Making VLMs More Robot-Friendly: Self-Critical Distillation of Low-Level Procedural Reasoning
作者: Chan Young Park, Jillian Fisher, Marius Memmel, Dipika Khullar, Seoho Yun, Abhishek Gupta, Yejin Choi
分类: cs.RO
发布日期: 2025-07-11 (更新: 2025-07-20)
备注: Code Available: https://github.com/chan0park/SelfReVision
💡 一句话要点
SelfReVision:用于机器人低层程序推理的自批判蒸馏框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 机器人程序规划 自蒸馏 自批判 具身智能
📋 核心要点
- 现有大型语言模型在机器人程序规划中缺乏低层具身细节,限制了其在实际机器人控制中的应用。
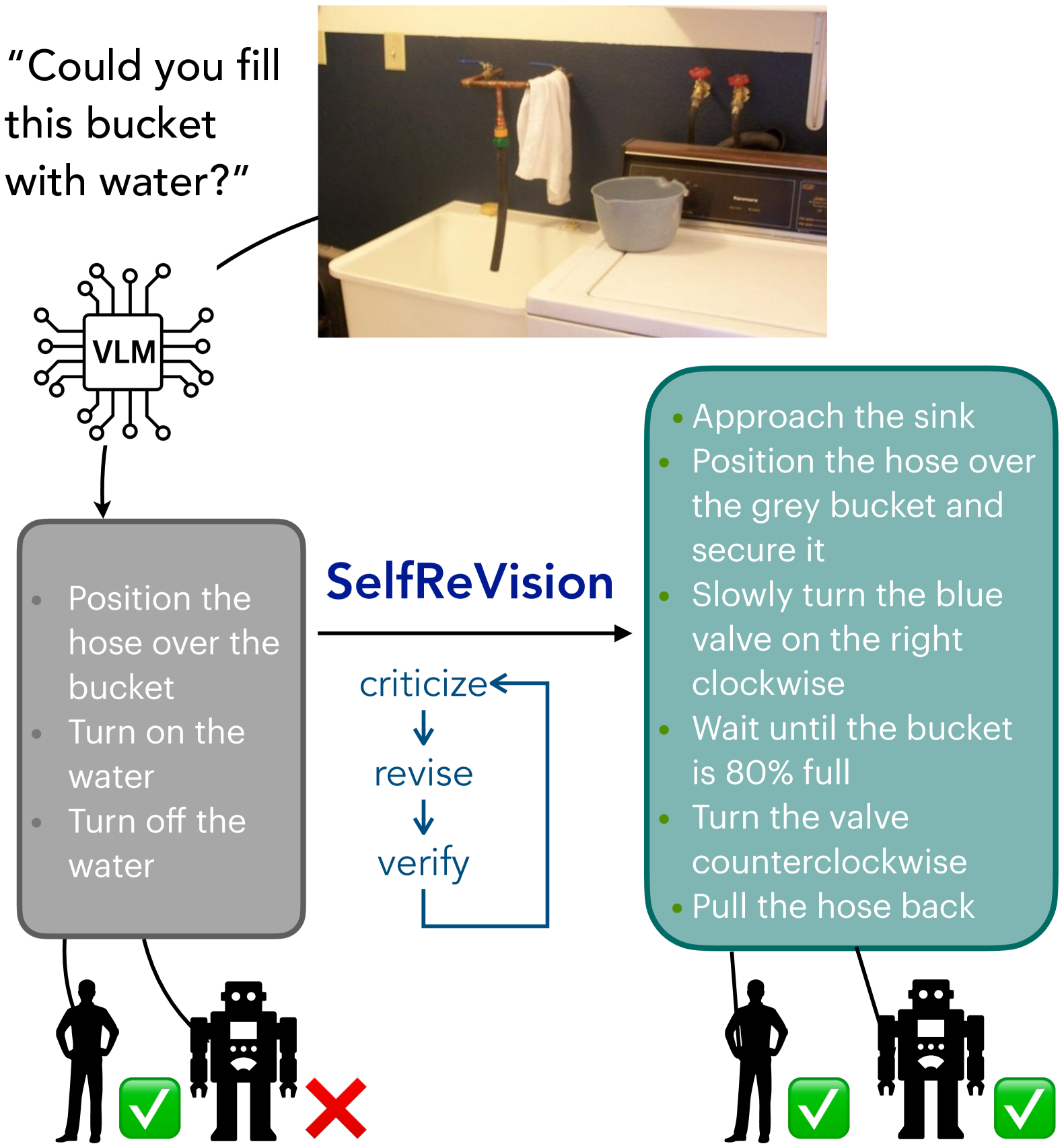
- SelfReVision通过自批判、自修正和自验证的迭代过程,提升小型视觉语言模型在机器人程序规划中的能力。
- 实验结果表明,SelfReVision能够使小型VLM超越大型VLM的性能,并在具身任务中实现更好的控制。
📝 摘要(中文)
大型语言模型(LLMs)在机器人程序规划方面展现出潜力,但其以人为中心的推理常常忽略了机器人执行所需的低层、具身细节。视觉语言模型(VLMs)为更具感知基础的规划提供了一条途径,但现有方法要么依赖于昂贵的大规模模型,要么局限于狭窄的模拟环境。我们引入SelfReVision,这是一个轻量级且可扩展的视觉语言程序规划自改进框架。SelfReVision使小型VLM能够迭代地批判、修改和验证自己的计划——无需外部监督或教师模型——借鉴了思维链提示和自指令范式。通过这种自蒸馏循环,模型生成更高质量、可执行的计划,这些计划既可以在推理时使用,也可以用于持续微调。使用从3B到72B的模型,我们的结果表明,SelfReVision不仅提高了弱基础VLM的性能,而且优于规模大100倍的模型,从而改善了下游具身任务中的控制。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)虽然在机器人程序规划方面表现出一定的潜力,但它们通常以人为中心进行推理,忽略了机器人执行所需的低层、具身细节。现有的视觉语言模型(VLMs)要么依赖于计算成本高昂的大规模模型,要么只能在狭窄的模拟环境中工作。因此,如何使小型VLM能够生成高质量、可执行的机器人程序规划,是一个亟待解决的问题。
核心思路:SelfReVision的核心思路是利用自蒸馏和自批判机制,让小型VLM通过迭代的方式不断改进自身的程序规划能力。模型首先生成一个初始计划,然后对其进行自我批判,找出其中的不足之处,并进行相应的修改。最后,模型验证修改后的计划是否可行。通过这种循环迭代,模型可以逐步提升计划的质量和可执行性。
技术框架:SelfReVision框架主要包含三个阶段:计划生成、自我批判和计划修正。在计划生成阶段,VLM根据给定的视觉输入和任务目标生成一个初始的程序计划。在自我批判阶段,VLM分析生成的计划,识别其中可能存在的错误或不足之处。在计划修正阶段,VLM根据自我批判的结果,对计划进行修改和完善。这三个阶段构成一个循环,VLM不断迭代,直到生成一个高质量、可执行的计划。
关键创新:SelfReVision的关键创新在于其自批判和自修正的机制。与传统的监督学习方法不同,SelfReVision不需要外部的监督信号,而是通过模型自身的判断和推理能力来改进计划。这种自学习的方式可以有效地利用未标注的数据,降低训练成本,并提高模型的泛化能力。此外,SelfReVision还借鉴了思维链提示和自指令范式,进一步提升了模型的推理能力。
关键设计:SelfReVision框架中,自我批判模块的设计至关重要。该模块需要能够准确地识别计划中的错误和不足之处。论文中可能使用了某种形式的奖励函数或损失函数来指导自我批判过程。此外,计划修正模块的设计也需要考虑如何有效地利用自我批判的结果来改进计划。具体的参数设置、损失函数和网络结构等技术细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
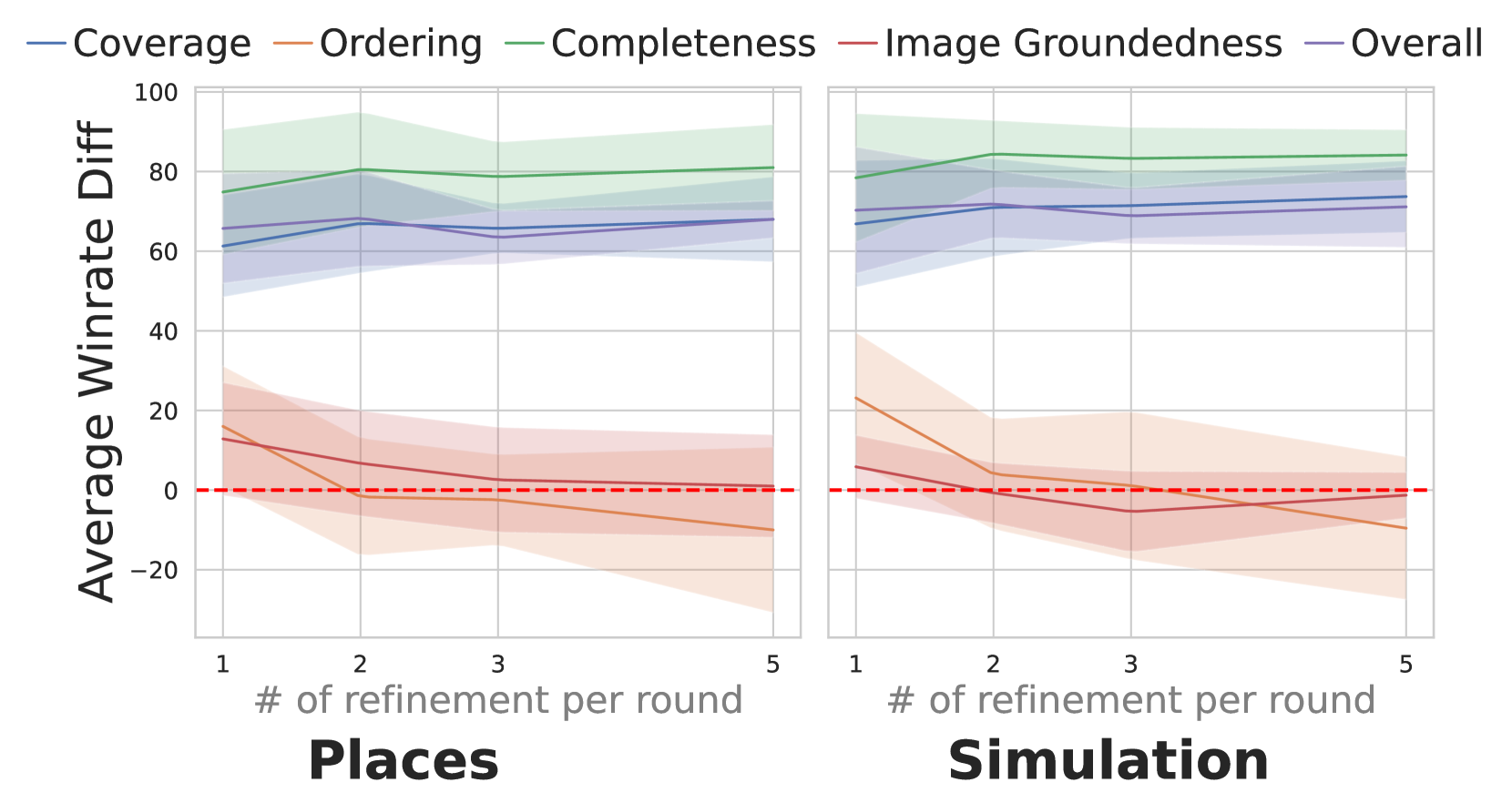
SelfReVision在机器人程序规划任务中取得了显著的性能提升。实验结果表明,SelfReVision不仅优于弱基础VLM,而且超越了规模大100倍的模型。这表明SelfReVision具有很强的竞争力,能够有效地提升小型VLM的性能,并在具身任务中实现更好的控制。具体的性能数据和对比基线需要在论文中进一步查找。
🎯 应用场景
SelfReVision具有广泛的应用前景,可用于各种机器人任务,如家庭服务机器人、工业机器人、自动驾驶等。通过提高机器人程序规划的质量和可执行性,SelfReVision可以使机器人更加智能、自主,从而更好地完成各种任务。此外,SelfReVision还可以应用于其他领域,如自然语言处理、图像生成等,以提升模型的自学习能力。
📄 摘要(原文)
Large language models (LLMs) have shown promise in robotic procedural planning, yet their human-centric reasoning often omits the low-level, grounded details needed for robotic execution. Vision-language models (VLMs) offer a path toward more perceptually grounded plans, but current methods either rely on expensive, large-scale models or are constrained to narrow simulation settings. We introduce SelfReVision, a lightweight and scalable self-improvement framework for vision-language procedural planning. SelfReVision enables small VLMs to iteratively critique, revise, and verify their own plans-without external supervision or teacher models-drawing inspiration from chain-of-thought prompting and self-instruct paradigms. Through this self-distillation loop, models generate higher-quality, execution-ready plans that can be used both at inference and for continued fine-tuning. Using models varying from 3B to 72B, our results show that SelfReVision not only boosts performance over weak base VLMs but also outperforms models 100X the size, yielding improved control in downstream embodied tasks.