RoboBrain 2.0 Technical Report
作者: BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Xiansheng Chen, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, Yi Han, Yingbo Tang, Xiangqi Xu, Wei Guo, Yaoxu Lyu, Yijie Xu, Jiayu Shi, Mengfei Du, Cheng Chi, Mengdi Zhao, Xiaoshuai Hao, Junkai Zhao, Xiaojie Zhang, Shanyu Rong, Huaihai Lyu, Zhengliang Cai, Yankai Fu, Ning Chen, Bolun Zhang, Lingfeng Zhang, Shuyi Zhang, Dong Liu, Xi Feng, Songjing Wang, Xiaodan Liu, Yance Jiao, Mengsi Lyu, Zhuo Chen, Chenrui He, Yulong Ao, Xue Sun, Zheqi He, Jingshu Zheng, Xi Yang, Donghai Shi, Kunchang Xie, Bochao Zhang, Shaokai Nie, Chunlei Men, Yonghua Lin, Zhongyuan Wang, Tiejun Huang, Shanghang Zhang
分类: cs.RO
发布日期: 2025-07-02 (更新: 2025-09-14)
💡 一句话要点
RoboBrain 2.0:用于具身智能的视觉-语言基础模型,统一感知、推理与规划
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言模型 机器人 感知 推理 规划 多模态学习
📋 核心要点
- 现有具身智能模型在统一感知、推理和规划方面存在挑战,难以应对复杂物理环境中的任务。
- RoboBrain 2.0通过异构架构的视觉-语言模型,结合多阶段训练策略,实现了感知、推理和规划的统一。
- 实验结果表明,RoboBrain 2.0在空间和时间基准测试中均取得了领先成果,超越了现有开源和商业模型。
📝 摘要(中文)
本文介绍了RoboBrain 2.0,这是我们最新一代的具身视觉-语言基础模型,旨在统一物理环境中复杂具身任务的感知、推理和规划。它有两个变体:一个轻量级的7B模型和一个完整规模的32B模型,采用具有视觉编码器和语言模型的异构架构。尽管尺寸紧凑,RoboBrain 2.0在各种具身推理任务中都表现出强大的性能。在空间和时间基准测试中,32B变体取得了领先的结果,超过了之前的开源和专有模型。特别地,它支持关键的现实世界具身AI能力,包括空间理解(例如,可供性预测、空间指代、轨迹预测)和时间决策(例如,闭环交互、多智能体长程规划和场景图更新)。本报告详细介绍了模型架构、数据构建、多阶段训练策略、基础设施和实际应用。我们希望RoboBrain 2.0能够推进具身AI研究,并成为构建通用具身智能体的一个实际步骤。代码、检查点和基准测试可在https://superrobobrain.github.io上找到。
🔬 方法详解
问题定义:现有具身智能模型难以有效整合感知、推理和规划能力,导致在复杂物理环境中执行任务时表现不佳。痛点在于缺乏一个能够同时理解视觉信息、进行逻辑推理并制定长期规划的统一模型。
核心思路:RoboBrain 2.0的核心思路是构建一个异构的视觉-语言基础模型,利用视觉编码器处理视觉输入,并使用语言模型进行推理和规划。通过多阶段训练,使模型能够学习到物理世界的空间和时间关系,从而实现更强的具身智能。
技术框架:RoboBrain 2.0采用异构架构,包含视觉编码器和语言模型两个主要模块。视觉编码器负责提取图像特征,语言模型负责进行推理和规划。模型训练分为多个阶段,包括预训练、指令微调和强化学习等。整个流程旨在使模型具备感知环境、理解指令、制定计划并执行动作的能力。
关键创新:RoboBrain 2.0的关键创新在于其异构架构和多阶段训练策略。异构架构允许模型同时处理视觉和语言信息,从而更好地理解环境。多阶段训练策略则使模型能够逐步学习到复杂的具身智能技能。
关键设计:模型包含7B和32B两种尺寸,以适应不同的计算资源需求。视觉编码器采用Transformer架构,语言模型采用自回归模型。损失函数包括交叉熵损失和强化学习奖励函数。训练数据包括图像、文本和动作序列等。
🖼️ 关键图片
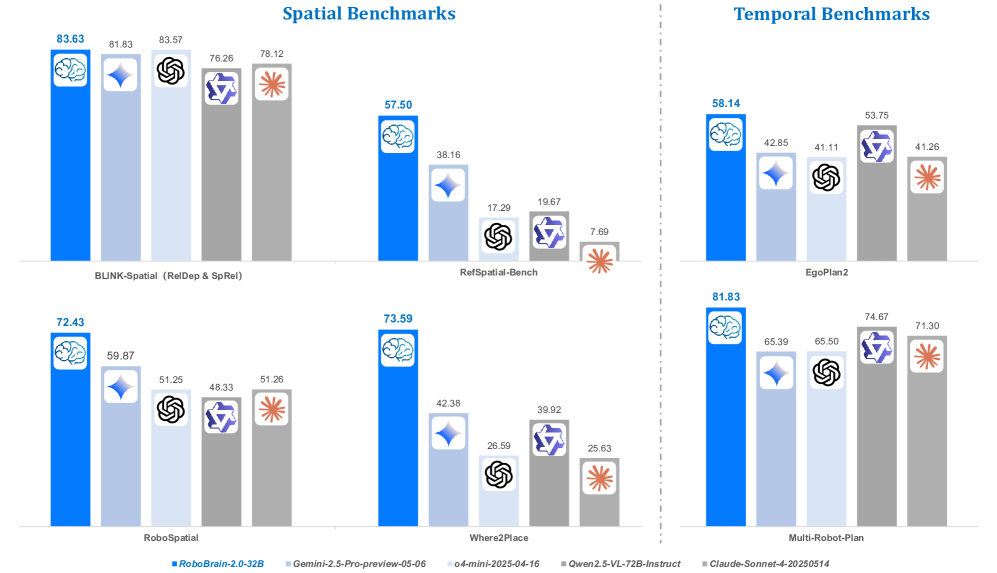
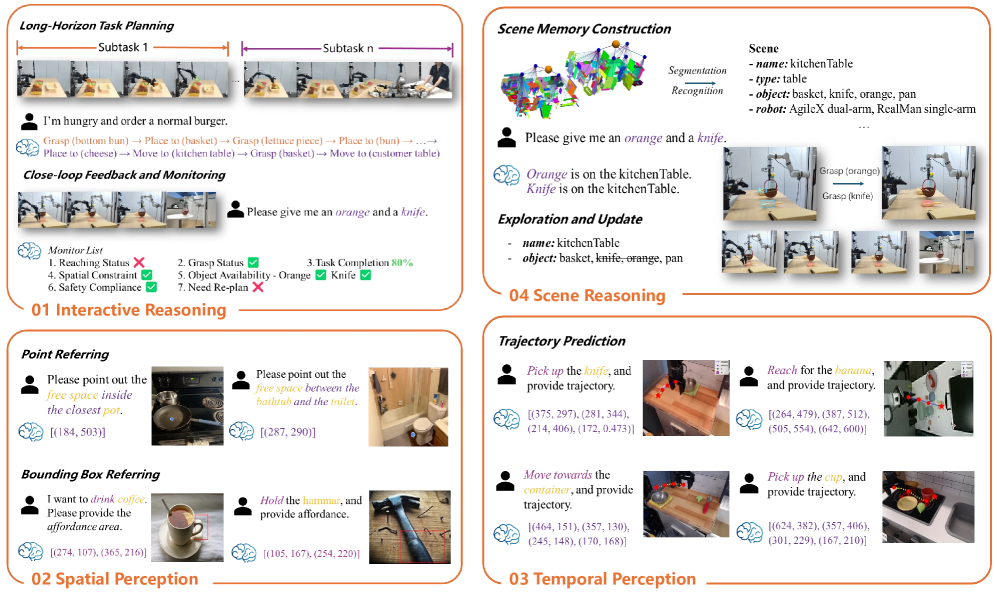
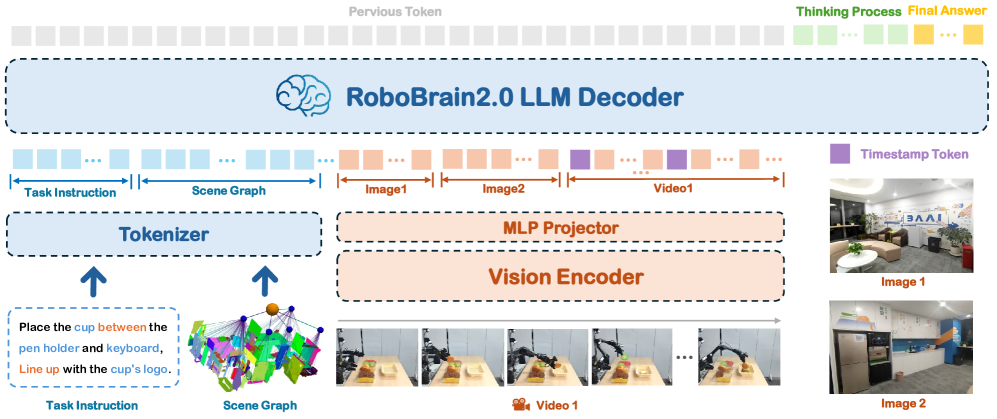
📊 实验亮点
RoboBrain 2.0在空间和时间基准测试中均取得了领先成果。32B模型在多个具身推理任务中超越了现有开源和商业模型,展现了强大的性能。尤其是在空间理解(如可供性预测)和时间决策(如多智能体长程规划)方面表现突出。
🎯 应用场景
RoboBrain 2.0可应用于机器人导航、物体操作、人机协作等领域。其潜在应用包括智能家居、自动驾驶、工业自动化等。该研究的实际价值在于提升机器人在复杂环境中的自主性和适应性,未来有望推动通用具身智能体的实现。
📄 摘要(原文)
We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.