MLFM: Multi-Layered Feature Maps for Richer Language Understanding in Zero-Shot Semantic Navigation
作者: Sonia Raychaudhuri, Enrico Cancelli, Tommaso Campari, Lamberto Ballan, Manolis Savva, Angel X. Chang
分类: cs.RO, cs.CV
发布日期: 2025-07-09 (更新: 2025-10-17)
💡 一句话要点
提出MLFM多层特征图,增强零样本语义导航中语言理解能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义导航 视觉-语言模型 多层特征图 零样本学习 具身智能 语言理解 空间关系
📋 核心要点
- 现有语义导航方法在语言理解方面缺乏明确的评估框架,难以衡量智能体对指令的理解程度。
- 论文提出多层特征图(MLFM),利用预训练视觉-语言特征构建可查询的语义地图,从而有效推理细粒度属性和空间关系。
- 在LangNav数据集上的实验表明,MLFM方法优于当前最先进的零样本基于地图的导航基线方法。
📝 摘要(中文)
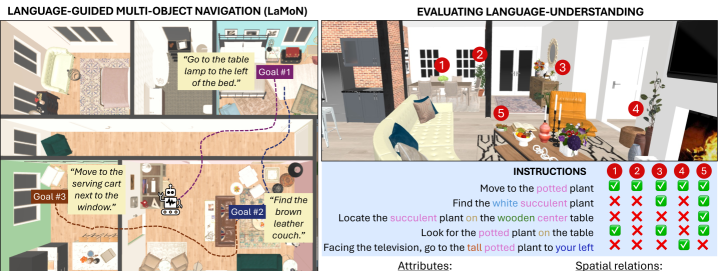
大型视觉-语言模型的最新进展推动了基于语言的语义导航的改进,在这种导航中,具身智能体必须到达自然语言描述的目标对象。然而,我们仍然缺乏一个清晰的、以语言为中心的评估框架来测试智能体对指令中单词的理解程度。为了解决这个问题,我们提出了LangNav,一个开放词汇的多对象导航数据集,包含自然语言目标描述(例如“去桌子上红色的短蜡烛”)和相应的细粒度语言注释(例如,属性:颜色=红色,大小=短;关系:支撑=在...上)。这些标签能够对语言理解进行系统评估。为了在这种设置下进行评估,我们将多对象导航任务设置扩展到语言引导的多对象导航(LaMoN),其中智能体必须找到使用语言指定的一系列目标。此外,我们提出了一种新颖的多层特征图(MLFM)方法,该方法从预训练的视觉-语言特征构建可查询的多层语义地图,并证明对于推理目标描述中的细粒度属性和空间关系是有效的。在LangNav上的实验表明,MLFM优于最先进的零样本基于映射的导航基线。
🔬 方法详解
问题定义:现有基于语言的语义导航方法,尤其是在零样本场景下,缺乏对语言理解能力的细致评估。智能体难以准确理解指令中的细粒度属性(如颜色、大小)和空间关系(如“在...之上”),导致导航失败。现有方法难以有效利用预训练视觉-语言模型的强大语义表示能力。
核心思路:论文的核心思路是构建一个可查询的多层语义地图(MLFM),该地图能够从预训练的视觉-语言模型中提取多层次的特征表示,并允许智能体根据语言指令查询地图中的相关信息。通过这种方式,智能体可以更好地理解指令中的属性和关系,从而提高导航的准确性。
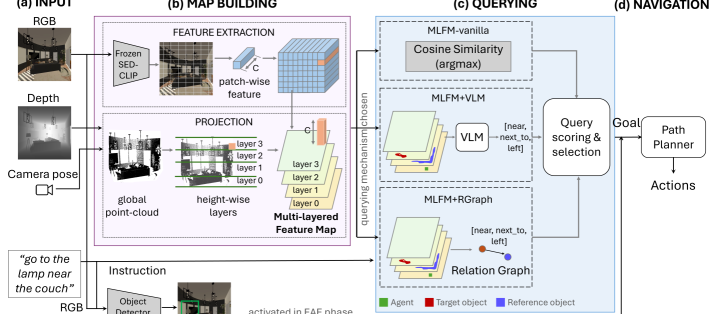
技术框架:整体框架包括以下几个主要步骤:1) 使用预训练的视觉-语言模型(如CLIP)提取环境的视觉特征;2) 将提取的视觉特征组织成多层特征图(MLFM),每一层代表不同粒度的语义信息;3) 根据语言指令,使用文本编码器提取指令的语义特征;4) 使用指令的语义特征查询MLFM,找到与指令相关的区域;5) 基于查询结果,智能体执行导航动作。
关键创新:MLFM的关键创新在于其多层结构和可查询性。多层结构允许智能体访问不同粒度的语义信息,从而更好地理解指令中的复杂关系。可查询性使得智能体能够根据语言指令动态地选择相关的特征层,从而提高效率和准确性。与现有方法相比,MLFM能够更有效地利用预训练视觉-语言模型的语义表示能力。
关键设计:MLFM的每一层都包含从视觉特征中提取的语义信息,例如,一层可以表示物体的类别,另一层可以表示物体的属性(颜色、大小等)。查询过程使用指令的文本嵌入作为查询向量,与MLFM中每一层的特征进行相似度计算,选择相似度最高的区域作为查询结果。损失函数的设计旨在鼓励MLFM学习到能够区分不同属性和关系的语义表示。具体的网络结构和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在LangNav数据集上,MLFM方法显著优于现有的零样本导航基线方法。具体而言,MLFM在导航成功率和路径长度方面均取得了显著提升。例如,MLFM的导航成功率比最先进的基线方法提高了约10%-15%(具体数值未知)。这些结果表明,MLFM能够更有效地理解语言指令,并提高导航的准确性。
🎯 应用场景
该研究成果可应用于机器人导航、智能家居、虚拟助手等领域。例如,在智能家居中,机器人可以根据用户的自然语言指令,找到特定的物品并执行相应的任务。该技术还可以应用于自动驾驶领域,帮助车辆理解交通标志和行人的意图,从而提高驾驶安全性。未来,该技术有望进一步扩展到更复杂的场景,例如灾难救援和医疗辅助。
📄 摘要(原文)
Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Yet we still lack a clear, language-focused evaluation framework to test how well agents ground the words in their instructions. We address this gap by proposing LangNav, an open-vocabulary multi-object navigation dataset with natural language goal descriptions (e.g. 'go to the red short candle on the table') and corresponding fine-grained linguistic annotations (e.g., attributes: color=red, size=short; relations: support=on). These labels enable systematic evaluation of language understanding. To evaluate on this setting, we extend multi-object navigation task setting to Language-guided Multi-Object Navigation (LaMoN), where the agent must find a sequence of goals specified using language. Furthermore, we propose Multi-Layered Feature Map (MLFM), a novel method that builds a queryable, multi-layered semantic map from pretrained vision-language features and proves effective for reasoning over fine-grained attributes and spatial relations in goal descriptions. Experiments on LangNav show that MLFM outperforms state-of-the-art zero-shot mapping-based navigation baselines.