RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation
作者: Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, Si Liu
分类: cs.RO, cs.CV
发布日期: 2025-06-07 (更新: 2025-10-29)
备注: 25 pages, 18 figures, Accepted by NeurIPS 2025
💡 一句话要点
RoboCerebra:用于长时程机器人操作评估的大规模基准测试
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 长时程规划 视觉语言模型 基准测试 模拟环境
📋 核心要点
- 现有机器人操作benchmark在时间尺度和结构复杂性上存在局限,难以评估VLM在长时程规划中的高级推理能力。
- RoboCerebra通过构建大规模模拟数据集,结合分层框架和评估协议,来评估机器人在长时程任务中的规划、反思和记忆能力。
- 实验表明,RoboCerebra能够有效评估现有VLM在长时程机器人操作任务中的性能,并为未来研究提供基准。
📝 摘要(中文)
视觉语言模型(VLMs)的最新进展使得指令控制的机器人系统具有更好的泛化能力。然而,现有工作大多集中于反应式的System 1策略,未能充分利用VLMs在语义推理和长时程规划方面的优势。由于当前基准测试的时间尺度和结构复杂性有限,这些以审慎的、目标导向的思维为特征的System 2能力仍未得到充分探索。为了解决这一差距,我们引入了RoboCerebra,这是一个用于评估长时程机器人操作中高级推理的基准。RoboCerebra包括:(1)一个大规模的模拟数据集,具有扩展的任务时程和家庭环境中的多样化子任务序列;(2)一个分层框架,将高级VLM规划器与低级视觉-语言-动作(VLA)控制器相结合;(3)一个通过结构化的System 1-System 2交互来针对规划、反思和记忆的评估协议。该数据集通过自顶向下的流程构建,其中GPT生成任务指令并将其分解为子任务序列。人类操作员在模拟中执行子任务,产生具有动态对象变化的高质量轨迹。与之前的基准相比,RoboCerebra具有显著更长的动作序列和更密集的注释。我们进一步将最先进的VLMs作为System 2模块进行基准测试,并分析它们在关键认知维度上的性能,从而推进更强大和更具泛化能力的机器人规划器的开发。
🔬 方法详解
问题定义:现有机器人操作任务的benchmark通常任务周期短,结构简单,难以评估视觉语言模型(VLM)在长时程规划和高级推理方面的能力。现有的方法无法充分利用VLM在语义理解和规划方面的潜力,限制了机器人操作的泛化能力。
核心思路:RoboCerebra的核心思路是构建一个大规模、长时程的机器人操作benchmark,并设计相应的评估协议,以系统地评估VLM在规划、反思和记忆等认知维度上的表现。通过模拟真实世界的家庭环境,并引入动态的对象变化,提高benchmark的真实性和挑战性。
技术框架:RoboCerebra包含三个主要组成部分:大规模模拟数据集、分层框架和评估协议。数据集通过GPT生成任务指令,并由人工操作员执行子任务生成高质量轨迹。分层框架包括一个高级VLM规划器和一个低级视觉-语言-动作(VLA)控制器。评估协议通过结构化的System 1-System 2交互来评估规划、反思和记忆能力。
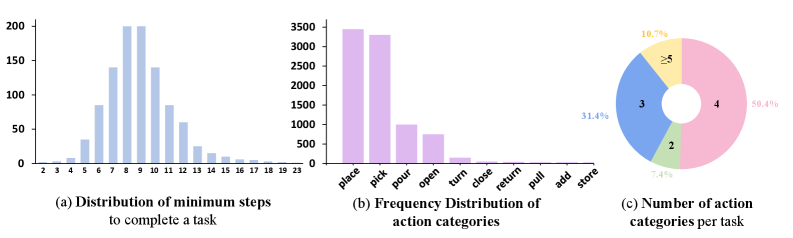
关键创新:RoboCerebra的关键创新在于其长时程的任务设计和对System 2能力的关注。与现有benchmark相比,RoboCerebra具有更长的动作序列和更密集的注释,能够更全面地评估VLM在复杂任务中的表现。此外,RoboCerebra的分层框架和评估协议为研究人员提供了一个系统的方法来开发和评估更强大的机器人规划器。
关键设计:数据集的构建采用了自顶向下的方法,首先由GPT生成高层任务指令,然后将任务分解为子任务序列。人工操作员在模拟环境中执行这些子任务,并记录下高质量的轨迹数据。分层框架中的VLM规划器负责生成高层动作序列,而VLA控制器则负责执行这些动作。评估协议设计了一系列指标来衡量机器人在规划、反思和记忆方面的表现。
🖼️ 关键图片


📊 实验亮点
RoboCerebra数据集包含比现有benchmark更长的动作序列和更密集的注释,为长时程机器人操作任务提供了更具挑战性的评估平台。实验结果表明,现有VLM在RoboCerebra上的表现仍有提升空间,表明该benchmark能够有效区分不同VLM的性能,并为未来的研究方向提供指导。
🎯 应用场景
RoboCerebra可应用于开发更智能、更通用的家庭服务机器人。通过提高机器人在长时程任务中的规划和推理能力,可以使其更好地理解人类指令,完成更复杂的家务任务,例如整理房间、准备食物等。此外,该benchmark还可以促进VLM在机器人领域的应用,推动机器人技术的进步。
📄 摘要(原文)
Recent advances in vision-language models (VLMs) have enabled instruction-conditioned robotic systems with improved generalization. However, most existing work focuses on reactive System 1 policies, underutilizing VLMs' strengths in semantic reasoning and long-horizon planning. These System 2 capabilities-characterized by deliberative, goal-directed thinking-remain under explored due to the limited temporal scale and structural complexity of current benchmarks. To address this gap, we introduce RoboCerebra, a benchmark for evaluating high-level reasoning in long-horizon robotic manipulation. RoboCerebra includes: (1) a large-scale simulation dataset with extended task horizons and diverse subtask sequences in household environments; (2) a hierarchical framework combining a high-level VLM planner with a low-level vision-language-action (VLA) controller; and (3) an evaluation protocol targeting planning, reflection, and memory through structured System 1-System 2 interaction. The dataset is constructed via a top-down pipeline, where GPT generates task instructions and decomposes them into subtask sequences. Human operators execute the subtasks in simulation, yielding high-quality trajectories with dynamic object variations. Compared to prior benchmarks, RoboCerebra features significantly longer action sequences and denser annotations. We further benchmark state-of-the-art VLMs as System 2 modules and analyze their performance across key cognitive dimensions, advancing the development of more capable and generalizable robotic planners.