LOVON: Legged Open-Vocabulary Object Navigator
作者: Daojie Peng, Jiahang Cao, Qiang Zhang, Jun Ma
分类: cs.RO, cs.CV
发布日期: 2025-07-09
备注: 9 pages, 10 figures; Project Page: https://daojiepeng.github.io/LOVON/
💡 一句话要点
LOVON:用于具身智能开放词汇目标导航框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 开放词汇导航 大型语言模型 机器人 目标检测 任务规划 腿式机器人
📋 核心要点
- 现有方法难以有效整合开放世界目标检测和高层任务规划,限制了其处理复杂、长距离导航任务的能力。
- LOVON框架集成了大型语言模型进行分层任务规划,并结合开放词汇视觉检测模型,适用于动态非结构化环境。
- 实验结果表明,LOVON能够成功完成长序列任务,并在多种腿式机器人上展示了其兼容性和即插即用特性。
📝 摘要(中文)
本文提出LOVON,一个新颖的框架,它集成了用于分层任务规划的大型语言模型(LLM)和开放词汇视觉检测模型,专为在动态、非结构化环境中进行有效的长距离目标导航而设计。为了应对包括视觉抖动、盲区和临时目标丢失等现实世界挑战,我们设计了专门的解决方案,例如用于视觉稳定的拉普拉斯方差滤波。我们还为机器人开发了一种功能执行逻辑,保证了LOVON在自主导航、任务适应和鲁棒的任务完成方面的能力。广泛的评估表明,LOVON 能够成功完成涉及实时检测、搜索和导航到开放词汇动态目标的长序列任务。此外,在不同腿式机器人(Unitree Go2、B2 和 H1-2)上的真实世界实验展示了LOVON的兼容性和吸引人的即插即用特性。
🔬 方法详解
问题定义:论文旨在解决开放世界环境中具身智能机器人的长距离目标导航问题。现有方法的痛点在于难以有效整合开放世界目标检测和高层任务规划,导致机器人难以处理复杂的、需要长时间规划的任务。此外,真实环境中的视觉抖动、盲区和目标临时丢失等问题也对导航的鲁棒性提出了挑战。
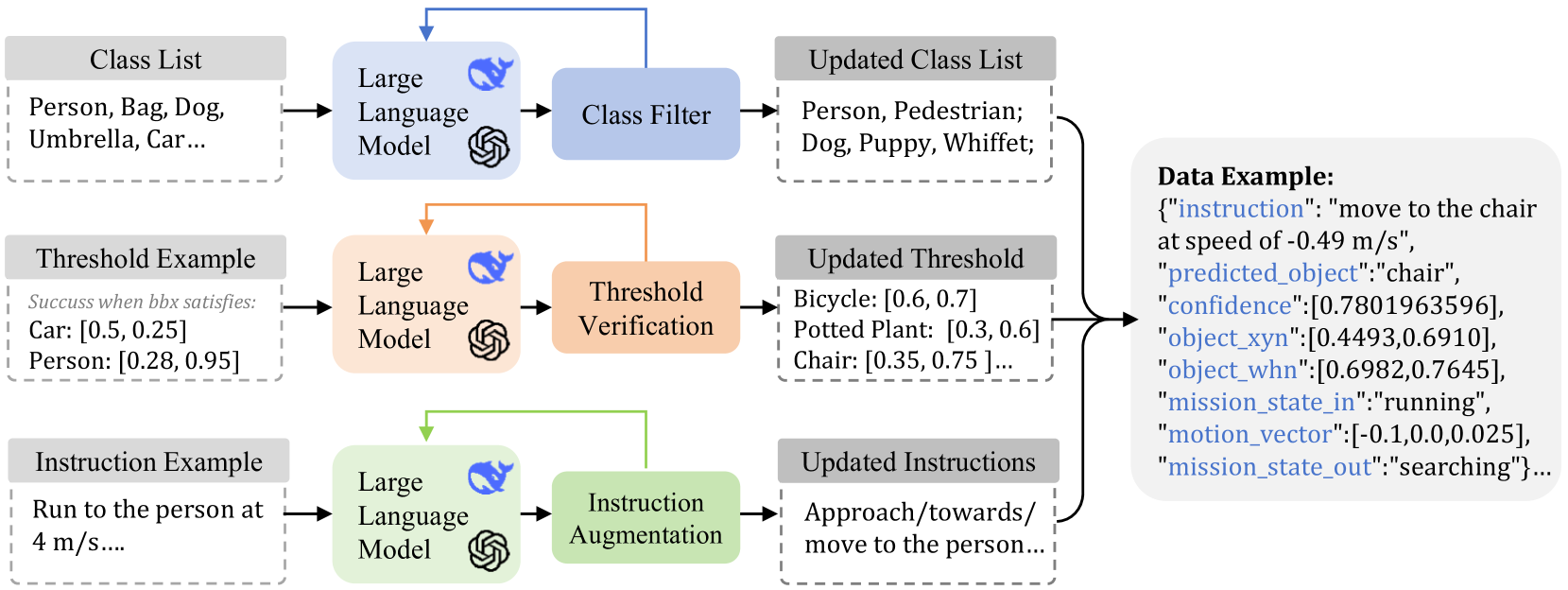
核心思路:LOVON的核心思路是利用大型语言模型(LLM)进行高层任务规划,并结合开放词汇视觉检测模型来实现对目标的识别和定位。通过分层任务规划,LLM可以将复杂的导航任务分解为一系列简单的子任务,从而降低了任务的难度。同时,针对真实环境中的挑战,论文提出了专门的解决方案,例如拉普拉斯方差滤波用于视觉稳定。
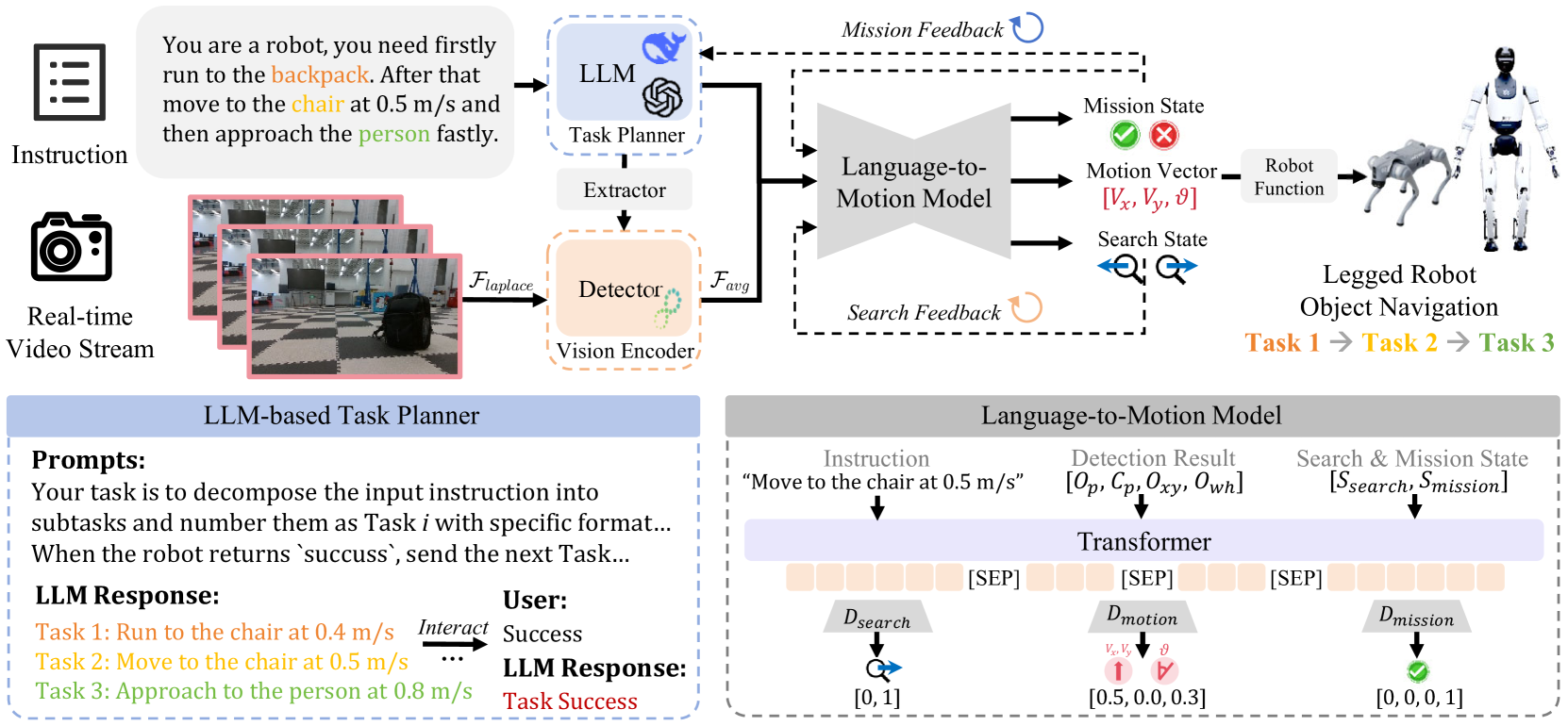
技术框架:LOVON框架包含以下主要模块:1) 大型语言模型(LLM)用于高层任务规划;2) 开放词汇视觉检测模型用于目标检测和定位;3) 拉普拉斯方差滤波用于视觉稳定;4) 功能执行逻辑用于控制机器人的运动和行为。整个流程是:首先,LLM根据用户指令生成任务规划;然后,机器人根据任务规划,利用视觉检测模型识别目标;接着,机器人利用导航算法,朝着目标移动;最后,机器人执行相应的动作,完成任务。
关键创新:LOVON最重要的技术创新点在于将大型语言模型(LLM)引入到具身智能机器人的导航任务中,并结合开放词汇视觉检测模型,实现了对开放世界目标的导航。与现有方法相比,LOVON能够处理更复杂的任务,并且具有更强的鲁棒性。
关键设计:论文中一个关键的设计是拉普拉斯方差滤波,用于解决视觉抖动问题。具体来说,该方法通过计算图像的拉普拉斯方差来评估图像的清晰度,并根据清晰度对图像进行加权平均,从而实现视觉稳定。此外,论文还设计了一种功能执行逻辑,用于控制机器人的运动和行为,保证了LOVON在自主导航、任务适应和鲁棒的任务完成方面的能力。具体的参数设置和网络结构在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LOVON能够成功完成涉及实时检测、搜索和导航到开放词汇动态目标的长序列任务。此外,在不同腿式机器人(Unitree Go2、B2 和 H1-2)上的真实世界实验展示了LOVON的兼容性和吸引人的即插即用特性。具体的性能数据和对比基线在摘要中没有给出,属于未知信息。
🎯 应用场景
LOVON框架具有广泛的应用前景,例如在家庭服务机器人、物流机器人、安防机器人等领域。它可以帮助机器人在复杂的、动态的环境中自主导航,完成各种任务,例如寻找物品、搬运货物、巡逻安防等。未来,LOVON还可以与其他技术相结合,例如语音识别、自然语言处理等,从而实现更智能、更人性化的机器人服务。
📄 摘要(原文)
Object navigation in open-world environments remains a formidable and pervasive challenge for robotic systems, particularly when it comes to executing long-horizon tasks that require both open-world object detection and high-level task planning. Traditional methods often struggle to integrate these components effectively, and this limits their capability to deal with complex, long-range navigation missions. In this paper, we propose LOVON, a novel framework that integrates large language models (LLMs) for hierarchical task planning with open-vocabulary visual detection models, tailored for effective long-range object navigation in dynamic, unstructured environments. To tackle real-world challenges including visual jittering, blind zones, and temporary target loss, we design dedicated solutions such as Laplacian Variance Filtering for visual stabilization. We also develop a functional execution logic for the robot that guarantees LOVON's capabilities in autonomous navigation, task adaptation, and robust task completion. Extensive evaluations demonstrate the successful completion of long-sequence tasks involving real-time detection, search, and navigation toward open-vocabulary dynamic targets. Furthermore, real-world experiments across different legged robots (Unitree Go2, B2, and H1-2) showcase the compatibility and appealing plug-and-play feature of LOVON.