Keep on Going: Learning Robust Humanoid Motion Skills via Selective Adversarial Training
作者: Yang Zhang, Zhanxiang Cao, Buqing Nie, Haoyang Li, Zhong Jiangwei, Qiao Sun, Xiaoyi Hu, Xiaokang Yang, Yue Gao
分类: cs.RO
发布日期: 2025-07-11 (更新: 2025-11-13)
备注: 13 pages, 10 figures, AAAI2026
💡 一句话要点
提出选择性对抗训练(SA2RT),提升人形机器人长时程运动技能的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 强化学习 对抗训练 鲁棒性 运动控制 选择性攻击
📋 核心要点
- 现有强化学习运动策略在长时程运行和真实环境干扰下稳定性不足,难以满足人形机器人长时间可靠运行的需求。
- 提出选择性对抗攻击(SA2RT)方法,通过学习识别并扰动最脆弱的状态和动作,增强运动策略的鲁棒性。
- 在Unitree G1机器人上的实验表明,SA2RT将地形穿越成功率提高40%,轨迹跟踪误差降低32%,显著提升了长时程运动性能。
📝 摘要(中文)
人形机器人需要在长时间运行中可靠地执行各种全身技能。然而,强化学习(RL)运动策略在长时间运行、传感器/执行器噪声和真实世界干扰下通常会失去稳定性。本文提出了一种用于鲁棒训练的选择性对抗攻击(SA2RT),以增强运动技能的鲁棒性。对抗者被训练来识别并稀疏地扰动攻击预算约束下最脆弱的状态和动作,从而暴露真正的弱点,而不会导致保守的过拟合。由此产生的非零和、交替优化不断加强运动策略以对抗最强大的已发现攻击。我们在Unitree G1人形机器人上,通过感知运动和全身控制任务验证了我们的方法。实验结果表明,经过对抗训练的策略将地形穿越成功率提高了40%,将轨迹跟踪误差降低了32%,并保持了长时程的移动性和跟踪性能。总之,这些结果表明,选择性对抗攻击是学习鲁棒、长时程人形机器人运动技能的有效驱动力。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂环境中长时间稳定运动的问题。现有的强化学习方法训练的策略容易受到噪声和干扰的影响,导致性能下降甚至失败。痛点在于如何提高策略的鲁棒性,使其能够在各种未知环境中可靠运行。
核心思路:论文的核心思路是通过对抗训练来增强策略的鲁棒性。具体来说,引入一个对抗者,其目标是找到并攻击策略的弱点,而策略则需要学习抵抗这些攻击。通过这种对抗过程,策略能够不断地暴露和修复自身的弱点,从而提高其在各种环境中的适应能力。选择性攻击的思想在于避免过度保守的策略,而是专注于最关键的脆弱点。
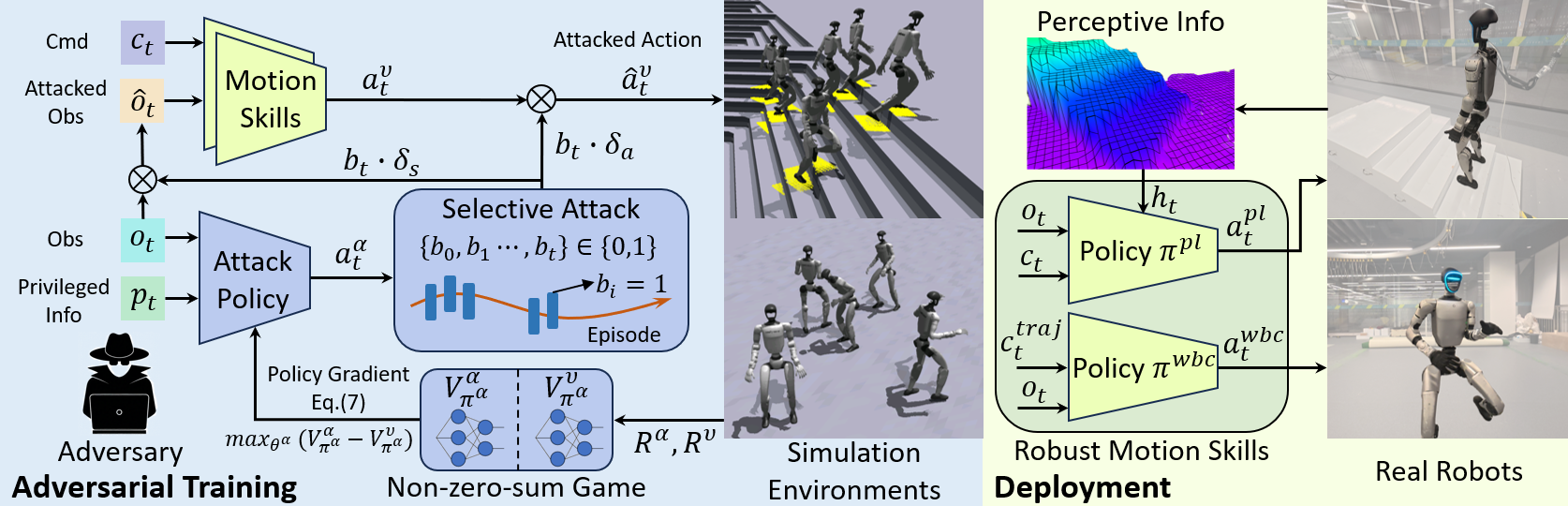
技术框架:SA2RT的整体框架是一个非零和博弈,包含策略网络和对抗网络。策略网络负责生成机器人的动作,对抗网络负责生成对状态和动作的扰动。这两个网络通过交替优化进行训练。具体流程如下:1) 策略网络生成动作;2) 对抗网络根据当前状态和动作,在预算约束下选择性地生成扰动;3) 将扰动添加到状态和动作中,得到新的状态和动作;4) 使用新的状态和动作来评估策略的性能,并更新策略网络和对抗网络。
关键创新:论文的关键创新在于提出了选择性对抗攻击。与传统的对抗训练方法不同,SA2RT不是对所有状态和动作都进行扰动,而是选择性地扰动最脆弱的状态和动作。这种选择性攻击可以更有效地暴露策略的弱点,并且可以避免过度保守的策略。此外,论文还提出了一个攻击预算约束,以限制对抗攻击的强度,从而防止策略过度适应对抗攻击。
关键设计:对抗网络的设计至关重要。它需要能够准确地识别策略的弱点,并生成有效的扰动。论文中使用了一个深度神经网络来学习对抗策略。该网络的输入是当前状态和动作,输出是对状态和动作的扰动。为了限制对抗攻击的强度,论文引入了一个攻击预算约束。该约束限制了对抗网络可以使用的扰动量。策略网络的损失函数包括奖励函数和正则化项。奖励函数用于鼓励策略执行期望的动作,正则化项用于防止策略过度拟合。
🖼️ 关键图片

📊 实验亮点
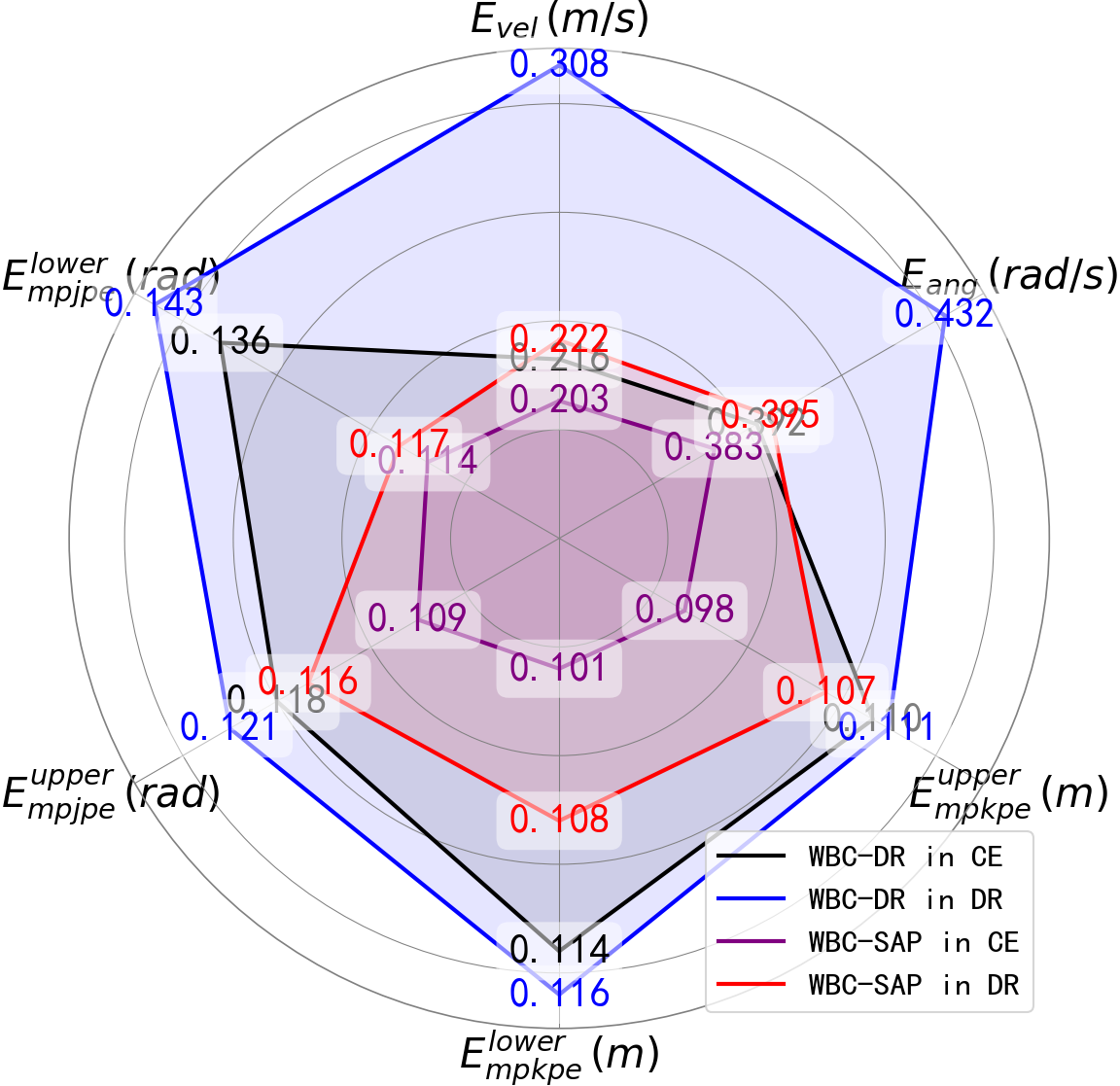
实验结果表明,SA2RT方法在Unitree G1人形机器人上取得了显著的性能提升。在地形穿越任务中,成功率提高了40%。在轨迹跟踪任务中,跟踪误差降低了32%。此外,经过对抗训练的策略能够保持长时程的移动性和跟踪性能,证明了该方法在提高机器人鲁棒性方面的有效性。这些结果表明,选择性对抗攻击是学习鲁棒、长时程人形机器人运动技能的有效驱动力。
🎯 应用场景
该研究成果可应用于各种需要人形机器人长时间稳定运动的场景,例如搜救、巡检、物流等。通过提高机器人的鲁棒性,可以使其在复杂和未知的环境中更好地完成任务,降低故障率,提高工作效率。此外,该方法还可以推广到其他类型的机器人和控制任务中,具有广泛的应用前景。
📄 摘要(原文)
Humanoid robots are expected to operate reliably over long horizons while executing versatile whole-body skills. Yet Reinforcement Learning (RL) motion policies typically lose stability under prolonged operation, sensor/actuator noise, and real world disturbances. In this work, we propose a Selective Adversarial Attack for Robust Training (SA2RT) to enhance the robustness of motion skills. The adversary is learned to identify and sparsely perturb the most vulnerable states and actions under an attack-budget constraint, thereby exposing true weakness without inducing conservative overfitting. The resulting non-zero sum, alternating optimization continually strengthens the motion policy against the strongest discovered attacks. We validate our approach on the Unitree G1 humanoid robot across perceptive locomotion and whole-body control tasks. Experimental results show that adversarially trained policies improve the terrain traversal success rate by 40%, reduce the trajectory tracking error by 32%, and maintain long horizon mobility and tracking performance. Together, these results demonstrate that selective adversarial attacks are an effective driver for learning robust, long horizon humanoid motion skills.