Constrained Style Learning from Imperfect Demonstrations under Task Optimality
作者: Kehan Wen, Chenhao Li, Junzhe He, Marco Hutter
分类: cs.RO
发布日期: 2025-07-12 (更新: 2025-09-23)
备注: This paper has been accepted to CoRL 2025
💡 一句话要点
提出基于约束马尔可夫决策过程的模仿学习方法,提升机器人任务性能与风格
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模仿学习 约束马尔可夫决策过程 机器人控制 风格学习 任务性能 拉格朗日乘数 四足机器人
📋 核心要点
- 现有模仿学习方法依赖高质量专家演示,但实际演示常不完整,导致任务性能下降。
- 提出基于约束马尔可夫决策过程(CMDP)的模仿学习框架,在保持任务性能的同时学习风格。
- 实验表明,该方法在多个机器人平台上实现了鲁棒的任务性能和高保真度的风格学习,例如ANYmal-D机械能降低14.5%。
📝 摘要(中文)
本文提出了一种从不完美演示中学习风格化运动的方法,该方法在机器人领域中学习自然行为(如风格化运动和逼真的敏捷性)非常有效,尤其是在难以明确定义面向风格的奖励函数时。为现实世界的任务合成风格化运动通常需要在任务性能和模仿质量之间取得平衡。现有方法通常依赖于与任务目标紧密结合的专家演示。然而,实际演示通常是不完整或不真实的,导致当前方法以牺牲任务性能为代价来提升风格。为了解决这个问题,我们提出将该问题建模为约束马尔可夫决策过程(CMDP)。具体来说,我们优化了一个风格模仿目标,并使用约束来维持接近最优的任务性能。我们引入了一个自适应可调的拉格朗日乘数,以引导智能体有选择地模仿演示,从而在不影响任务性能的情况下捕捉风格细微之处。我们在多个机器人平台和任务上验证了我们的方法,证明了鲁棒的任务性能和高保真度的风格学习。在ANYmal-D硬件上,我们展示了机械能下降14.5%和更灵活的步态模式,展示了现实世界的好处。
🔬 方法详解
问题定义:现有模仿学习方法在处理不完美的演示数据时,往往难以兼顾任务性能和风格模仿。当演示数据质量不高,例如包含次优行为或与任务目标不完全一致时,直接模仿会导致任务性能下降。因此,如何在不牺牲任务性能的前提下,从不完美的演示中学习到期望的风格,是一个亟待解决的问题。
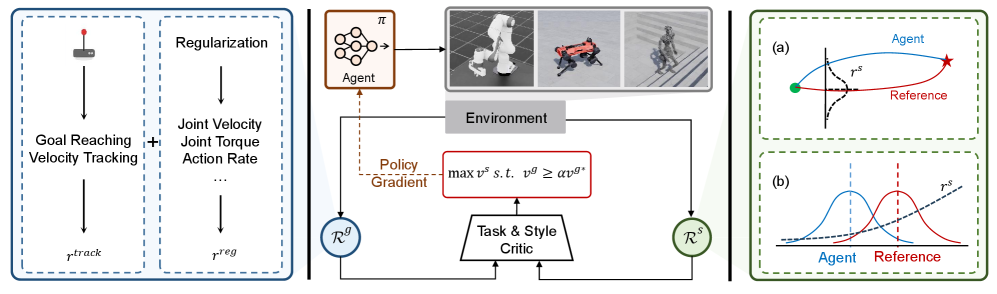
核心思路:本文的核心思路是将风格模仿学习问题建模为一个约束马尔可夫决策过程(CMDP)。通过引入约束,确保智能体在学习风格的同时,维持接近最优的任务性能。这种方法允许智能体有选择地模仿演示,避免盲目模仿可能导致的任务性能损失。
技术框架:该方法的核心框架包括以下几个关键模块:1)任务奖励函数:用于评估智能体在执行任务时的性能;2)风格模仿目标:用于衡量智能体与演示数据在风格上的相似度;3)约束条件:用于保证智能体的任务性能不低于某个阈值;4)自适应拉格朗日乘数:用于平衡风格模仿目标和任务性能约束。整体流程是,智能体通过与环境交互,根据任务奖励和风格模仿目标进行学习,同时受到任务性能约束的限制。自适应拉格朗日乘数会根据约束的满足情况进行调整,从而引导智能体在风格模仿和任务性能之间找到最佳平衡。
关键创新:该方法最重要的创新点在于将风格模仿学习问题建模为CMDP,并引入自适应拉格朗日乘数来动态平衡风格模仿和任务性能。与传统的模仿学习方法相比,该方法能够更好地处理不完美的演示数据,在保证任务性能的同时学习到期望的风格。自适应拉格朗日乘数的设计使得智能体能够根据实际情况调整模仿策略,避免盲目模仿带来的负面影响。
关键设计:关键设计包括:1)任务性能约束的设定,需要根据具体任务进行调整,以保证智能体能够达到可接受的任务性能水平;2)风格模仿目标的定义,可以使用各种距离度量方法,例如动态时间规整(DTW)或神经网络嵌入;3)自适应拉格朗日乘数的更新策略,需要根据约束的满足情况进行调整,以保证约束能够得到有效执行。具体而言,如果任务性能低于约束阈值,则增加拉格朗日乘数,以加强对任务性能的约束;反之,则减小拉格朗日乘数,以允许智能体更自由地模仿风格。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个机器人平台上实现了鲁棒的任务性能和高保真度的风格学习。在ANYmal-D硬件平台上,该方法能够使机器人机械能降低14.5%,并呈现出更灵活的步态模式。这些结果表明,该方法能够有效地从不完美的演示中学习风格,并在保证任务性能的同时,提升机器人的运动能力。
🎯 应用场景
该研究成果可广泛应用于机器人控制领域,例如四足机器人运动控制、人形机器人动作生成、以及其他需要模仿学习的场景。通过从不完美的演示中学习,可以降低对演示数据质量的要求,提高机器人学习效率和泛化能力。该方法在康复机器人、服务机器人等领域具有潜在应用价值,可以帮助机器人学习更加自然、流畅的动作,提升用户体验。
📄 摘要(原文)
Learning from demonstration has proven effective in robotics for acquiring natural behaviors, such as stylistic motions and lifelike agility, particularly when explicitly defining style-oriented reward functions is challenging. Synthesizing stylistic motions for real-world tasks usually requires balancing task performance and imitation quality. Existing methods generally depend on expert demonstrations closely aligned with task objectives. However, practical demonstrations are often incomplete or unrealistic, causing current methods to boost style at the expense of task performance. To address this issue, we propose formulating the problem as a constrained Markov Decision Process (CMDP). Specifically, we optimize a style-imitation objective with constraints to maintain near-optimal task performance. We introduce an adaptively adjustable Lagrangian multiplier to guide the agent to imitate demonstrations selectively, capturing stylistic nuances without compromising task performance. We validate our approach across multiple robotic platforms and tasks, demonstrating both robust task performance and high-fidelity style learning. On ANYmal-D hardware we show a 14.5% drop in mechanical energy and a more agile gait pattern, showcasing real-world benefits.