这个指令是否依赖于特定的手术步骤或患者状态?”等提示语。保角预测方法使用了一个标记的校准数据集,用于计算非一致性分数。具体LLM选择Llama 3.2 11B和Gemma 3 12B,并使用分类准确率作为评估指标。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在区分模糊和非模糊手术指令方面,分类准确率超过60%。通过集成多个LLM评估器和采用保角预测方法,该方法能够有效地识别指令中的多种歧义,并显著提高歧义检测的准确性和鲁棒性。Llama 3.2 11B和Gemma 3 12B模型均取得了较好的性能。
🎯 应用场景
该研究成果可应用于各种人机协作场景,尤其是在医疗、制造和航空航天等安全攸关领域。通过在机器人执行指令前检测潜在的歧义,可以显著提高人机协作的安全性、可靠性和效率,减少人为错误和事故的发生。未来,该技术有望与机器人控制系统集成,实现自主的歧义检测和纠正。
📄 摘要(原文)
Ambiguity in natural language instructions poses significant risks in safety-critical human-robot interaction, particularly in domains such as surgery. To address this, we propose a framework that uses Large Language Models (LLMs) for ambiguity detection specifically designed for collaborative surgical scenarios. Our method employs an ensemble of LLM evaluators, each configured with distinct prompting techniques to identify linguistic, contextual, procedural, and critical ambiguities. A chain-of-thought evaluator is included to systematically analyze instruction structure for potential issues. Individual evaluator assessments are synthesized through conformal prediction, which yields non-conformity scores based on comparison to a labeled calibration dataset. Evaluating Llama 3.2 11B and Gemma 3 12B, we observed classification accuracy exceeding 60% in differentiating ambiguous from unambiguous surgical instructions. Our approach improves the safety and reliability of human-robot collaboration in surgery by offering a mechanism to identify potentially ambiguous instructions before robot action.