cVLA: Towards Efficient Camera-Space VLAs
作者: Max Argus, Jelena Bratulic, Houman Masnavi, Maxim Velikanov, Nick Heppert, Abhinav Valada, Thomas Brox
分类: cs.RO, cs.LG
发布日期: 2025-07-02 (更新: 2025-12-20)
备注: 20 pages, 10 figures; CoRL 2025 Workshop on Generalizable Priors for Robot Manipulation
💡 一句话要点
提出cVLA,利用相机空间VLA高效解决机器人操作任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 相机空间 轨迹预测 深度学习
📋 核心要点
- 现有VLA模型训练成本高昂,限制了其在复杂机器人操作任务中的应用。
- 提出cVLA,利用VLM在2D图像上的能力,直接预测相机坐标系下的机器人末端执行器姿态。
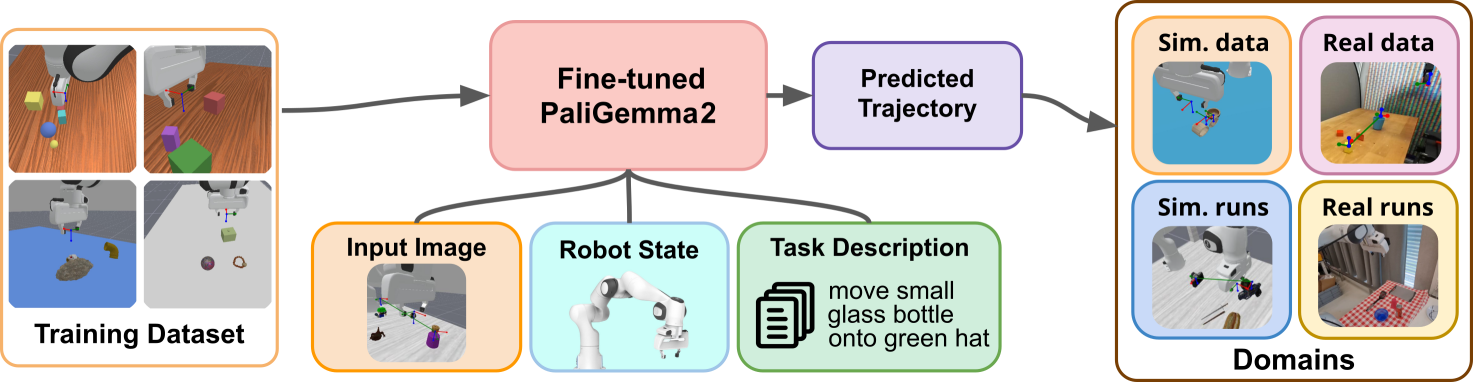
- 模型在模拟数据集上训练,并在真实机器人系统上验证,展示了良好的sim-to-real迁移能力。
📝 摘要(中文)
本文提出了一种新颖的视觉-语言-动作(VLA)方法,旨在解决机器人操作任务中VLA模型训练成本高昂的问题。该方法利用视觉语言模型(VLM)在2D图像上的卓越性能,直接推断图像坐标系中机器人末端执行器的姿态。与输出底层控制信号的传统VLA模型不同,我们的模型预测轨迹航点,从而提高了训练效率并实现了机器人本体的无关性。尽管设计轻量,但我们的next-token预测架构能够有效地学习有意义且可执行的机器人轨迹。我们进一步探索了深度图像的潜力,以及诸如解码策略和演示条件下的动作生成等推理时技术。我们的模型在模拟数据集上进行训练,并表现出强大的从模拟到真实的迁移能力。我们结合模拟和真实数据评估了我们的方法,证明了其在真实机器人系统上的有效性。
🔬 方法详解
问题定义:现有VLA模型通常输出底层控制信号,导致训练复杂且成本高昂,同时对特定机器人本体的依赖性较强。因此,需要一种更高效、更通用的VLA方法,能够降低训练成本,并实现跨不同机器人平台的迁移。
核心思路:论文的核心思路是利用预训练的视觉语言模型(VLM)在2D图像上的强大感知能力,直接预测机器人末端执行器在相机坐标系下的姿态。通过预测轨迹航点而非底层控制信号,降低了模型的复杂性,并实现了机器人本体的无关性。
技术框架:cVLA模型的整体框架包括视觉编码器、语言编码器和动作解码器。视觉编码器提取图像特征,语言编码器处理指令文本,动作解码器基于视觉和语言特征预测轨迹航点。模型采用next-token预测架构,逐步生成完整的机器人轨迹。
关键创新:该方法最重要的创新点在于将VLA问题转化为相机空间中的轨迹预测问题,并利用预训练的VLM作为视觉感知模块。与传统VLA模型相比,cVLA模型避免了复杂的底层控制信号学习,从而显著降低了训练成本,并提高了模型的泛化能力。
关键设计:模型采用Transformer架构作为动作解码器,使用交叉注意力机制融合视觉和语言特征。损失函数包括轨迹航点预测误差和动作序列的平滑性约束。论文还探索了深度图像的融合方法,以及诸如beam search等解码策略,以提高轨迹预测的准确性和鲁棒性。
🖼️ 关键图片

📊 实验亮点
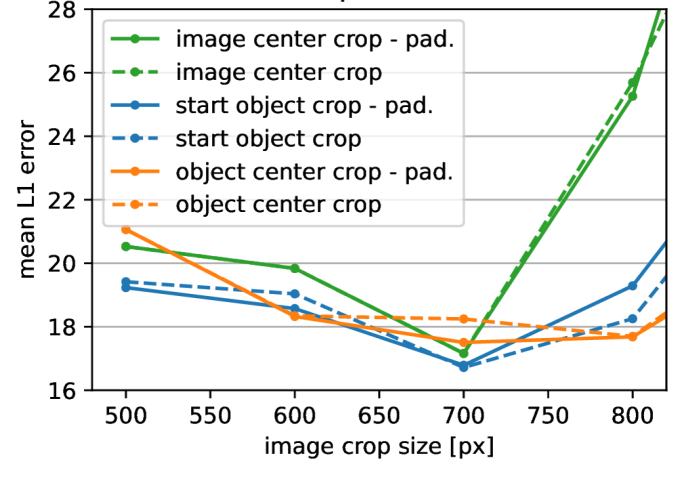
实验结果表明,cVLA模型在模拟和真实环境中均表现出良好的性能。在真实机器人系统上的实验表明,该模型能够成功完成多种操作任务,并且具有较强的鲁棒性和泛化能力。论文还展示了深度图像和解码策略对模型性能的提升效果。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过降低VLA模型的训练成本和提高泛化能力,可以加速机器人技术在工业自动化、家庭服务、医疗保健等领域的应用。未来,该方法有望扩展到更复杂的任务和环境,实现更智能、更灵活的机器人系统。
📄 摘要(原文)
Vision-Language-Action (VLA) models offer a compelling framework for tackling complex robotic manipulation tasks, but they are often expensive to train. In this paper, we propose a novel VLA approach that leverages the competitive performance of Vision Language Models (VLMs) on 2D images to directly infer robot end-effector poses in image frame coordinates. Unlike prior VLA models that output low-level controls, our model predicts trajectory waypoints, making it both more efficient to train and robot embodiment agnostic. Despite its lightweight design, our next-token prediction architecture effectively learns meaningful and executable robot trajectories. We further explore the underutilized potential of incorporating depth images, inference-time techniques such as decoding strategies, and demonstration-conditioned action generation. Our model is trained on a simulated dataset and exhibits strong sim-to-real transfer capabilities. We evaluate our approach using a combination of simulated and real data, demonstrating its effectiveness on a real robotic system.