Evo-0: Vision-Language-Action Model with Implicit Spatial Understanding
作者: Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, Bo Zhao
分类: cs.RO, cs.CV
发布日期: 2025-07-01 (更新: 2025-11-24)
💡 一句话要点
Evo-0:提出一种隐式空间理解的视觉-语言-动作模型,提升机器人操作能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 空间理解 机器人操作 视觉几何 深度感知
📋 核心要点
- 现有VLA模型依赖的VLM缺乏精确的空间理解能力,限制了其在复杂空间任务中的表现。
- Evo-0通过集成视觉几何基础模型,隐式地将3D几何特征融入VLA模型,无需额外深度传感器。
- 实验表明,Evo-0显著提升了VLA模型在模拟和现实世界空间挑战性任务中的性能。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为一种有前景的框架,能够使通用机器人感知、推理并在现实世界中行动。这些模型通常建立在预训练的视觉-语言模型(VLM)之上,这些模型擅长语义理解,这得益于大规模的图像和文本预训练。然而,现有的VLM通常缺乏精确的空间理解能力,因为它们主要在没有3D监督的2D图像-文本对上进行调整。为了解决这个限制,最近的方法已经结合了显式的3D输入,如点云或深度图,但这需要额外的深度传感器或预训练的深度估计模型,这可能会产生有缺陷的结果。相比之下,我们的工作引入了一个即插即用的模块,通过利用现成的视觉几何基础模型,将3D几何特征隐式地融入到VLA模型中。这种集成使模型能够获得深度感知的视觉表示,从而提高其仅从RGB图像理解场景的几何结构和对象之间的空间关系的能力。我们在模拟和现实世界中的一组空间挑战性任务中评估了我们的方法。广泛的评估表明,我们的方法显著提高了最先进的VLA模型在各种场景中的性能。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型,特别是那些基于预训练视觉-语言模型(VLM)的,在空间理解方面存在不足。它们主要依赖2D图像-文本对进行训练,缺乏对3D几何结构的感知能力。这限制了它们在需要精确空间推理的任务中的表现,例如机器人操作。
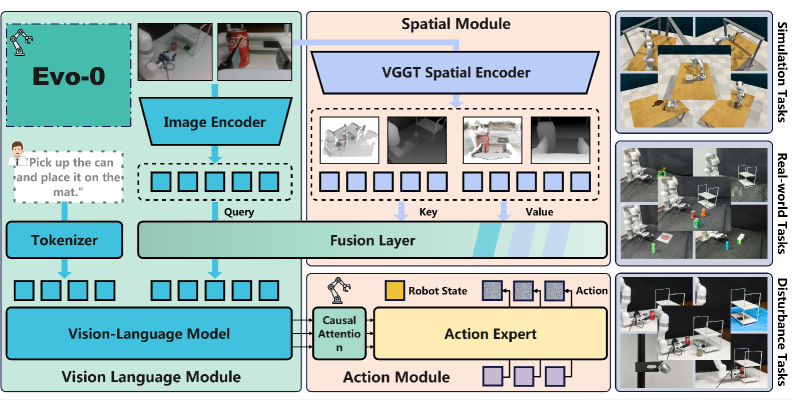
核心思路:Evo-0的核心思路是利用现成的视觉几何基础模型,提取图像中的3D几何信息,并将其隐式地融入到VLA模型中。通过这种方式,模型可以获得深度感知的视觉表示,从而提高其空间理解能力。这种方法避免了使用额外的深度传感器或预训练深度估计模型,降低了成本和复杂性。
技术框架:Evo-0采用即插即用的模块化设计,可以轻松地集成到现有的VLA模型中。该模块利用视觉几何基础模型提取图像的几何特征,然后将这些特征与VLA模型的视觉特征进行融合。融合后的特征被用于后续的动作预测或决策。
关键创新:Evo-0的关键创新在于其隐式空间理解方法。与需要显式3D输入(如点云或深度图)的方法不同,Evo-0仅使用RGB图像即可获得深度感知的视觉表示。这使得Evo-0更加灵活和通用,可以应用于各种场景。
关键设计:Evo-0的关键设计包括选择合适的视觉几何基础模型,以及设计有效的特征融合机制。论文中使用了“off-the-shelf visual geometry foundation model”,具体模型未知。特征融合的具体方式也未知,但需要保证几何特征能够有效地增强VLA模型的视觉表示。
🖼️ 关键图片

📊 实验亮点
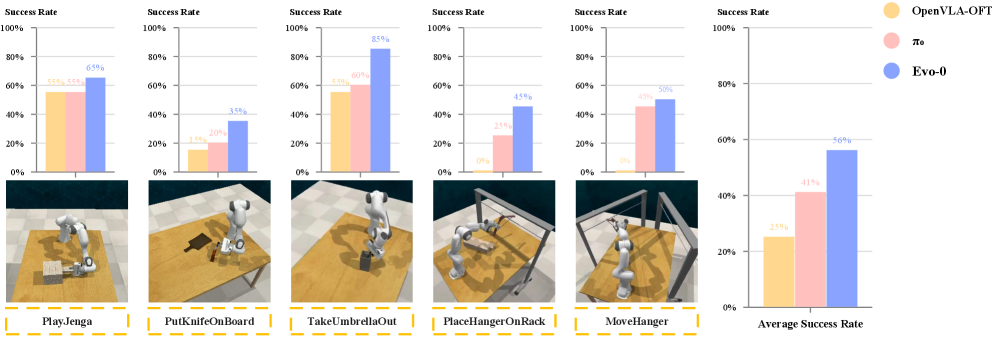
论文在模拟和真实世界的空间挑战性任务中评估了Evo-0的性能。实验结果表明,Evo-0显著提高了现有VLA模型的性能。具体的性能提升数据未知,但论文强调了Evo-0在各种场景下的有效性,证明了其隐式空间理解方法的优越性。
🎯 应用场景
Evo-0具有广泛的应用前景,可用于提升机器人在各种场景下的操作能力,例如家庭服务机器人、工业机器人和自动驾驶汽车。通过提高机器人对环境的理解和推理能力,Evo-0可以使机器人更安全、更高效地完成各种任务,例如物体抓取、导航和人机交互。未来,该技术有望推动机器人技术的进一步发展。
📄 摘要(原文)
Vision-Language-Action (VLA) models have emerged as a promising framework for enabling generalist robots capable of perceiving, reasoning, and acting in the real world. These models usually build upon pretrained Vision-Language Models (VLMs), which excel at semantic understanding due to large-scale image and text pretraining. However, existing VLMs typically lack precise spatial understanding capabilities, as they are primarily tuned on 2D image-text pairs without 3D supervision. To address this limitation, recent approaches have incorporated explicit 3D inputs such as point clouds or depth maps, but this necessitates additional depth sensors or pre-trained depth estimation models, which may yield defective results. In contrast, our work introduces a plug-and-play module that implicitly incorporates 3D geometry features into VLA models by leveraging an off-the-shelf visual geometry foundation model. This integration provides the model with depth-aware visual representations, improving its ability to understand the geometric structure of the scene and the spatial relationships among objects from RGB images alone. We evaluate our method on a set of spatially challenging tasks in both simulation and the real world. Extensive evaluations show that our method significantly improves the performance of state-of-the-art VLA models across diverse scenarios.