Integrating Diffusion-based Multi-task Learning with Online Reinforcement Learning for Robust Quadruped Robot Control
作者: Xinyao Qin, Xiaoteng Ma, Yang Qi, Qihan Liu, Chuanyi Xue, Ning Gui, Qinyu Dong, Jun Yang, Bin Liang
分类: cs.RO
发布日期: 2025-07-08 (更新: 2025-09-12)
💡 一句话要点
DMLoco:融合扩散模型多任务学习与在线强化学习的鲁棒四足机器人控制框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 四足机器人 扩散模型 多任务学习 在线强化学习 运动控制 语言引导
📋 核心要点
- 现有模仿学习方法在四足机器人运动控制中面临复合误差导致的稳定性和有限数据下的任务转换困难等挑战。
- DMLoco框架通过扩散模型进行多任务预训练,赋予机器人语言引导的技能执行能力,并结合在线强化学习进行微调,提升鲁棒性。
- 该方法利用DDIM加速采样,并使用TensorRT优化部署,实现了在板端50Hz的高效运行,验证了其在资源受限平台上的可行性。
📝 摘要(中文)
本文提出DMLoco,一个基于扩散模型的四足机器人控制框架,它集成了多任务预训练与在线PPO微调,以实现语言条件控制和鲁棒的任务转换。该方法首先利用扩散模型在多样化的多任务数据集上预训练策略,从而实现语言引导的多种技能执行。然后,在仿真环境中微调策略,以确保在真实世界部署期间的鲁棒性和稳定的任务转换。通过利用去噪扩散隐式模型(DDIM)进行高效采样,并使用TensorRT进行优化部署,该策略能够在资源受限的机器人平台上以50Hz的频率在板上运行,从而为自适应的、语言引导的运动提供可扩展且高效的解决方案。
🔬 方法详解
问题定义:现有的模仿学习方法在四足机器人运动控制中,尤其是在腿足运动方面,应用相对较少。主要痛点在于,由于复合误差的累积,导致机器人难以保持稳定。此外,在数据有限的情况下,任务之间的平滑过渡也面临挑战。因此,需要一种能够克服这些问题,实现鲁棒、高效的四足机器人控制方法。
核心思路:DMLoco的核心思路是将扩散模型强大的多任务泛化能力与在线强化学习的鲁棒性相结合。扩散模型用于预训练,使机器人能够学习多种技能,并具备语言引导的能力。在线强化学习则用于微调策略,提高其在真实环境中的适应性和鲁棒性,从而解决复合误差和任务转换问题。
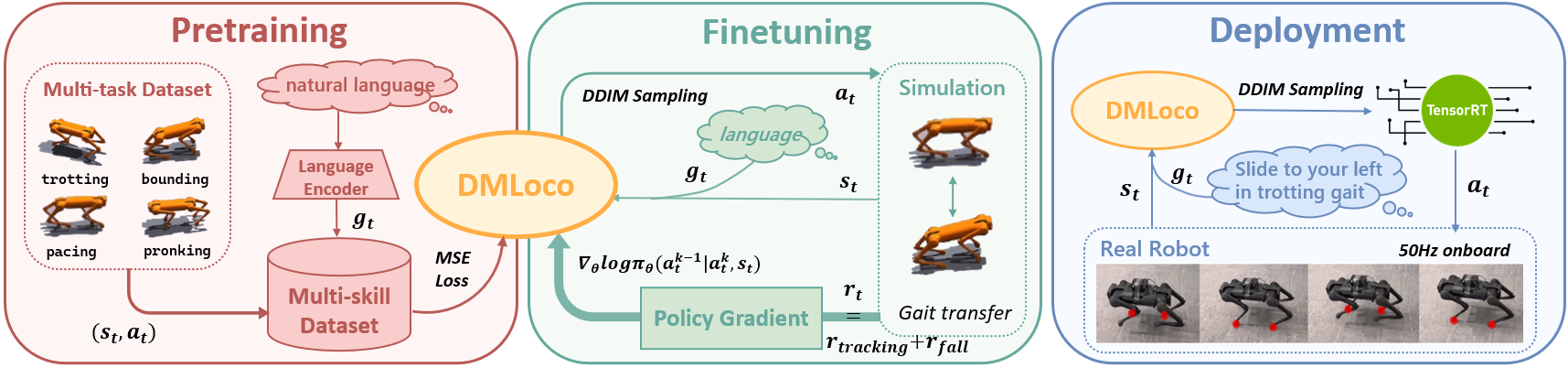
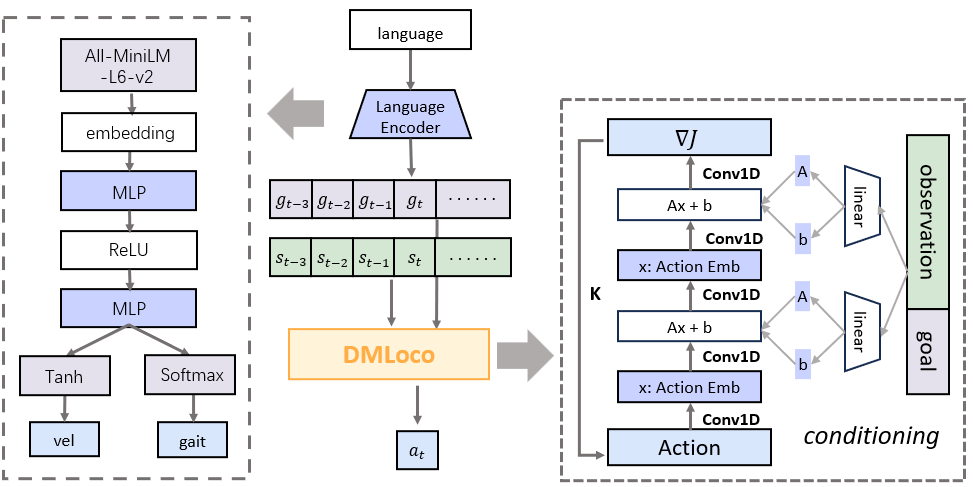
技术框架:DMLoco框架包含两个主要阶段:多任务预训练和在线强化学习微调。在多任务预训练阶段,使用扩散模型在包含多种任务的数据集上训练策略网络,使其具备执行不同技能的能力。在在线强化学习微调阶段,使用PPO算法在仿真环境中对预训练的策略进行微调,以提高其鲁棒性和适应性。此外,还采用了DDIM进行高效采样,并使用TensorRT进行优化部署,以实现板端实时控制。
关键创新:DMLoco的关键创新在于将扩散模型和在线强化学习相结合,用于四足机器人的运动控制。扩散模型能够学习到丰富的技能表示,并具备语言引导的能力,而在线强化学习则能够提高策略的鲁棒性和适应性。这种结合克服了传统模仿学习方法在四足机器人控制中面临的挑战。
关键设计:DMLoco的关键设计包括:1) 使用Denoising Diffusion Implicit Models (DDIM) 加速采样过程,提高训练和推理效率;2) 利用TensorRT优化模型部署,使其能够在资源受限的板端设备上实时运行;3) 精心设计的奖励函数,用于在线强化学习阶段的策略微调,以提高机器人的运动稳定性和任务完成度;4) 多样化的多任务数据集,用于扩散模型的预训练,确保模型能够学习到丰富的技能表示。
🖼️ 关键图片

📊 实验亮点
DMLoco框架在仿真环境中进行了验证,实验结果表明,该方法能够有效地提高四足机器人的运动稳定性和任务完成度。通过与基线方法进行对比,DMLoco在任务成功率和运动效率方面均取得了显著提升。此外,该方法还能够在板端设备上以50Hz的频率实时运行,验证了其在资源受限平台上的可行性。
🎯 应用场景
DMLoco框架具有广泛的应用前景,可用于搜救、巡检、物流等多种场景。该方法能够使四足机器人具备更强的环境适应性和任务执行能力,从而在复杂环境中完成各种任务。此外,语言引导的控制方式也使得人机交互更加自然和便捷,为机器人的智能化应用提供了新的可能性。
📄 摘要(原文)
Recent research has highlighted the powerful capabilities of imitation learning in robotics. Leveraging generative models, particularly diffusion models, these approaches offer notable advantages such as strong multi-task generalization, effective language conditioning, and high sample efficiency. While their application has been successful in manipulation tasks, their use in legged locomotion remains relatively underexplored, mainly due to compounding errors that affect stability and difficulties in task transition under limited data. Online reinforcement learning (RL) has demonstrated promising results in legged robot control in the past years, providing valuable insights to address these challenges. In this work, we propose DMLoco, a diffusion-based framework for quadruped robots that integrates multi-task pretraining with online PPO finetuning to enable language-conditioned control and robust task transitions. Our approach first pretrains the policy on a diverse multi-task dataset using diffusion models, enabling language-guided execution of various skills. Then, it finetunes the policy in simulation to ensure robustness and stable task transition during real-world deployment. By utilizing Denoising Diffusion Implicit Models (DDIM) for efficient sampling and TensorRT for optimized deployment, our policy runs onboard at 50Hz, offering a scalable and efficient solution for adaptive, language-guided locomotion on resource-constrained robotic platforms.