TriVLA: A Triple-System-Based Unified Vision-Language-Action Model with Episodic World Modeling for General Robot Control
作者: Zhenyang Liu, Yongchong Gu, Sixiao Zheng, Yanwei Fu, Xiangyang Xue, Yu-Gang Jiang
分类: cs.RO
发布日期: 2025-07-02 (更新: 2025-10-13)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
TriVLA:基于三重系统的统一视觉-语言-动作模型,用于通用机器人控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人控制 情景世界模型 长程规划 多模态融合 视频扩散模型 具身智能
📋 核心要点
- 现有VLA框架依赖静态表示和有限时间上下文,导致机器人只能进行短视行为,泛化能力受限。
- TriVLA提出基于三重系统的统一模型,通过情景世界模型积累、回忆和预测序列经验。
- 实验表明,TriVLA在标准基准和真实操作任务中优于基线模型,展示了长程规划和意图理解能力。
📝 摘要(中文)
视觉-语言模型(VLM)的最新进展使机器人能够遵循开放式指令并展示出令人印象深刻的常识推理能力。然而,当前的视觉-语言-动作(VLA)框架主要依赖于静态表示和有限的时间上下文,这限制了智能体在动态具身环境中进行短视、反应性行为,并阻碍了鲁棒的泛化能力。受到情景记忆认知神经科学理论的启发,我们提出了据我们所知,VLA中首批形式化的情景世界模型之一,使具身机器人能够积累、回忆和预测顺序经验。作为这一概念的实例化,我们的统一TriVLA通过三重系统架构实现情景世界模型:整合来自预训练VLM的多模态基础(系统2)和来自视频扩散模型的时间丰富的动态感知(系统3)。这使得智能体能够积累和回忆顺序经验,解释当前上下文,并预测未来的环境演变。在跨越过去和预期未来的情景表示的指导下,下游策略(系统1)通过流匹配和跨模态注意力机制生成连贯的、上下文感知的动作序列。实验结果表明,TriVLA以大约36 Hz的效率运行,并且在标准基准和具有挑战性的真实世界操作任务中始终优于基线模型。它展示了强大的长程规划和开放式意图理解能力,展示了情景世界模型启发式推理对于鲁棒、可泛化的机器人智能的优势。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)框架在处理动态具身环境中的长程规划和开放式意图理解方面存在局限性。它们主要依赖于静态表示和有限的时间上下文,无法有效地积累、回忆和预测顺序经验,导致机器人只能进行短视、反应性行为,并且泛化能力较差。
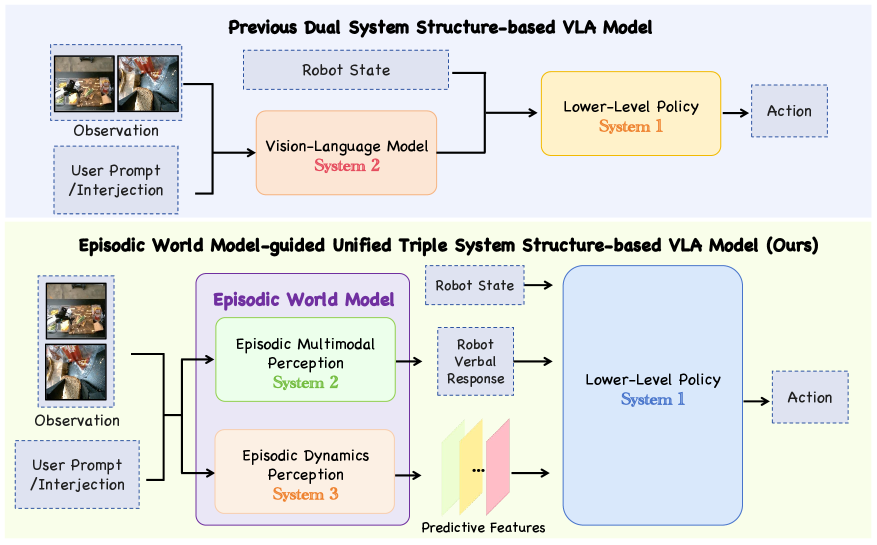
核心思路:TriVLA的核心思路是引入情景世界模型,使机器人能够像人类一样,通过积累、回忆和预测顺序经验来理解环境并做出决策。该模型受到认知神经科学中情景记忆理论的启发,旨在赋予机器人更强的上下文感知能力和长程规划能力。通过整合多模态信息和时间动态感知,TriVLA能够更好地理解当前环境,预测未来发展,并生成连贯的动作序列。
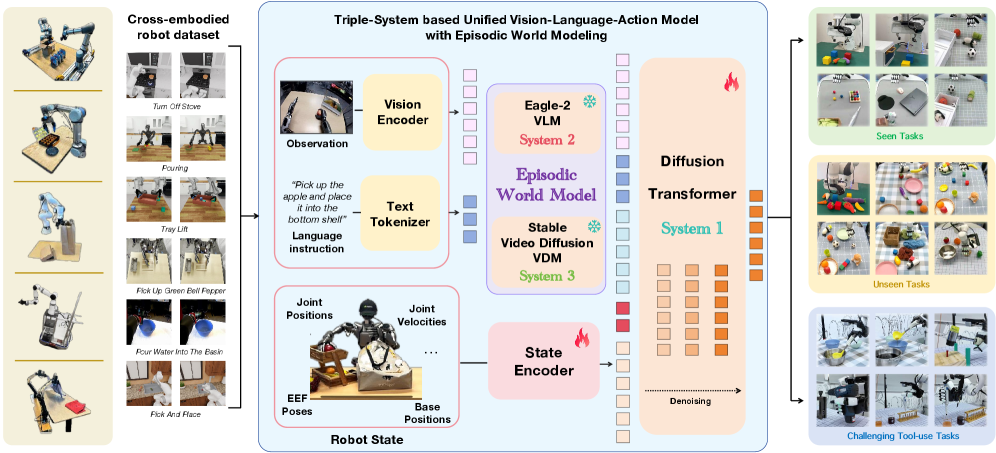
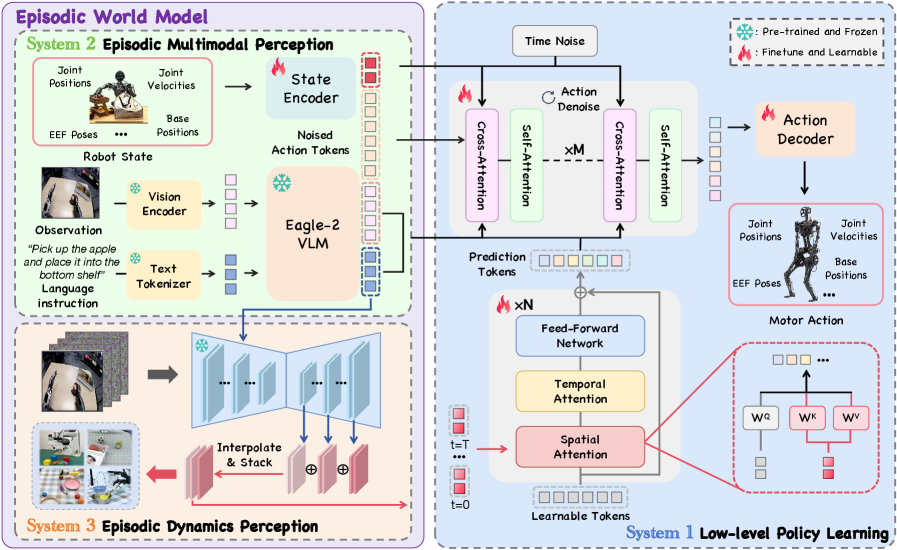
技术框架:TriVLA采用三重系统架构来实现情景世界模型。系统1是下游策略,负责生成动作序列;系统2是预训练的视觉-语言模型(VLM),负责多模态基础;系统3是视频扩散模型,负责时间丰富的动态感知。整个流程如下:首先,系统2和系统3分别处理视觉和语言输入,提取多模态特征和时间动态信息。然后,这些信息被整合到情景世界模型中,形成对过去经验和未来预测的表示。最后,系统1利用这些情景表示,通过流匹配和跨模态注意力机制生成上下文感知的动作序列。
关键创新:TriVLA最重要的技术创新点在于其形式化的情景世界模型在VLA中的应用。与以往依赖静态表示的方法不同,TriVLA能够积累、回忆和预测顺序经验,从而更好地理解环境并做出决策。此外,三重系统架构的整合也使得TriVLA能够有效地利用多模态信息和时间动态信息,从而提高了其感知和推理能力。
关键设计:TriVLA的关键设计包括:1) 使用预训练的VLM作为系统2,以利用其强大的多模态理解能力;2) 使用视频扩散模型作为系统3,以捕捉时间动态信息;3) 使用流匹配和跨模态注意力机制,以生成连贯的动作序列;4) 采用特定的损失函数来训练情景世界模型,使其能够准确地积累、回忆和预测顺序经验。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
TriVLA在标准基准和真实世界操作任务中均取得了显著的性能提升。实验结果表明,TriVLA能够以大约36 Hz的效率运行,并且在长程规划和开放式意图理解方面优于基线模型。具体而言,TriVLA在多个任务上的成功率和效率均得到了显著提高,证明了其情景世界模型启发式推理的有效性。
🎯 应用场景
TriVLA具有广泛的应用前景,可应用于家庭服务机器人、工业自动化、医疗辅助机器人等领域。该模型能够使机器人在复杂、动态的环境中执行长程规划任务,例如完成复杂的家务、进行精细的工业操作、辅助医生进行手术等。通过提高机器人的智能水平和泛化能力,TriVLA有望推动机器人技术的发展,并为人类生活带来便利。
📄 摘要(原文)
Recent advances in vision-language models (VLMs) have enabled robots to follow open-ended instructions and demonstrate impressive commonsense reasoning. However, current vision-language-action (VLA) frameworks primarily rely on static representations and limited temporal context, restricting agents to short-horizon, reactive behaviors and hindering robust generalization in dynamic embodied environments. Inspired by cognitive neuroscience theories of episodic memory, we propose, to our knowledge, one of the first formalized episodic world models in VLA, enabling embodied robots to accumulate, recall, and predict sequential experiences. As an instantiation of this concept, our unified TriVLA realizes the episodic world model through a triple-system architecture: integrating multimodal grounding from a pretrained VLM (System 2) and temporally rich dynamics perception from a video diffusion model (System 3). This enables the agent to accumulate and recall sequential experiences, interpret current contexts, and predict future environmental evolution. Guided by episodic representations that span both the past and anticipated future, the downstream policy (System 1) generates coherent, context-aware action sequences through flow-matching and cross-modal attention mechanisms. Experimental results show that TriVLA operates efficiently at approximately 36 Hz and consistently outperforms baseline models on standard benchmarks and challenging real-world manipulation tasks. It demonstrates strong long-horizon planning and open-ended intent understanding, showcasing the advantages of episodic world model-inspired reasoning for robust, generalizable robot intelligence. Project Page: https://zhenyangliu.github.io/TriVLA/.