Action Space Reduction Strategies for Reinforcement Learning in Autonomous Driving
作者: Elahe Delavari, Feeza Khan Khanzada, Jaerock Kwon
分类: cs.RO, cs.AI
发布日期: 2025-07-07
💡 一句话要点
提出动态掩码与相对动作空间缩减策略,提升自动驾驶强化学习效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 动作空间缩减 动态掩码 相对动作空间 近端策略优化 多模态学习
📋 核心要点
- 现有自动驾驶强化学习方法面临高维动作空间带来的训练效率低下和探索成本高昂的挑战。
- 论文提出动态掩码和相对动作空间缩减两种策略,通过上下文感知的方式减少无效或次优动作选择。
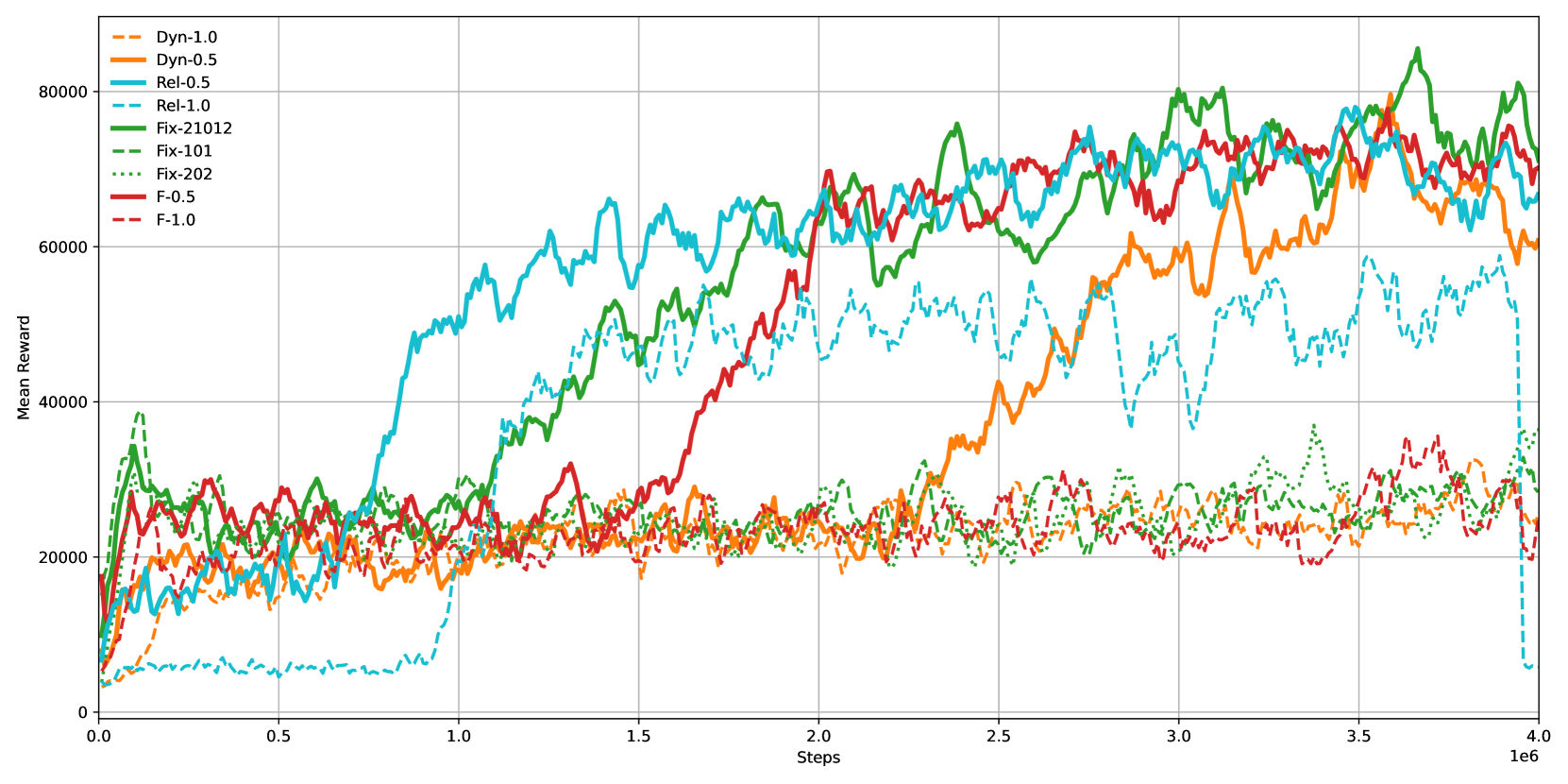
- 实验结果表明,所提出的策略能显著提升训练稳定性、策略性能,并在学习速度、控制精度和泛化能力间取得平衡。
📝 摘要(中文)
强化学习(RL)为自动驾驶提供了一个有前景的框架,它使智能体能够通过与环境交互来学习控制策略。然而,通常用于支持细粒度控制的大型和高维动作空间会阻碍训练效率并增加探索成本。本研究介绍并评估了两种用于自动驾驶RL的新的结构化动作空间修改策略:动态掩码和相对动作空间缩减。这些方法与固定缩减方案和完整动作空间基线进行系统比较,以评估它们对策略学习和性能的影响。我们的框架利用多模态近端策略优化(PPO)智能体,该智能体处理语义图像序列和标量车辆状态。所提出的动态和相对策略结合了基于上下文和状态转换的实时动作掩码,在消除无效或次优选择的同时保持动作一致性。通过在不同驾驶路线上的综合实验,我们表明动作空间缩减显着提高了训练稳定性和策略性能。特别是,动态和相对方案在学习速度、控制精度和泛化之间取得了良好的平衡。这些发现突出了上下文感知动作空间设计对于自动驾驶任务中可扩展和可靠的RL的重要性。
🔬 方法详解
问题定义:自动驾驶中的强化学习任务通常需要处理高维、连续的动作空间,例如方向盘转角、油门和刹车力度等。直接在高维空间中进行探索和学习效率低下,收敛速度慢,并且难以找到最优策略。现有的固定动作空间缩减方法可能过于简化动作空间,导致控制精度下降,无法适应复杂的驾驶场景。
核心思路:论文的核心思路是根据车辆的当前状态和环境上下文,动态地调整动作空间,从而在保证控制精度的前提下,减少需要探索的动作数量。动态掩码策略通过实时屏蔽无效或次优的动作来缩小动作空间。相对动作空间缩减策略则将动作定义为相对于当前状态的增量,而不是绝对值,从而减少动作空间的范围。
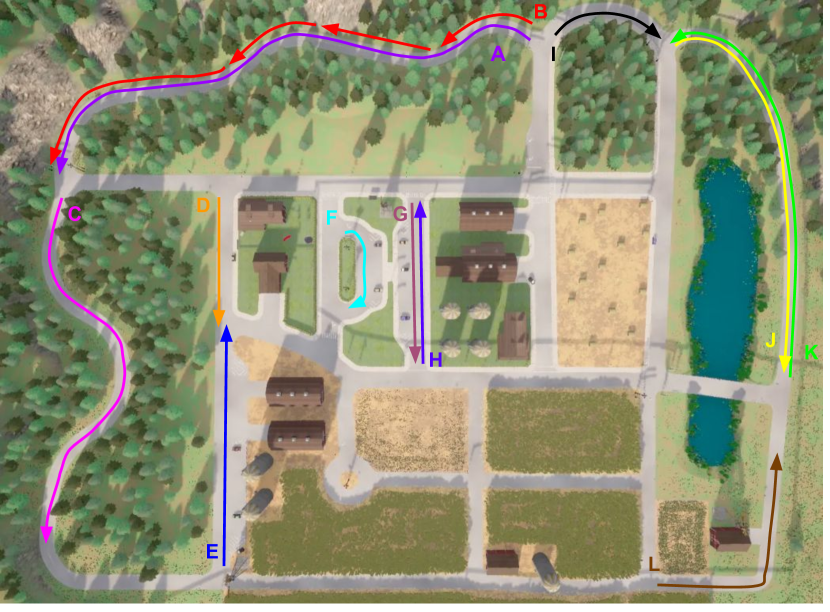
技术框架:该框架采用多模态近端策略优化(PPO)算法作为基础强化学习算法。智能体接收两种类型的输入:语义图像序列和标量车辆状态。语义图像序列提供环境的视觉信息,标量车辆状态提供车辆的速度、位置等信息。智能体根据这些输入,选择一个动作,并获得环境的奖励。PPO算法用于更新智能体的策略,使其能够更好地选择动作。动态掩码和相对动作空间缩减策略被集成到PPO算法中,用于动态地调整动作空间。
关键创新:论文的关键创新在于提出了两种上下文感知的动作空间缩减策略:动态掩码和相对动作空间缩减。动态掩码策略能够根据车辆状态和环境上下文,实时屏蔽无效或次优的动作,从而减少需要探索的动作数量。相对动作空间缩减策略将动作定义为相对于当前状态的增量,从而减少动作空间的范围。这两种策略都能够在保证控制精度的前提下,提高强化学习的效率。
关键设计:动态掩码策略的关键在于如何确定哪些动作是无效或次优的。论文中,动态掩码的实现依赖于对环境和车辆状态的理解,例如,在车辆静止时,屏蔽加速动作。相对动作空间缩减策略的关键在于如何选择合适的增量范围。论文中,增量范围的选择需要根据具体的驾驶场景进行调整。损失函数采用标准的PPO损失函数,网络结构采用能够处理多模态输入的网络结构,例如卷积神经网络(CNN)用于处理图像序列,全连接网络(MLP)用于处理标量车辆状态。
🖼️ 关键图片
📊 实验亮点
实验结果表明,动态掩码和相对动作空间缩减策略能够显著提高自动驾驶强化学习的效率和性能。与固定缩减方案和完整动作空间基线相比,所提出的策略在训练稳定性和策略性能方面均有提升。尤其是在复杂驾驶场景下,动态和相对方案在学习速度、控制精度和泛化能力之间取得了更好的平衡。
🎯 应用场景
该研究成果可应用于自动驾驶车辆的运动规划与控制,尤其是在复杂交通环境下的决策。通过降低动作空间维度,可以提升自动驾驶系统在资源受限平台上的部署能力,并加速算法的迭代优化。此外,该方法也可推广至其他机器人控制领域,例如无人机、机械臂等。
📄 摘要(原文)
Reinforcement Learning (RL) offers a promising framework for autonomous driving by enabling agents to learn control policies through interaction with environments. However, large and high-dimensional action spaces often used to support fine-grained control can impede training efficiency and increase exploration costs. In this study, we introduce and evaluate two novel structured action space modification strategies for RL in autonomous driving: dynamic masking and relative action space reduction. These approaches are systematically compared against fixed reduction schemes and full action space baselines to assess their impact on policy learning and performance. Our framework leverages a multimodal Proximal Policy Optimization agent that processes both semantic image sequences and scalar vehicle states. The proposed dynamic and relative strategies incorporate real-time action masking based on context and state transitions, preserving action consistency while eliminating invalid or suboptimal choices. Through comprehensive experiments across diverse driving routes, we show that action space reduction significantly improves training stability and policy performance. The dynamic and relative schemes, in particular, achieve a favorable balance between learning speed, control precision, and generalization. These findings highlight the importance of context-aware action space design for scalable and reliable RL in autonomous driving tasks.