AC-DiT: Adaptive Coordination Diffusion Transformer for Mobile Manipulation
作者: Sixiang Chen, Jiaming Liu, Siyuan Qian, Han Jiang, Lily Li, Renrui Zhang, Zhuoyang Liu, Chenyang Gu, Chengkai Hou, Pengwei Wang, Zhongyuan Wang, Shanghang Zhang
分类: cs.RO, cs.AI
发布日期: 2025-07-02 (更新: 2025-07-05)
备注: Project website: https://ac-dit.github.io/
💡 一句话要点
AC-DiT:自适应协调扩散Transformer,用于移动操作中的基座与机械臂协同控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动操作 扩散模型 Transformer 多模态融合 机器人控制
📋 核心要点
- 现有移动操作方法难以有效协调移动基座和机械臂,尤其是在高自由度下容易累积误差。
- AC-DiT通过移动性到身体的条件机制和感知感知的多模态融合策略,实现基座与机械臂的自适应协调控制。
- 实验结果表明,AC-DiT在模拟和真实环境的移动操作任务中均表现出优异的性能。
📝 摘要(中文)
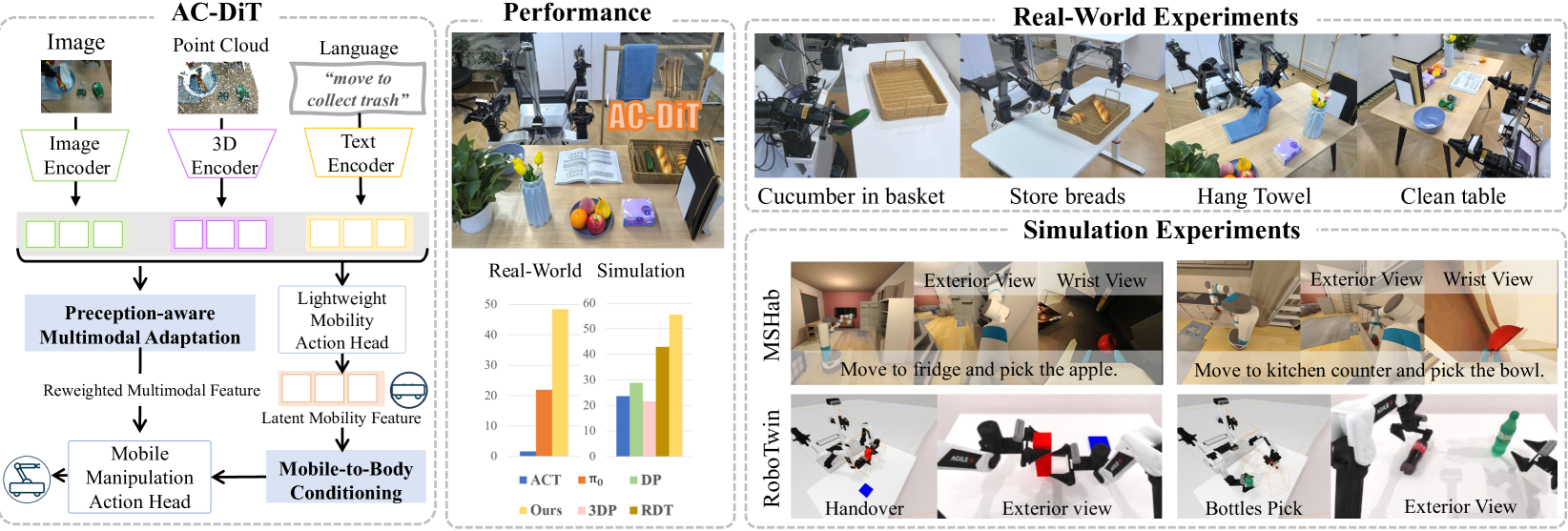
本文提出了一种自适应协调扩散Transformer(AC-DiT),旨在增强移动操作中移动基座和机械臂的协调性,实现端到端的控制。现有方法未能显式建模移动基座对机械臂控制的影响,导致高自由度下的误差累积,并且忽略了移动操作不同阶段对多模态感知的差异化需求。AC-DiT首先引入了一种移动性到身体的条件机制,引导模型先提取基座运动表征,并将其作为上下文先验来预测全身动作,从而实现考虑基座运动影响的全身控制。其次,设计了一种感知感知的多模态条件策略,动态调整2D图像和3D点云之间的融合权重,生成针对当前感知需求的视觉特征。通过在模拟和真实世界的移动操作任务上的大量实验验证了AC-DiT的有效性。
🔬 方法详解
问题定义:现有移动操作方法在协调移动基座和机械臂时存在两个主要痛点。一是未能显式建模移动基座对机械臂动作的影响,导致在高自由度下容易出现误差累积。二是忽略了移动操作不同阶段对视觉感知的不同需求,例如在某些阶段需要更强的语义信息,而在另一些阶段需要更精确的几何信息。
核心思路:AC-DiT的核心思路是通过解耦基座和机械臂的控制,并根据当前任务的感知需求动态调整视觉信息的融合方式,从而实现更有效的移动操作控制。具体来说,首先预测基座的运动,然后将基座运动作为先验信息来指导机械臂的动作规划。同时,根据任务需求动态调整2D图像和3D点云的融合权重,以获得最佳的视觉感知效果。
技术框架:AC-DiT的整体框架是一个基于Transformer的扩散模型。该模型包含两个主要模块:移动性到身体的条件模块和感知感知的多模态融合模块。移动性到身体的条件模块负责提取基座的运动表征,并将其作为上下文信息传递给机械臂的动作预测模块。感知感知的多模态融合模块负责根据当前任务的需求动态调整2D图像和3D点云的融合权重,生成适合当前任务的视觉特征。
关键创新:AC-DiT的关键创新在于其显式地建模了移动基座对机械臂动作的影响,并根据任务需求动态调整视觉信息的融合方式。与现有方法相比,AC-DiT能够更有效地协调移动基座和机械臂的动作,并能够更好地适应不同的感知需求。
关键设计:在移动性到身体的条件模块中,论文使用了一个Transformer编码器来提取基座的运动表征。在感知感知的多模态融合模块中,论文使用了一个注意力机制来动态调整2D图像和3D点云的融合权重。损失函数包括动作预测损失和扩散模型的重构损失。
🖼️ 关键图片


📊 实验亮点
AC-DiT在模拟和真实世界的移动操作任务中都取得了显著的性能提升。在模拟环境中,AC-DiT在多个任务上的成功率超过了现有基线方法。在真实世界中,AC-DiT也能够成功完成一些复杂的移动操作任务,例如在桌子上放置物体、从抽屉里取出物体等。实验结果表明,AC-DiT能够有效地协调移动基座和机械臂的动作,并能够适应不同的感知需求。
🎯 应用场景
AC-DiT在家庭服务机器人、仓库自动化、医疗辅助等领域具有广泛的应用前景。它可以使机器人更有效地完成各种复杂的移动操作任务,例如在拥挤的环境中导航、抓取物体、进行装配等。该研究的成果将推动移动操作技术的发展,并为机器人应用于更多实际场景提供可能。
📄 摘要(原文)
Recently, mobile manipulation has attracted increasing attention for enabling language-conditioned robotic control in household tasks. However, existing methods still face challenges in coordinating mobile base and manipulator, primarily due to two limitations. On the one hand, they fail to explicitly model the influence of the mobile base on manipulator control, which easily leads to error accumulation under high degrees of freedom. On the other hand, they treat the entire mobile manipulation process with the same visual observation modality (e.g., either all 2D or all 3D), overlooking the distinct multimodal perception requirements at different stages during mobile manipulation. To address this, we propose the Adaptive Coordination Diffusion Transformer (AC-DiT), which enhances mobile base and manipulator coordination for end-to-end mobile manipulation. First, since the motion of the mobile base directly influences the manipulator's actions, we introduce a mobility-to-body conditioning mechanism that guides the model to first extract base motion representations, which are then used as context prior for predicting whole-body actions. This enables whole-body control that accounts for the potential impact of the mobile base's motion. Second, to meet the perception requirements at different stages of mobile manipulation, we design a perception-aware multimodal conditioning strategy that dynamically adjusts the fusion weights between various 2D visual images and 3D point clouds, yielding visual features tailored to the current perceptual needs. This allows the model to, for example, adaptively rely more on 2D inputs when semantic information is crucial for action prediction, while placing greater emphasis on 3D geometric information when precise spatial understanding is required. We validate AC-DiT through extensive experiments on both simulated and real-world mobile manipulation tasks.