StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
作者: Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, Xihui Liu, Jiangmiao Pang
分类: cs.RO, cs.CV
发布日期: 2025-07-07
💡 一句话要点
提出StreamVLN,通过慢速-快速上下文建模实现低延迟的流式视觉语言导航。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 流式处理 上下文建模 视频大语言模型 低延迟
📋 核心要点
- 现有基于视频大语言模型的视觉语言导航方法在细粒度视觉理解、长期上下文建模和计算效率之间存在权衡。
- StreamVLN采用混合的慢速-快速上下文建模,利用快速对话上下文和慢速视觉记忆上下文,实现高效的多模态推理。
- 实验表明,StreamVLN在VLN-CE基准上实现了最先进的性能,并保持了稳定的低延迟,提升了实际部署的鲁棒性。
📝 摘要(中文)
本文提出StreamVLN,一个流式视觉语言导航框架,它采用混合的慢速-快速上下文建模策略,以支持交错的视觉、语言和动作输入上的多模态推理。快速流式对话上下文通过活动对话的滑动窗口促进响应式动作生成,而慢速更新的记忆上下文使用3D感知的token剪枝策略压缩历史视觉状态。通过这种慢速-快速设计,StreamVLN通过高效的KV缓存重用实现连贯的多轮对话,支持具有有界上下文大小和推理成本的长视频流。在VLN-CE基准上的实验表明,StreamVLN实现了最先进的性能,并具有稳定的低延迟,确保了在实际部署中的鲁棒性和效率。
🔬 方法详解
问题定义:现有的基于视频大语言模型的视觉语言导航方法难以兼顾细粒度的视觉理解、长期的上下文建模以及计算效率。在实际应用中,需要处理连续的视觉流,并根据语言指令以低延迟生成动作,这对于现有方法是一个挑战。
核心思路:StreamVLN的核心思路是采用一种混合的慢速-快速上下文建模策略。快速上下文处理当前的对话信息,保证响应速度;慢速上下文则负责维护历史视觉信息,进行长期记忆,从而在保证效率的同时,实现连贯的多轮对话。
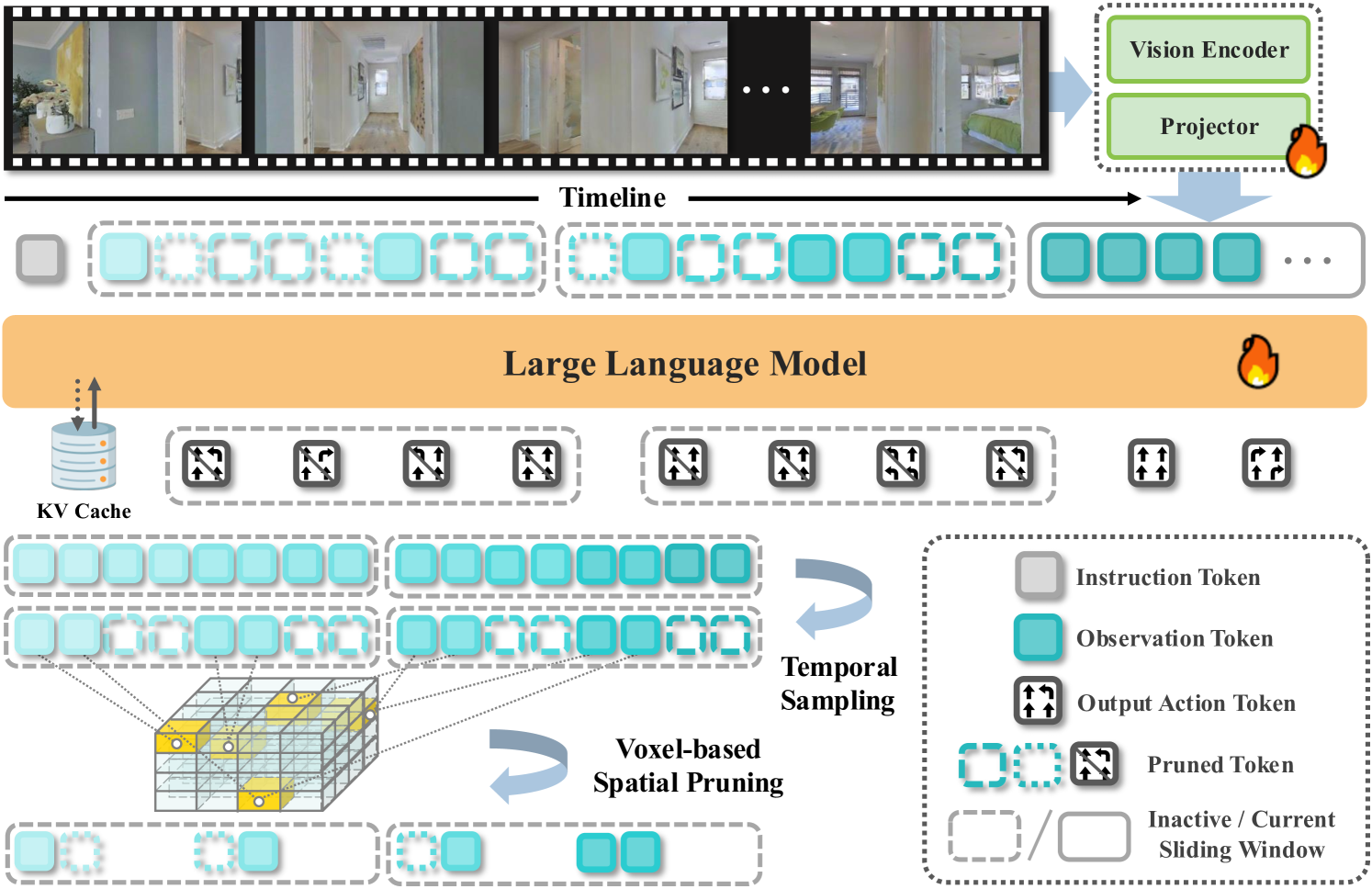
技术框架:StreamVLN框架主要包含两个上下文建模模块:快速流式对话上下文和慢速更新的记忆上下文。快速流式对话上下文使用滑动窗口机制处理当前的对话信息,用于快速生成动作。慢速更新的记忆上下文则负责压缩历史视觉状态,使用3D感知的token剪枝策略来减少计算量。这两个模块协同工作,共同完成视觉语言导航任务。
关键创新:StreamVLN的关键创新在于其混合的慢速-快速上下文建模策略。这种策略能够有效地平衡计算效率和上下文建模能力,使得模型能够在处理长视频流时保持低延迟和连贯性。此外,3D感知的token剪枝策略也是一个重要的创新点,它能够有效地压缩历史视觉信息,减少计算量。
关键设计:快速上下文模块采用滑动窗口大小为K的活动对话窗口,维护最近的K轮对话。慢速上下文模块使用3D感知的token剪枝策略,根据视觉特征的重要性进行token筛选,保留重要的视觉信息。KV缓存重用机制被用于加速推理过程,减少重复计算。
🖼️ 关键图片

📊 实验亮点
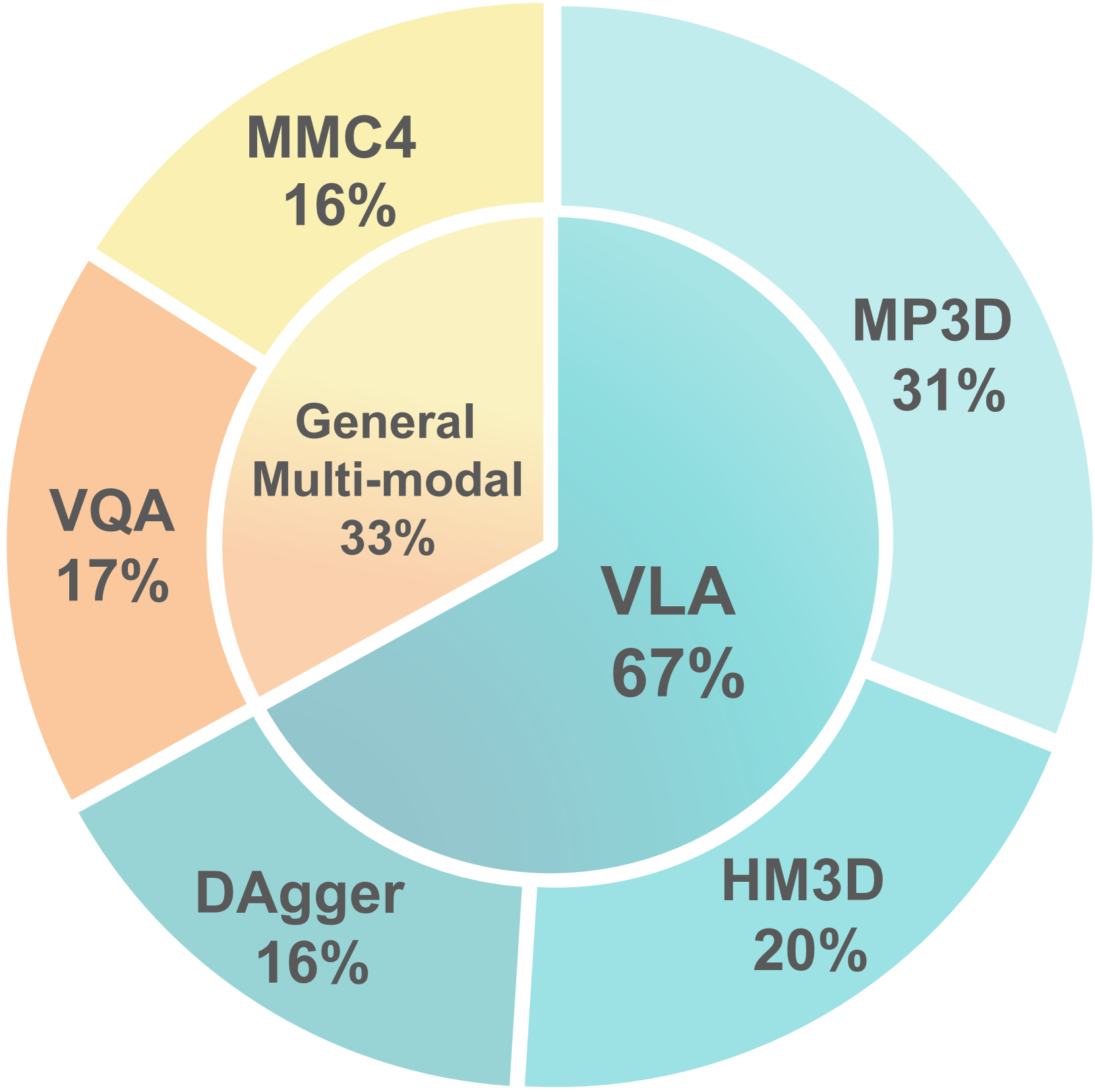
StreamVLN在VLN-CE基准测试中取得了最先进的性能,同时保持了稳定的低延迟。具体而言,StreamVLN在多个指标上超越了现有的最佳模型,并且在处理长视频流时表现出更强的鲁棒性。实验结果表明,StreamVLN的慢速-快速上下文建模策略能够有效地平衡计算效率和上下文建模能力,使其在实际应用中具有显著优势。
🎯 应用场景
StreamVLN具有广泛的应用前景,例如在机器人导航、智能家居、自动驾驶等领域。它可以帮助机器人在复杂的环境中理解人类指令,并做出相应的动作。该研究的实际价值在于提高了视觉语言导航系统的效率和鲁棒性,使其更适用于实际部署。未来,可以进一步探索如何将StreamVLN应用于更复杂的场景,例如多智能体协作导航。
📄 摘要(原文)
Vision-and-Language Navigation (VLN) in real-world settings requires agents to process continuous visual streams and generate actions with low latency grounded in language instructions. While Video-based Large Language Models (Video-LLMs) have driven recent progress, current VLN methods based on Video-LLM often face trade-offs among fine-grained visual understanding, long-term context modeling and computational efficiency. We introduce StreamVLN, a streaming VLN framework that employs a hybrid slow-fast context modeling strategy to support multi-modal reasoning over interleaved vision, language and action inputs. The fast-streaming dialogue context facilitates responsive action generation through a sliding-window of active dialogues, while the slow-updating memory context compresses historical visual states using a 3D-aware token pruning strategy. With this slow-fast design, StreamVLN achieves coherent multi-turn dialogue through efficient KV cache reuse, supporting long video streams with bounded context size and inference cost. Experiments on VLN-CE benchmarks demonstrate state-of-the-art performance with stable low latency, ensuring robustness and efficiency in real-world deployment. The project page is: \href{https://streamvln.github.io/}{https://streamvln.github.io/}.