DRAE: Dynamic Retrieval-Augmented Expert Networks for Lifelong Learning and Task Adaptation in Robotics
作者: Yayu Long, Kewei Chen, Long Jin, Mingsheng Shang
分类: cs.RO
发布日期: 2025-07-07 (更新: 2025-12-23)
备注: Accepted to the main conference of the Annual Meeting of the Association for Computational Linguistics (ACL 2025)
💡 一句话要点
提出动态检索增强专家网络DRAE,解决机器人终身学习和任务自适应问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 终身学习 机器人 任务自适应 混合专家网络 检索增强生成
📋 核心要点
- 现有方法在机器人终身学习中面临灾难性遗忘和任务自适应的挑战,难以有效利用过往经验。
- DRAE通过动态路由的专家网络、检索增强生成和分层强化学习框架,实现知识的有效积累和重用。
- 实验表明,DRAE在任务成功率和遗忘率方面均优于现有方法,提升了机器人终身学习能力。
📝 摘要(中文)
本文提出了一种名为动态检索增强专家网络(DRAE)的突破性架构,旨在解决终身学习、灾难性遗忘和任务自适应的挑战。DRAE结合了混合专家(MoE)的动态路由能力,利用检索增强生成(RAG)的知识增强能力,并融入了一种新颖的分层强化学习(RL)框架,通过ReflexNet-SchemaPlanner-HyperOptima(RSHO)进行协调。DRAE通过稀疏MoE门控机制动态路由专家模型,实现高效的资源分配,同时利用参数化检索(P-RAG)来增强学习过程。我们提出了一种新的RL框架,其中ReflexNet用于低级任务执行,SchemaPlanner用于符号推理,HyperOptima用于长期上下文建模,确保持续适应和记忆保持。实验结果表明,DRAE在长期任务保持和知识重用方面显著优于基线方法,在一组动态机器人操作任务中实现了82.5%的平均任务成功率,而传统MoE模型的成功率为74.2%。此外,DRAE保持了极低的遗忘率,在缓解灾难性遗忘方面优于最先进的方法。这些结果证明了我们的方法在为机器人技术实现灵活、可扩展和高效的终身学习方面的有效性。
🔬 方法详解
问题定义:论文旨在解决机器人终身学习过程中遇到的灾难性遗忘和任务自适应问题。现有的方法,如传统的混合专家网络(MoE),在面对不断变化的任务时,难以有效地保持和利用先前学习到的知识,导致性能下降。此外,如何将外部知识有效地融入到学习过程中也是一个挑战。
核心思路:DRAE的核心思路是结合MoE的动态路由能力、RAG的知识增强能力以及分层强化学习框架,构建一个能够持续学习、适应新任务并有效利用外部知识的机器人学习系统。通过动态路由,DRAE能够根据当前任务选择合适的专家模型;通过RAG,DRAE能够检索并利用外部知识来增强学习过程;通过分层强化学习,DRAE能够实现从低级动作到高级策略的有效学习和规划。
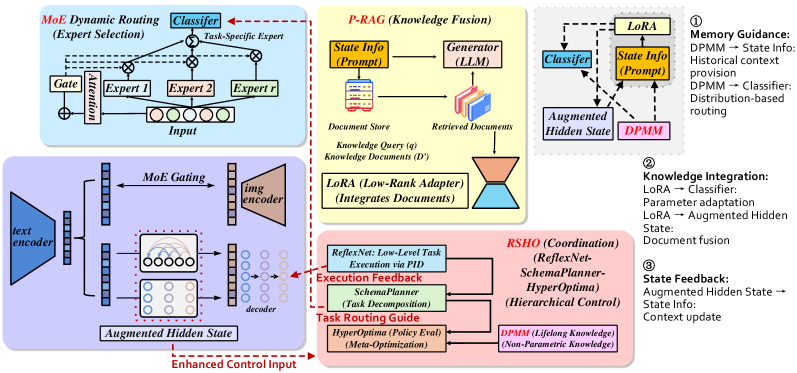
技术框架:DRAE的整体架构包含以下几个主要模块:1) 动态路由的混合专家网络(MoE):负责根据当前任务动态选择合适的专家模型。2) 检索增强生成(RAG):负责从外部知识库中检索相关知识,并将其融入到学习过程中。3) 分层强化学习框架:包含ReflexNet(用于低级任务执行)、SchemaPlanner(用于符号推理)和HyperOptima(用于长期上下文建模)。RSHO框架协调各个模块,实现持续适应和记忆保持。
关键创新:DRAE的关键创新在于将动态路由的MoE、RAG和分层强化学习框架相结合,形成一个完整的终身学习系统。与传统的MoE模型相比,DRAE能够更有效地利用外部知识,并更好地适应不断变化的任务。此外,DRAE的分层强化学习框架能够实现从低级动作到高级策略的有效学习和规划,从而提高机器人的整体性能。
关键设计:DRAE的关键设计包括:1) 稀疏MoE门控机制:用于动态路由专家模型,实现高效的资源分配。2) 参数化检索(P-RAG):用于从外部知识库中检索相关知识。3) ReflexNet-SchemaPlanner-HyperOptima(RSHO)框架:用于实现分层强化学习,其中ReflexNet负责低级任务执行,SchemaPlanner负责符号推理,HyperOptima负责长期上下文建模。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
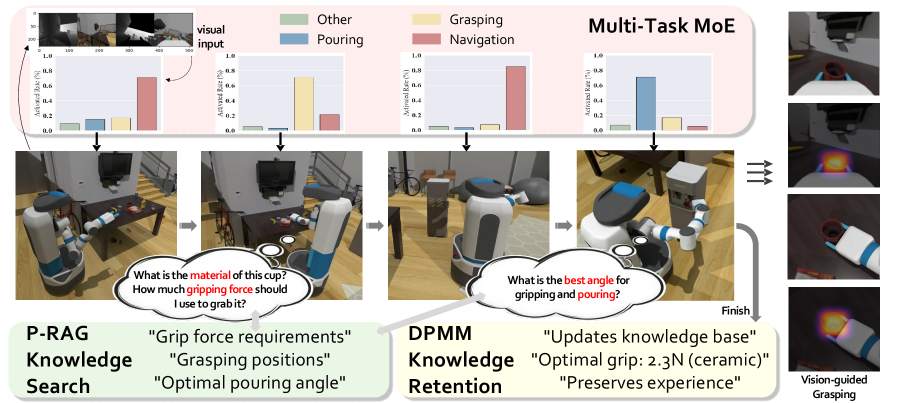
实验结果表明,DRAE在长期任务保持和知识重用方面显著优于基线方法,在一组动态机器人操作任务中实现了82.5%的平均任务成功率,而传统MoE模型的成功率为74.2%,提升了8.3%。此外,DRAE在缓解灾难性遗忘方面也优于现有方法,证明了其在终身学习方面的有效性。
🎯 应用场景
DRAE在机器人领域的应用前景广阔,可应用于家庭服务机器人、工业机器人、自动驾驶等场景。通过持续学习和任务自适应,机器人能够更好地适应复杂多变的环境,完成各种任务,提高工作效率和服务质量。该研究对于推动机器人智能化发展具有重要意义。
📄 摘要(原文)
We introduce Dynamic Retrieval-Augmented Expert Networks (DRAE), a groundbreaking architecture that addresses the challenges of lifelong learning, catastrophic forgetting, and task adaptation by combining the dynamic routing capabilities of Mixture-of-Experts (MoE); leveraging the knowledge-enhancement power of Retrieval-Augmented Generation (RAG); incorporating a novel hierarchical reinforcement learning (RL) framework; and coordinating through ReflexNet-SchemaPlanner-HyperOptima (RSHO).DRAE dynamically routes expert models via a sparse MoE gating mechanism, enabling efficient resource allocation while leveraging external knowledge through parametric retrieval (P-RAG) to augment the learning process. We propose a new RL framework with ReflexNet for low-level task execution, SchemaPlanner for symbolic reasoning, and HyperOptima for long-term context modeling, ensuring continuous adaptation and memory retention. Experimental results show that DRAE significantly outperforms baseline approaches in long-term task retention and knowledge reuse, achieving an average task success rate of 82.5% across a set of dynamic robotic manipulation tasks, compared to 74.2% for traditional MoE models. Furthermore, DRAE maintains an extremely low forgetting rate, outperforming state-of-the-art methods in catastrophic forgetting mitigation. These results demonstrate the effectiveness of our approach in enabling flexible, scalable, and efficient lifelong learning for robotics.