OTAS: Open-vocabulary Token Alignment for Outdoor Segmentation
作者: Simon Schwaiger, Stefan Thalhammer, Wilfried Wöber, Gerald Steinbauer-Wagner
分类: cs.RO
发布日期: 2025-07-08 (更新: 2025-09-22)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
OTAS:面向户外场景分割的开放词汇Token对齐方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇分割 Token对齐 户外场景理解 机器人导航 零样本学习
📋 核心要点
- 现有视觉-语言模型在户外场景分割中,受限于语义模糊和类别边界不清,难以有效利用对象中心分割先验。
- OTAS通过对齐预训练视觉模型的输出token,提取语义结构,并将其与语言对齐,从而重建几何一致的特征场。
- OTAS无需场景特定微调,以零样本方式运行,在多个数据集上取得了显著的IoU提升,并实现了实时性能。
📝 摘要(中文)
在非结构化户外环境中,理解开放世界的语义对于机器人规划和控制至关重要。现有的视觉-语言映射方法通常依赖于以对象为中心的分割先验,但在户外场景中,由于语义模糊和类别边界不清晰,这些方法往往失效。我们提出了OTAS,一种用于户外分割的开放词汇Token对齐方法。OTAS通过直接从预训练视觉模型的输出token中提取语义结构,解决了开放词汇分割模型的局限性。通过聚类单视图和多视图中语义相似的结构,并将它们与语言对齐,OTAS重建了一个几何一致的特征场,支持开放词汇分割查询。我们的方法以零样本方式运行,无需特定场景的微调,并实现了高达~17 fps的实时性能。在Off-Road Freespace Detection数据集上,OTAS相对于微调和开放词汇2D分割基线取得了适度的IoU提升。在TartanAir上的3D分割中,与现有的开放词汇映射方法相比,它实现了高达151%的相对IoU提升。真实世界的重建进一步证明了OTAS在机器人部署中的适用性。代码和ROS 2节点可在https://otas-segmentation.github.io/获得。
🔬 方法详解
问题定义:论文旨在解决户外场景下,现有开放词汇分割方法对语义理解不足的问题。现有方法依赖于对象中心的分割先验,在户外场景中,由于语义模糊和类别边界不清晰,性能受到限制。这些方法难以有效处理复杂和非结构化的户外环境,阻碍了机器人在此类环境中的应用。
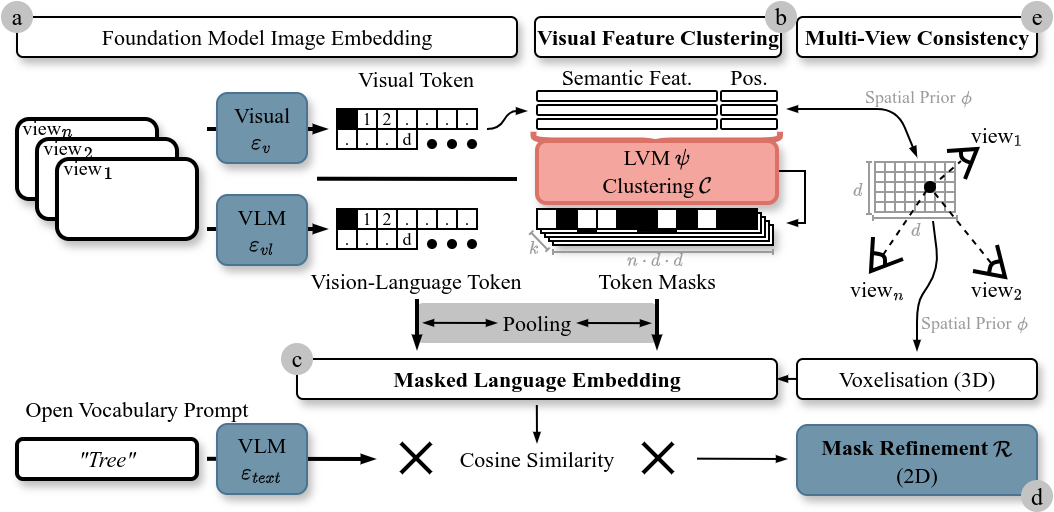
核心思路:OTAS的核心思路是从预训练视觉模型的输出token中直接提取语义结构,避免了对预定义对象类别的依赖。通过聚类语义相似的token,并在单视图和多视图中进行对齐,OTAS构建了一个几何一致的特征场。然后,该特征场可以根据开放词汇的查询进行分割,从而实现对场景的灵活理解。
技术框架:OTAS的整体框架包括以下几个主要阶段:1) 特征提取:使用预训练的视觉模型(如CLIP)提取图像的token特征。2) 语义聚类:对提取的token特征进行聚类,将语义相似的token分组。3) 几何对齐:在单视图和多视图中对聚类后的token进行几何对齐,构建几何一致的特征场。4) 语言 grounding:将特征场中的token与语言描述进行对齐,实现开放词汇的语义理解。5) 分割查询:根据用户输入的开放词汇查询,从特征场中提取相应的分割结果。
关键创新:OTAS的关键创新在于其token对齐方法,它直接从预训练视觉模型的输出token中提取语义结构,避免了对预定义对象类别的依赖。这种方法使得OTAS能够处理开放词汇的分割任务,并且在户外场景中表现出更好的鲁棒性。与现有方法相比,OTAS不需要场景特定的微调,可以以零样本的方式运行。
关键设计:OTAS的关键设计包括:1) 使用预训练的CLIP模型提取视觉特征,利用其强大的视觉-语言对齐能力。2) 采用基于密度的聚类算法(如DBSCAN)对token特征进行聚类,以适应不同场景的语义分布。3) 使用多视图几何约束对token进行对齐,提高特征场的几何一致性。4) 通过计算token特征与语言描述之间的相似度,实现语言 grounding。
🖼️ 关键图片


📊 实验亮点
OTAS在Off-Road Freespace Detection数据集上取得了适度的IoU提升,并在TartanAir数据集上的3D分割中,与现有的开放词汇映射方法相比,实现了高达151%的相对IoU提升。此外,OTAS实现了高达~17 fps的实时性能,使其适用于机器人实时应用。真实世界的重建结果也验证了OTAS在实际场景中的有效性。
🎯 应用场景
OTAS在机器人导航、自动驾驶、环境监测等领域具有广泛的应用前景。它可以帮助机器人在复杂的户外环境中理解场景语义,从而实现更智能的规划和控制。例如,机器人可以根据“草地”、“道路”、“树木”等开放词汇的查询,自主识别可行走区域和障碍物,从而安全地完成导航任务。此外,OTAS还可以用于构建三维语义地图,为机器人提供更丰富的环境信息。
📄 摘要(原文)
Understanding open-world semantics is critical for robotic planning and control, particularly in unstructured outdoor environments. Existing vision-language mapping approaches typically rely on object-centric segmentation priors, which often fail outdoors due to semantic ambiguities and indistinct class boundaries. We propose OTAS - an Open-vocabulary Token Alignment method for outdoor Segmentation. OTAS addresses the limitations of open-vocabulary segmentation models by extracting semantic structure directly from the output tokens of pre-trained vision models. By clustering semantically similar structures across single and multiple views and grounding them in language, OTAS reconstructs a geometrically consistent feature field that supports open-vocabulary segmentation queries. Our method operates in a zero-shot manner, without scene-specific fine-tuning, and achieves real-time performance of up to ~17 fps. On the Off-Road Freespace Detection dataset, OTAS yields a modest IoU improvement over fine-tuned and open-vocabulary 2D segmentation baselines. In 3D segmentation on TartanAir, it achieves up to a 151% relative IoU improvement compared to existing open-vocabulary mapping methods. Real-world reconstructions further demonstrate OTAS' applicability to robotic deployment. Code and a ROS 2 node are available at https://otas-segmentation.github.io/.