Wavelet Policy: Lifting Scheme for Policy Learning in Long-Horizon Tasks
作者: Hao Huang, Shuaihang Yuan, Geeta Chandra Raju Bethala, Congcong Wen, Anthony Tzes, Yi Fang
分类: cs.RO
发布日期: 2025-07-06
备注: 11 pages, 5 figures, 6 tables
💡 一句话要点
提出基于小波变换的策略学习框架,提升长时序任务中的策略精度与可靠性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 策略学习 小波变换 多尺度分析 长时序任务 机器人 自动驾驶 多智能体协作
📋 核心要点
- 现有策略学习方法在处理复杂长时序任务时,难以有效管理大量的动作和观测序列,尤其是在多模态情况下。
- 论文提出一种基于小波变换的策略学习框架,通过多尺度分解观测信息,提取全局趋势和精细细节,从而优化策略。
- 实验结果表明,该方法在机器人操作、自动驾驶和多机器人协作等任务中,能够提升学习策略的精度和可靠性。
📝 摘要(中文)
本文提出了一种新颖的小波策略学习框架,旨在提升策略学习在复杂、长时序任务中的性能。该框架利用小波变换,通过可学习的多尺度小波分解,实现对观测的精细分析和对长序列的稳健动作规划。具体而言,本文详细阐述了小波策略的设计与实现,其中融合了提升方案,以实现有效多分辨率分析和动作生成。在机器人操作、自动驾驶和多机器人协作等多个复杂场景下的评估结果表明,该方法能够有效提高学习策略的精度和可靠性。
🔬 方法详解
问题定义:策略学习旨在为具身智能系统中的智能体设计策略,使其能够基于感知到的状态执行最优动作。然而,处理复杂、长时序任务,特别是那些涉及大量动作和观测序列以及多种模式的任务,对现有的策略学习方法提出了挑战。现有的方法难以有效地提取和利用长时序数据中的关键信息,导致学习到的策略精度和可靠性不足。
核心思路:本文的核心思路是利用小波分析在信号处理方面的优势,特别是其多尺度分解能力,将观测信息分解成不同尺度的成分,从而捕捉全局趋势和精细细节。通过这种方式,策略学习算法可以更好地理解环境状态,并制定更有效的动作规划。这种设计借鉴了小波变换在处理非平稳信号方面的优势,使其能够适应复杂动态环境。
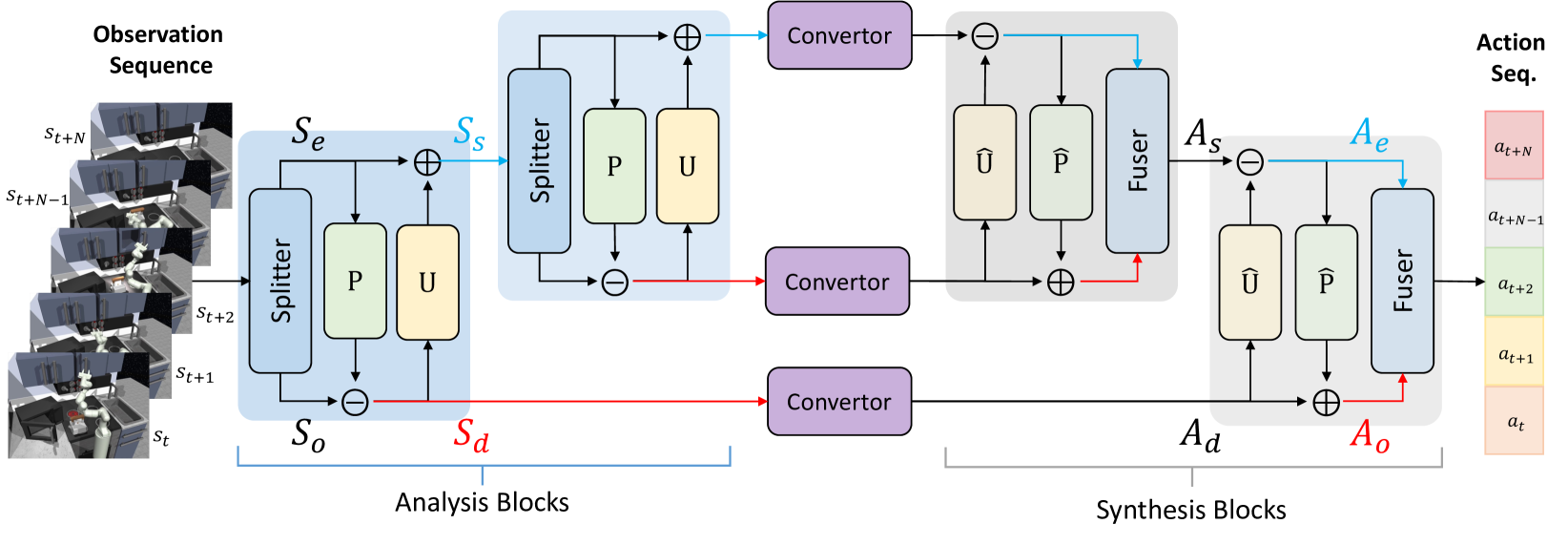
技术框架:该框架包含以下主要模块:1) 可学习的多尺度小波分解模块,用于将观测信息分解成不同尺度的成分;2) 策略网络,基于分解后的观测信息生成动作;3) 提升方案,用于优化小波分解过程,提高效率和精度。整体流程是:首先,利用小波分解模块对观测信息进行处理;然后,将分解后的信息输入策略网络,生成动作;最后,根据环境反馈调整策略网络和提升方案的参数。
关键创新:该方法最重要的技术创新点在于将小波变换引入策略学习领域,并设计了可学习的多尺度小波分解模块。与传统的策略学习方法相比,该方法能够更好地处理长时序数据,提取关键信息,并适应复杂动态环境。此外,利用提升方案优化小波分解过程,进一步提高了效率和精度。
关键设计:关键设计包括:1) 小波分解模块的网络结构,包括小波基函数的选择和参数化方式;2) 提升方案的优化目标和算法;3) 策略网络的结构和训练方法;4) 损失函数的设计,可能包括奖励最大化、动作平滑性约束等。具体的参数设置和网络结构需要在实际应用中进行调整和优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在机器人操作、自动驾驶和多机器人协作等多个复杂场景下,能够显著提高学习策略的精度和可靠性。具体的性能数据(例如,成功率、平均奖励等)以及与现有基线方法的对比结果(例如,提升幅度)需要在论文中查找。总体而言,实验结果验证了该方法在处理长时序任务方面的有效性。
🎯 应用场景
该研究成果可广泛应用于机器人、自动驾驶、智能制造等领域。通过提升策略学习的精度和可靠性,可以使智能体在复杂环境中更好地完成任务,例如,机器人可以更精确地执行操作任务,自动驾驶系统可以更安全地应对复杂的交通状况,智能制造系统可以更高效地优化生产流程。该研究还有助于推动人工智能技术在实际应用中的发展。
📄 摘要(原文)
Policy learning focuses on devising strategies for agents in embodied artificial intelligence systems to perform optimal actions based on their perceived states. One of the key challenges in policy learning involves handling complex, long-horizon tasks that require managing extensive sequences of actions and observations with multiple modes. Wavelet analysis offers significant advantages in signal processing, notably in decomposing signals at multiple scales to capture both global trends and fine-grained details. In this work, we introduce a novel wavelet policy learning framework that utilizes wavelet transformations to enhance policy learning. Our approach leverages learnable multi-scale wavelet decomposition to facilitate detailed observation analysis and robust action planning over extended sequences. We detail the design and implementation of our wavelet policy, which incorporates lifting schemes for effective multi-resolution analysis and action generation. This framework is evaluated across multiple complex scenarios, including robotic manipulation, self-driving, and multi-robot collaboration, demonstrating the effectiveness of our method in improving the precision and reliability of the learned policy.