Vision Language Action Models in Robotic Manipulation: A Systematic Review
作者: Muhayy Ud Din, Waseem Akram, Lyes Saad Saoud, Jan Rosell, Irfan Hussain
分类: cs.RO, cs.CV
发布日期: 2025-07-14
备注: submitted to annual review in control
💡 一句话要点
系统性综述:机器人操作中的视觉语言动作模型研究进展
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 指令驱动自主性 数据集评估 仿真环境 多模态学习 具身智能
📋 核心要点
- 现有机器人操作方法在视觉感知、语言理解和动作控制的统一学习方面存在不足,难以实现指令驱动的自主性。
- 论文对视觉语言动作(VLA)模型进行系统性综述,分析了其在机器人操作中的应用,并提出了未来发展方向。
- 通过对大量VLA模型、数据集和仿真平台的分析,论文为通用机器人代理的开发提供了技术参考和概念路线图。
📝 摘要(中文)
视觉语言动作(VLA)模型代表了机器人领域的变革性转变,旨在将视觉感知、自然语言理解和具身控制统一在一个单一的学习框架内。本综述全面且前瞻性地总结了VLA范式,特别强调了机器人操作和指令驱动的自主性。我们全面分析了102个VLA模型、26个基础数据集和12个仿真平台,这些共同塑造了VLA模型的发展和评估。这些模型被分为关键的架构范式,每种范式都反映了在机器人系统中集成视觉、语言和控制的不同策略。基础数据集使用基于任务复杂性、模态多样性和数据集规模的新标准进行评估,从而可以对它们在通用策略学习中的适用性进行比较分析。我们引入了一个二维表征框架,该框架根据语义丰富性和多模态对齐来组织这些数据集,展示了当前数据格局中未被充分探索的区域。仿真环境因其生成大规模数据的有效性、促进从仿真到真实世界环境的迁移以及支持的各种任务而受到评估。通过学术界和工业界的贡献,我们认识到当前面临的挑战,并概述了战略方向,例如可扩展的预训练协议、模块化架构设计和强大的多模态对齐策略。本综述既是技术参考,又是推进具身和机器人控制的概念路线图,提供的见解涵盖从数据集生成到通用机器人代理的实际部署。
🔬 方法详解
问题定义:现有机器人操作方法通常依赖于独立的视觉感知、语言理解和动作控制模块,难以实现端到端的学习和指令驱动的自主性。此外,数据集的规模、模态多样性和语义丰富性也限制了VLA模型的发展。
核心思路:本综述的核心思路是对现有的VLA模型、数据集和仿真平台进行系统性的分析和评估,从而识别出当前研究的挑战和未来的发展方向。通过对不同架构范式、数据集特征和仿真环境的比较,为研究人员提供有价值的参考。
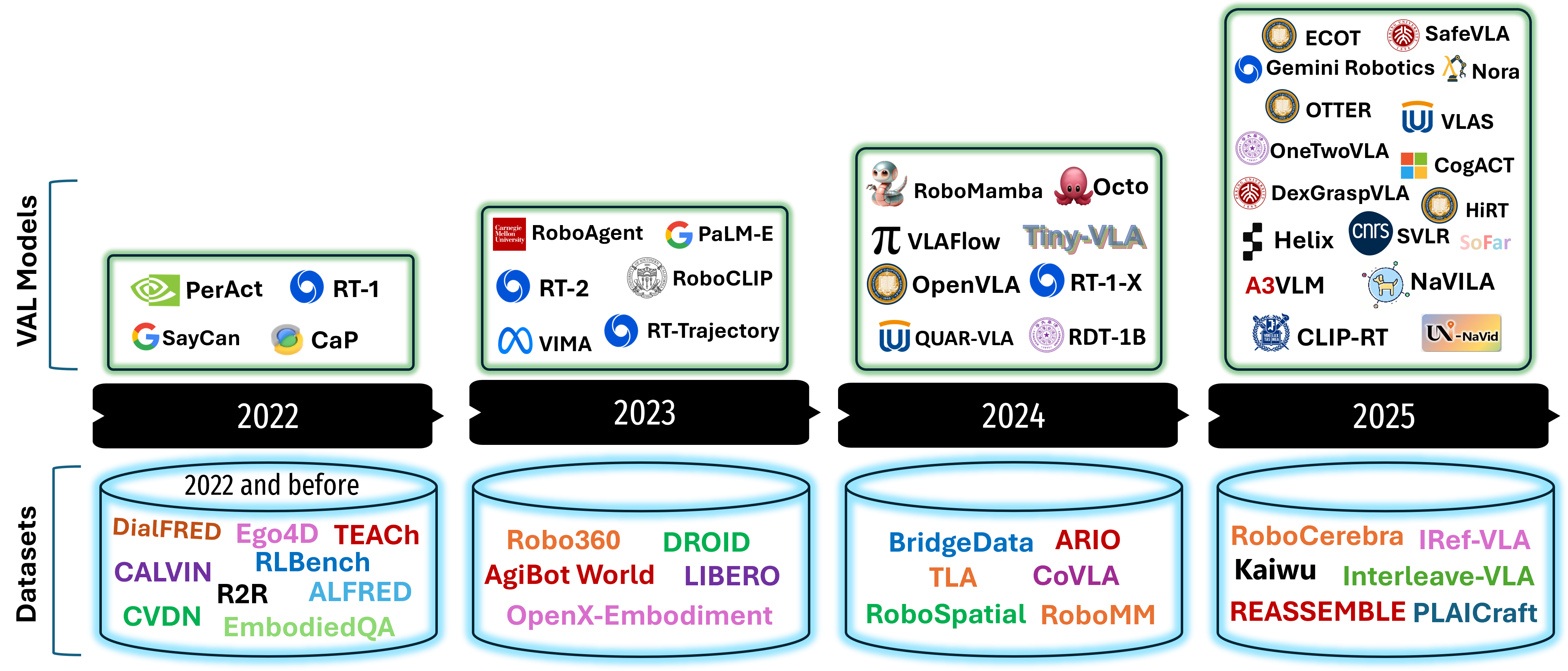
技术框架:该综述没有提出新的模型或算法,而是构建了一个全面的分析框架。该框架包括:1) 对102个VLA模型进行分类,按照架构范式进行组织;2) 使用新的标准评估26个基础数据集,包括任务复杂性、模态多样性和数据集规模;3) 引入二维表征框架,根据语义丰富性和多模态对齐来组织数据集;4) 评估12个仿真环境,关注其生成大规模数据、促进仿真到真实世界迁移的能力。
关键创新:该综述的创新之处在于其系统性和全面性。它不仅对现有的VLA模型进行了分类和评估,还提出了新的数据集评估标准和表征框架。此外,该综述还识别了当前研究的挑战,并提出了未来的发展方向,例如可扩展的预训练协议、模块化架构设计和强大的多模态对齐策略。
关键设计:该综述的关键设计在于其评估标准和表征框架。数据集的评估标准包括任务复杂性、模态多样性和数据集规模,这些指标能够有效地衡量数据集的质量和适用性。二维表征框架根据语义丰富性和多模态对齐来组织数据集,从而能够识别出当前数据格局中未被充分探索的区域。
🖼️ 关键图片
📊 实验亮点
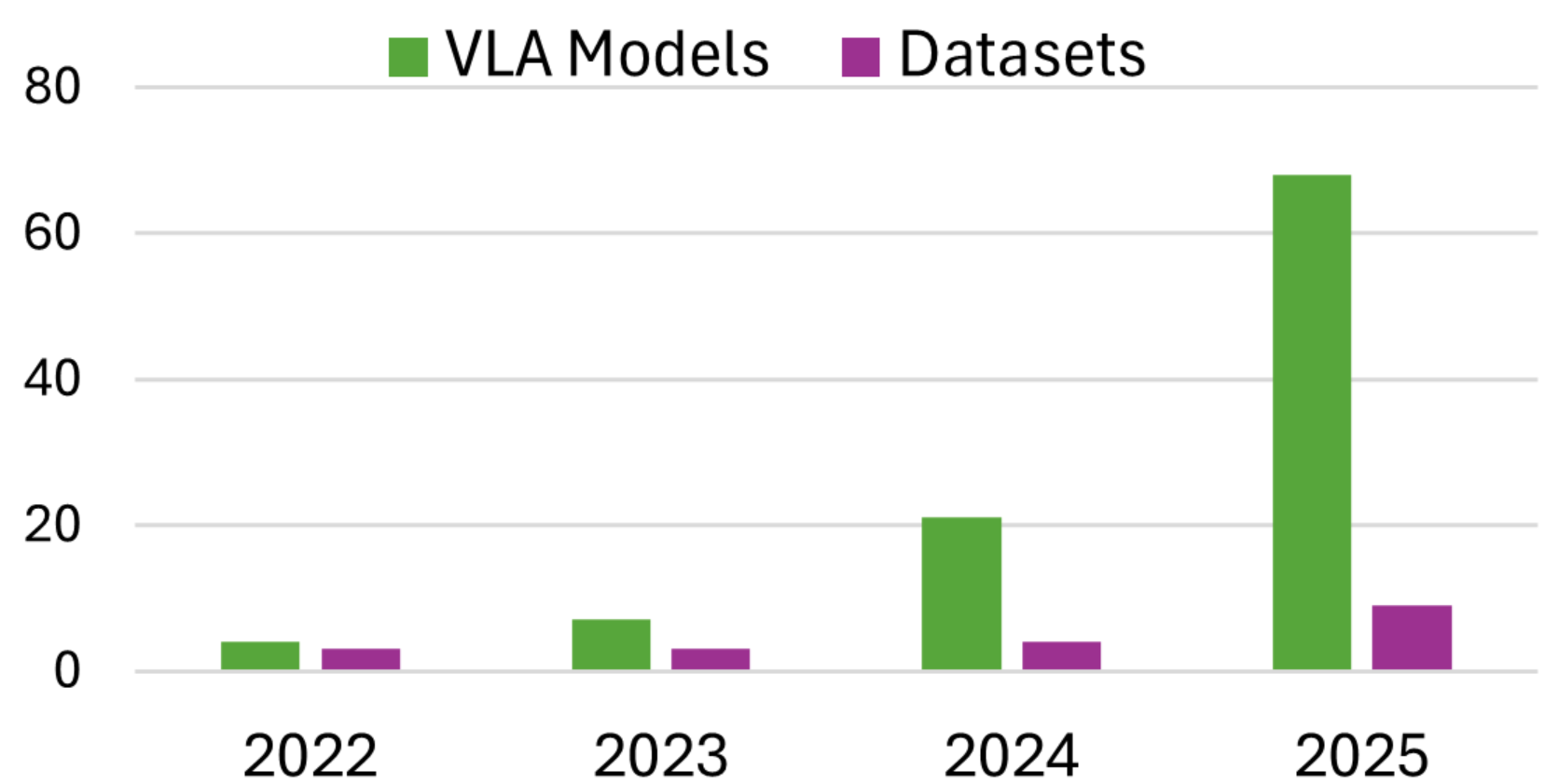
该综述分析了102个VLA模型,26个数据集和12个仿真平台,并提出了新的数据集评估标准和表征框架。这些分析为VLA模型的研究提供了全面的参考,并为未来的发展方向提供了指导。通过对现有方法的优缺点进行分析,该综述为研究人员提供了有价值的见解。
🎯 应用场景
该研究成果可应用于各种机器人操作场景,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过VLA模型,机器人可以理解人类的指令,并执行复杂的任务,从而提高工作效率和生活质量。未来,VLA模型有望实现通用机器人代理,使其能够适应各种环境和任务。
📄 摘要(原文)
Vision Language Action (VLA) models represent a transformative shift in robotics, with the aim of unifying visual perception, natural language understanding, and embodied control within a single learning framework. This review presents a comprehensive and forward-looking synthesis of the VLA paradigm, with a particular emphasis on robotic manipulation and instruction-driven autonomy. We comprehensively analyze 102 VLA models, 26 foundational datasets, and 12 simulation platforms that collectively shape the development and evaluation of VLAs models. These models are categorized into key architectural paradigms, each reflecting distinct strategies for integrating vision, language, and control in robotic systems. Foundational datasets are evaluated using a novel criterion based on task complexity, variety of modalities, and dataset scale, allowing a comparative analysis of their suitability for generalist policy learning. We introduce a two-dimensional characterization framework that organizes these datasets based on semantic richness and multimodal alignment, showing underexplored regions in the current data landscape. Simulation environments are evaluated for their effectiveness in generating large-scale data, as well as their ability to facilitate transfer from simulation to real-world settings and the variety of supported tasks. Using both academic and industrial contributions, we recognize ongoing challenges and outline strategic directions such as scalable pretraining protocols, modular architectural design, and robust multimodal alignment strategies. This review serves as both a technical reference and a conceptual roadmap for advancing embodiment and robotic control, providing insights that span from dataset generation to real world deployment of generalist robotic agents.