A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
作者: Yifan Zhong, Fengshuo Bai, Shaofei Cai, Xuchuan Huang, Zhang Chen, Xiaowei Zhang, Yuanfei Wang, Shaoyang Guo, Tianrui Guan, Ka Nam Lui, Zhiquan Qi, Yitao Liang, Yuanpei Chen, Yaodong Yang
分类: cs.RO
发布日期: 2025-07-02
备注: 70 pages, 5 figures
💡 一句话要点
对视觉-语言-动作模型进行综述,以动作Token化视角统一现有方法。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 动作Token化 多模态学习 机器人 具身智能
📋 核心要点
- 现有VLA模型方法多样,缺乏统一框架,阻碍了有效开发和未来方向的探索。
- 论文提出以动作Token化视角统一VLA模型,将不同方法归纳为生成不同类型的动作Token。
- 通过分析不同动作Token的优缺点,为VLA模型的发展提供指导,并展望未来研究方向。
📝 摘要(中文)
视觉和语言基础模型在多模态理解、推理和生成方面的显著进步,激发了人们将这种智能扩展到物理世界的努力,从而推动了视觉-语言-动作(VLA)模型的蓬勃发展。尽管方法看似多种多样,但我们观察到,当前的VLA模型可以在一个统一的框架下进行整合:视觉和语言输入由一系列VLA模块处理,产生一系列动作Token,这些Token逐步编码更具实际意义和可操作性的信息,最终生成可执行的动作。我们进一步确定,区分VLA模型的主要设计选择在于如何制定动作Token,这可以分为语言描述、代码、可供性、轨迹、目标状态、潜在表示、原始动作和推理。然而,目前对动作Token的理解仍然不足,这严重阻碍了有效的VLA开发,并模糊了未来的方向。因此,本综述旨在通过动作Token化的视角对现有的VLA研究进行分类和解释,提炼每种Token类型的优点和局限性,并确定需要改进的领域。通过这种系统的回顾和分析,我们对VLA模型的更广泛演变提供了一个综合的展望,强调了尚未充分探索但有希望的方向,并为未来的研究贡献指导,希望使该领域更接近通用智能。
🔬 方法详解
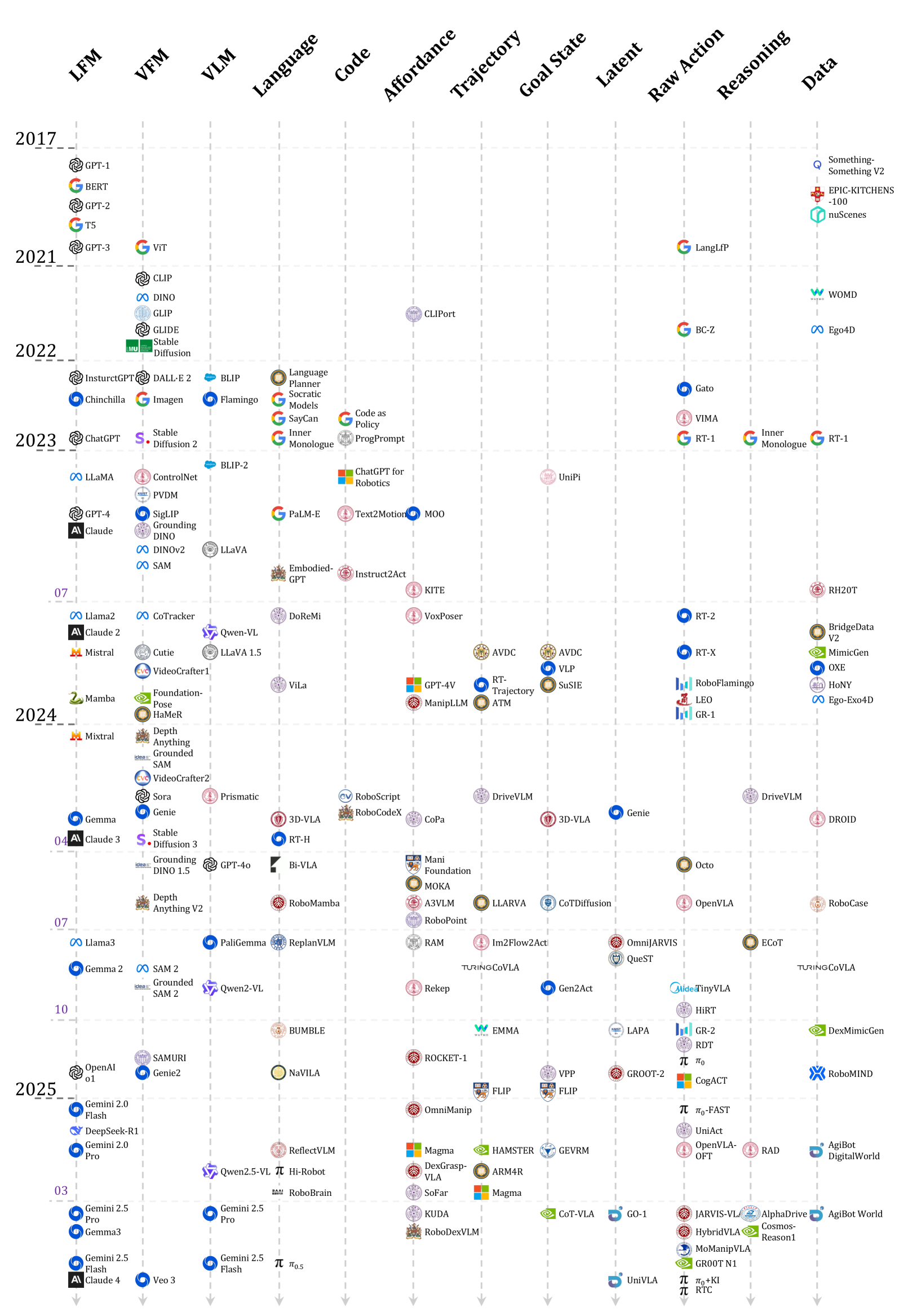
问题定义:现有视觉-语言-动作(VLA)模型方法繁多,缺乏统一的理论框架,导致研究人员难以理解不同方法之间的联系和差异,阻碍了VLA模型的有效开发和未来发展方向的探索。现有方法在动作表示方式上存在差异,如何选择合适的动作表示方式是一个关键问题。
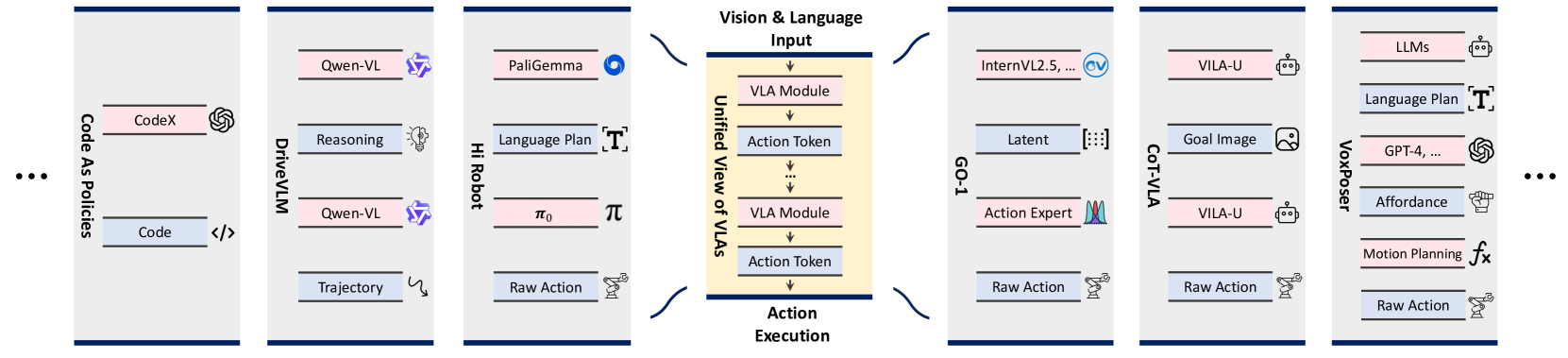
核心思路:论文的核心思路是将现有的VLA模型统一到一个框架下,即视觉和语言输入经过一系列VLA模块处理后,生成一系列动作Token。这些动作Token逐步编码更具实际意义和可操作性的信息,最终生成可执行的动作。通过分析不同VLA模型中动作Token的类型,可以更好地理解不同方法之间的差异和联系。
技术框架:该综述论文并没有提出新的技术框架,而是对现有VLA模型进行分类和分析。其核心在于将VLA模型分解为三个阶段:视觉和语言输入处理、动作Token生成和动作执行。重点关注动作Token的生成方式,并将其分为语言描述、代码、可供性、轨迹、目标状态、潜在表示、原始动作和推理等不同类型。
关键创新:该论文的创新之处在于提出了动作Token化的视角,将不同的VLA模型统一到一个框架下进行分析。通过这种方式,可以更好地理解不同方法之间的联系和差异,并为未来的研究提供指导。这种统一的视角有助于研究人员更好地理解VLA模型,并开发更有效的模型。
关键设计:该论文并没有提出新的模型或算法,因此没有具体的参数设置、损失函数或网络结构等技术细节。其关键在于对现有VLA模型进行分类和分析,并总结不同动作Token类型的优缺点。例如,语言描述类型的动作Token易于理解和生成,但可能不够精确;而原始动作类型的动作Token则更加精确,但可能难以生成。
🖼️ 关键图片

📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。其亮点在于提出了动作Token化的视角,对现有VLA模型进行了系统的分类和分析,并总结了不同动作Token类型的优缺点。该综述为VLA领域的研究人员提供了一个有价值的参考,并为未来的研究方向提供了指导。
🎯 应用场景
该研究对机器人、自动驾驶、智能家居等领域具有潜在应用价值。通过对VLA模型的深入理解,可以开发出更智能、更可靠的机器人系统,使其能够更好地理解人类指令,并在复杂环境中执行任务。未来的研究可以集中在如何结合不同类型的动作Token,以实现更高效、更灵活的VLA模型。
📄 摘要(原文)
The remarkable advancements of vision and language foundation models in multimodal understanding, reasoning, and generation has sparked growing efforts to extend such intelligence to the physical world, fueling the flourishing of vision-language-action (VLA) models. Despite seemingly diverse approaches, we observe that current VLA models can be unified under a single framework: vision and language inputs are processed by a series of VLA modules, producing a chain of \textit{action tokens} that progressively encode more grounded and actionable information, ultimately generating executable actions. We further determine that the primary design choice distinguishing VLA models lies in how action tokens are formulated, which can be categorized into language description, code, affordance, trajectory, goal state, latent representation, raw action, and reasoning. However, there remains a lack of comprehensive understanding regarding action tokens, significantly impeding effective VLA development and obscuring future directions. Therefore, this survey aims to categorize and interpret existing VLA research through the lens of action tokenization, distill the strengths and limitations of each token type, and identify areas for improvement. Through this systematic review and analysis, we offer a synthesized outlook on the broader evolution of VLA models, highlight underexplored yet promising directions, and contribute guidance for future research, hoping to bring the field closer to general-purpose intelligence.