LERa: Replanning with Visual Feedback in Instruction Following
作者: Svyatoslav Pchelintsev, Maxim Patratskiy, Anatoly Onishchenko, Alexandr Korchemnyi, Aleksandr Medvedev, Uliana Vinogradova, Ilya Galuzinsky, Aleksey Postnikov, Alexey K. Kovalev, Aleksandr I. Panov
分类: cs.RO
发布日期: 2025-07-07 (更新: 2025-10-04)
备注: Accepted to IROS 2025
💡 一句话要点
LERa:基于视觉反馈的指令跟随任务重规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 机器人重规划 指令跟随 视觉反馈 任务规划 动态环境 错误处理
📋 核心要点
- 现有机器人任务规划方法依赖文本输入,难以适应真实世界动态变化和任务执行失败。
- LERa利用视觉语言模型,通过观察、解释、重规划三个步骤,实现基于视觉反馈的动态重规划。
- 实验表明,LERa在动态环境和模拟环境中显著提升了任务成功率,并在真实机器人实验中验证了其有效性。
📝 摘要(中文)
大型语言模型越来越多地应用于机器人任务规划,但它们对文本输入的依赖限制了其对真实世界变化和失败的适应性。为了应对这些挑战,我们提出了LERa——观察、解释、重规划——一种基于视觉语言模型的重规划方法,该方法利用视觉反馈。与现有方法不同,LERa只需要原始RGB图像、自然语言指令、初始任务计划和失败检测,而不需要诸如对象检测或预定义条件等在给定场景中可能不可用的额外信息。重规划过程包括三个步骤:(i)观察——LERa生成场景描述并识别错误;(ii)解释——它提供纠正指导;(iii)重规划——它相应地修改计划。LERa适用于各种代理架构,并且可以处理来自动态场景变化和任务执行失败的错误。我们在新引入的ALFRED-ChaOS和VirtualHome-ChaOS数据集上评估了LERa,在动态环境中实现了比基线方法高40%的性能提升。在PyBullet模拟器中,对于具有预定义任务失败概率的桌面操作任务,LERa将成功率提高了高达67%。进一步的实验,包括使用桌面操作机器人的真实世界试验,证实了LERa在重规划方面的有效性。我们证明LERa是机器人中感知错误的任务执行的强大且适应性强的解决方案。
🔬 方法详解
问题定义:现有基于大型语言模型的机器人任务规划方法,严重依赖文本输入,无法有效应对真实世界中动态变化的场景和任务执行过程中出现的各种失败情况。这些方法通常需要预先定义好的条件或依赖额外的对象检测信息,限制了其在复杂和未知环境中的应用。
核心思路:LERa的核心思路是利用视觉语言模型(VLM)直接从原始RGB图像中提取环境信息,并结合自然语言指令和初始任务计划,进行错误识别、解释和重规划。通过引入视觉反馈,使机器人能够感知环境变化和任务执行状态,从而动态调整任务计划,提高任务的鲁棒性和成功率。
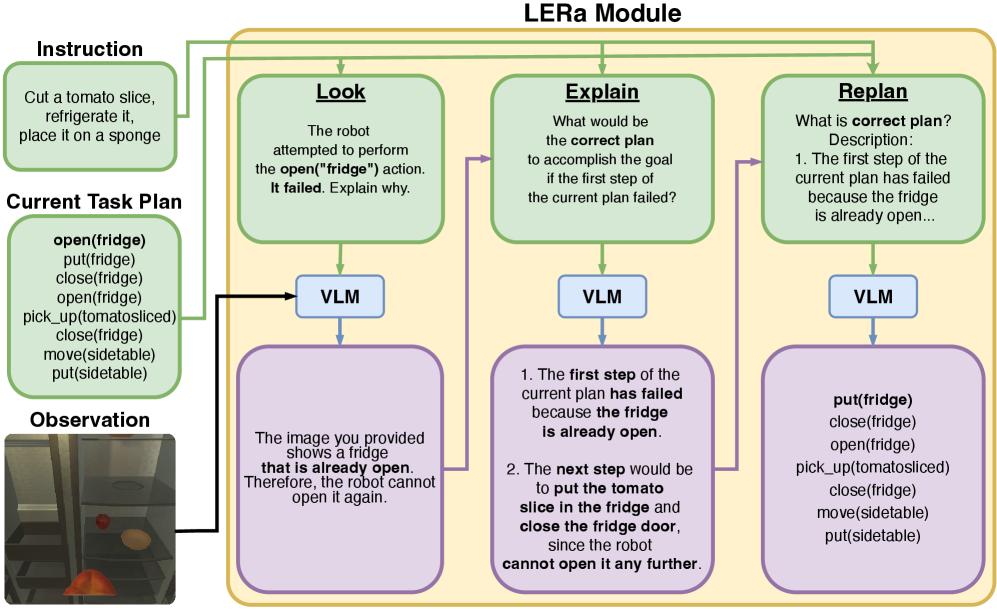
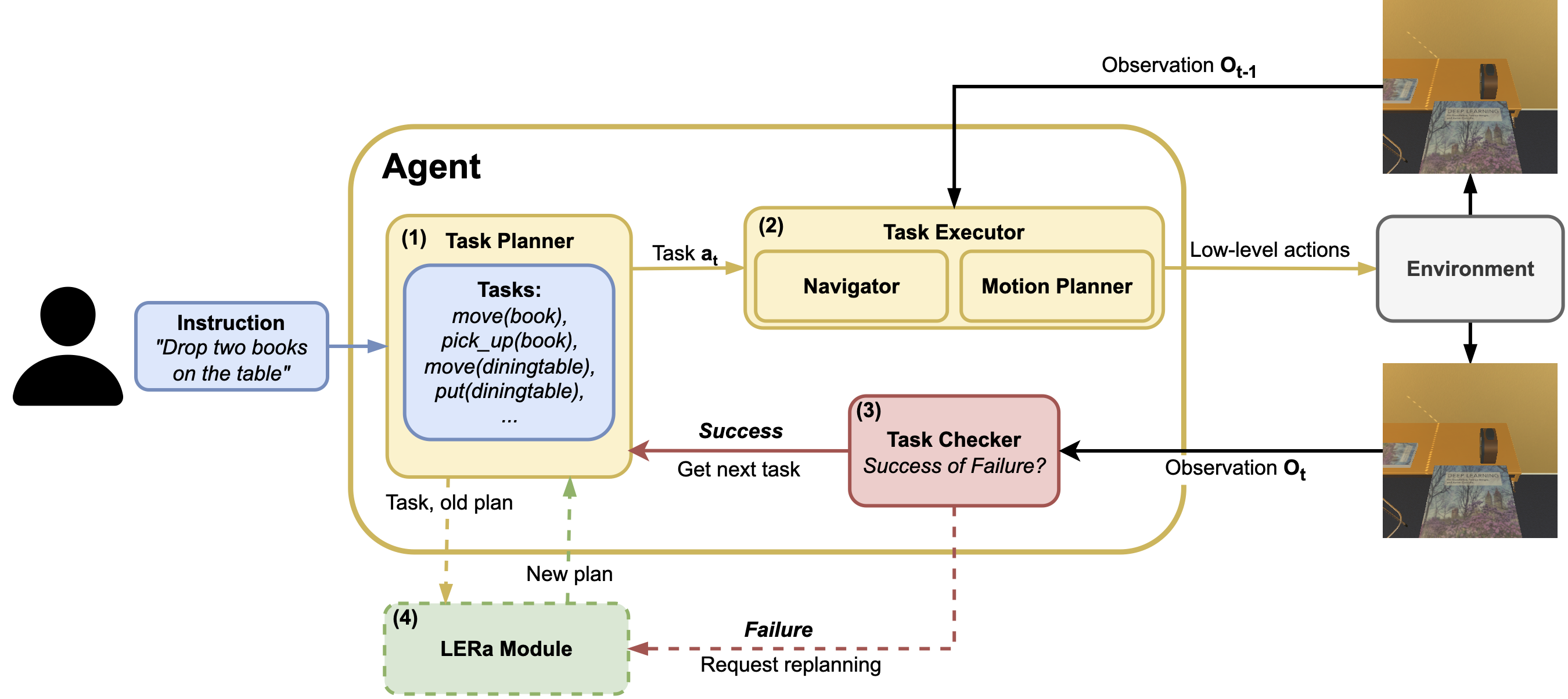
技术框架:LERa的整体框架包含三个主要阶段:(i) 观察 (Look):VLM分析RGB图像,生成场景描述并识别错误。(ii) 解释 (Explain):VLM基于场景描述和错误信息,提供纠正指导。(iii) 重规划 (Replan):VLM根据纠正指导,修改初始任务计划。该框架可以与不同的机器人代理架构集成,适用于各种任务场景。
关键创新:LERa的关键创新在于其完全依赖视觉输入进行重规划,无需额外的对象检测或预定义条件。这使得LERa能够适应更广泛的场景,并处理各种类型的错误,包括动态场景变化和任务执行失败。此外,LERa的模块化设计使其易于集成到不同的机器人系统中。
关键设计:LERa使用预训练的视觉语言模型作为其核心组件。具体使用的VLM类型和参数设置在论文中可能有所描述(未知,需查阅原文)。损失函数的设计可能包括鼓励VLM生成准确的场景描述、有效的纠正指导和可执行的重规划方案(未知,需查阅原文)。此外,如何有效地将VLM的输出转化为机器人可执行的动作序列也是一个关键的设计考虑(未知,需查阅原文)。
🖼️ 关键图片

📊 实验亮点
LERa在ALFRED-ChaOS和VirtualHome-ChaOS数据集上取得了显著的性能提升,在动态环境中比基线方法提高了40%的任务成功率。在PyBullet模拟器中的桌面操作任务中,LERa将成功率提高了高达67%。此外,真实机器人实验也验证了LERa在实际场景中的有效性,表明其具有很强的泛化能力。
🎯 应用场景
LERa具有广泛的应用前景,可应用于家庭服务机器人、工业自动化、自动驾驶等领域。通过赋予机器人动态重规划能力,使其能够更好地适应复杂多变的环境,完成各种任务,提高工作效率和安全性。未来,LERa有望成为实现更智能、更自主机器人的关键技术。
📄 摘要(原文)
Large Language Models are increasingly used in robotics for task planning, but their reliance on textual inputs limits their adaptability to real-world changes and failures. To address these challenges, we propose LERa - Look, Explain, Replan - a Visual Language Model-based replanning approach that utilizes visual feedback. Unlike existing methods, LERa requires only a raw RGB image, a natural language instruction, an initial task plan, and failure detection - without additional information such as object detection or predefined conditions that may be unavailable in a given scenario. The replanning process consists of three steps: (i) Look - where LERa generates a scene description and identifies errors; (ii) Explain - where it provides corrective guidance; and (iii) Replan - where it modifies the plan accordingly. LERa is adaptable to various agent architectures and can handle errors from both dynamic scene changes and task execution failures. We evaluate LERa on the newly introduced ALFRED-ChaOS and VirtualHome-ChaOS datasets, achieving a 40% improvement over baselines in dynamic environments. In tabletop manipulation tasks with a predefined probability of task failure within the PyBullet simulator, LERa improves success rates by up to 67%. Further experiments, including real-world trials with a tabletop manipulator robot, confirm LERa's effectiveness in replanning. We demonstrate that LERa is a robust and adaptable solution for error-aware task execution in robotics. The project page is available at https://lera-robo.github.io.