Active Test-time Vision-Language Navigation
作者: Heeju Ko, Sungjune Kim, Gyeongrok Oh, Jeongyoon Yoon, Honglak Lee, Sujin Jang, Seungryong Kim, Sangpil Kim
分类: cs.RO, cs.AI
发布日期: 2025-06-07
💡 一句话要点
提出ATENA,通过主动测试时学习解决视觉-语言导航中的泛化性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 主动学习 测试时学习 人机交互 熵优化
📋 核心要点
- 离线数据集训练的VLN策略在测试时面临泛化性挑战,智能体缺乏外部交互和反馈。
- ATENA通过主动测试时学习,利用情景反馈提高智能体在不确定导航结果中的置信度校准。
- 实验表明,ATENA在多个VLN基准测试中优于现有方法,有效克服了分布偏移问题。
📝 摘要(中文)
本文提出了一种名为ATENA(主动测试时导航代理)的测试时主动学习框架,旨在解决视觉-语言导航(VLN)策略在未知环境中性能下降的问题。ATENA通过情景反馈实现人机交互,提高不确定导航结果的置信度校准。该方法引入混合熵优化,结合动作分布和伪专家分布计算熵,从而控制预测置信度和动作偏好。此外,提出了一种自主动学习策略,使智能体能够根据置信预测评估导航结果,保持积极参与,实现充分理解和自适应决策。在REVERIE、R2R和R2R-CE等VLN基准测试中,ATENA成功克服了测试时的分布偏移,优于对比基线方法。
🔬 方法详解
问题定义:视觉-语言导航(VLN)任务旨在让智能体根据自然语言指令在真实或模拟环境中导航到目标位置。然而,在离线数据集上训练的VLN模型在部署到新的、未见过的环境中时,性能会显著下降,这是由于训练数据和测试数据之间存在分布差异。现有的熵最小化方法试图降低预测的不确定性,但容易累积误差,导致智能体对错误动作过于自信,缺乏充分的上下文理解。
核心思路:ATENA的核心思路是通过主动学习,在测试时引入人机交互,利用情景反馈来提高智能体的置信度校准。具体来说,ATENA学习在成功的导航情景中增加置信度,在失败的情景中降低置信度,从而使智能体能够更好地适应新的环境。此外,ATENA还引入了一种自主动学习策略,使智能体能够根据置信预测来评估导航结果,从而保持积极参与和自适应决策。
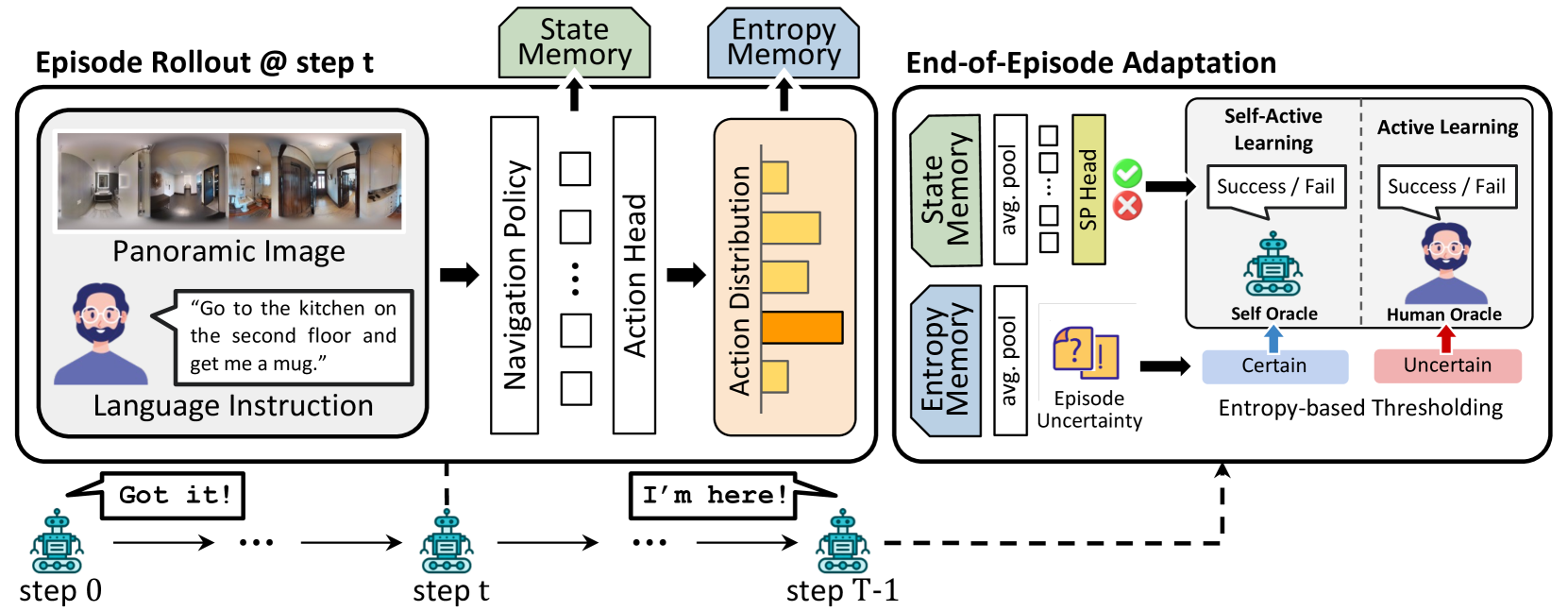
技术框架:ATENA的整体框架包含以下几个主要模块:1) 导航模块:负责根据当前的视觉输入和语言指令选择动作。2) 混合熵优化模块:计算动作分布和伪专家分布的混合熵,用于控制预测置信度和动作偏好。3) 自主动学习模块:根据置信预测评估导航结果,并利用反馈信号更新模型参数。4) 人机交互模块:在不确定性较高时,请求人工反馈,以提高置信度校准。整个流程是迭代进行的,智能体在每个迭代步骤中都会根据当前的状态选择动作,并根据反馈信号更新模型参数。
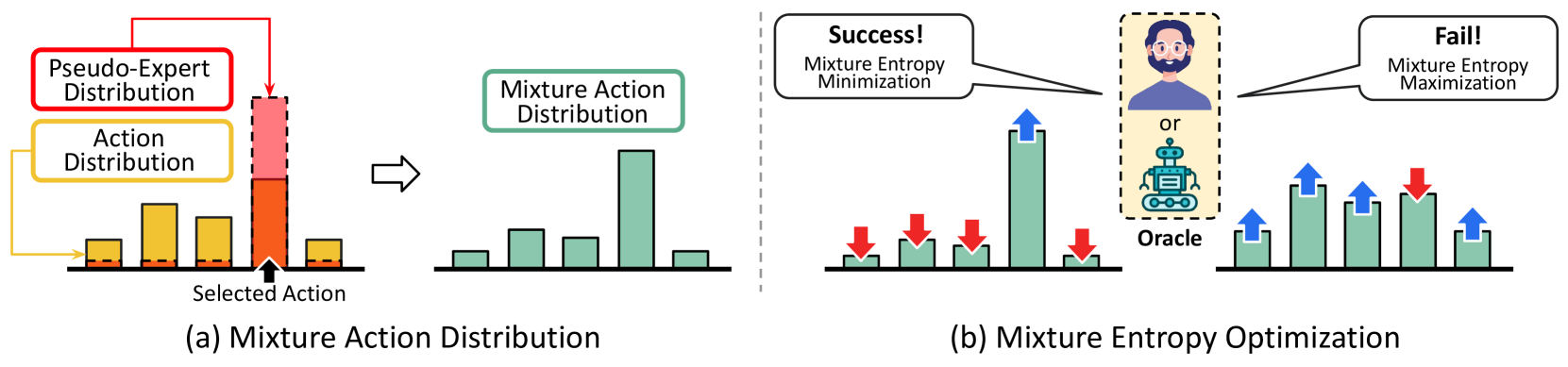
关键创新:ATENA的关键创新在于以下几个方面:1) 提出了一种测试时主动学习框架,通过人机交互来提高智能体的泛化能力。2) 引入了混合熵优化,结合动作分布和伪专家分布来控制预测置信度和动作偏好。3) 提出了一种自主动学习策略,使智能体能够根据置信预测来评估导航结果,从而保持积极参与和自适应决策。与现有方法相比,ATENA能够更好地利用测试时的信息,从而克服分布偏移问题。
关键设计:ATENA的关键设计包括:1) 混合熵的计算方式:混合熵是动作分布和伪专家分布的加权平均,权重参数需要根据实验结果进行调整。2) 自主动学习的阈值:智能体只有在置信度低于某个阈值时才会请求人工反馈,阈值的选择会影响学习效率和性能。3) 反馈信号的设计:反馈信号可以是二元的(成功或失败),也可以是更细粒度的,例如导航距离或角度误差。4) 模型更新策略:模型参数的更新可以采用在线学习或离线学习的方式,需要根据具体的应用场景进行选择。
🖼️ 关键图片

📊 实验亮点
在REVERIE、R2R和R2R-CE等VLN基准测试中,ATENA显著优于现有的基线方法。例如,在REVERIE数据集上,ATENA的成功率提高了5%以上。实验结果表明,ATENA能够有效地克服测试时的分布偏移,提高智能体的泛化能力。
🎯 应用场景
ATENA具有广泛的应用前景,例如在家庭服务机器人、自动驾驶汽车和虚拟现实导航等领域。它可以帮助机器人在未知环境中更好地理解人类指令,并安全有效地导航到目标位置。此外,ATENA还可以应用于其他需要主动学习和人机交互的任务,例如图像分类、目标检测和语音识别等。
📄 摘要(原文)
Vision-Language Navigation (VLN) policies trained on offline datasets often exhibit degraded task performance when deployed in unfamiliar navigation environments at test time, where agents are typically evaluated without access to external interaction or feedback. Entropy minimization has emerged as a practical solution for reducing prediction uncertainty at test time; however, it can suffer from accumulated errors, as agents may become overconfident in incorrect actions without sufficient contextual grounding. To tackle these challenges, we introduce ATENA (Active TEst-time Navigation Agent), a test-time active learning framework that enables a practical human-robot interaction via episodic feedback on uncertain navigation outcomes. In particular, ATENA learns to increase certainty in successful episodes and decrease it in failed ones, improving uncertainty calibration. Here, we propose mixture entropy optimization, where entropy is obtained from a combination of the action and pseudo-expert distributions-a hypothetical action distribution assuming the agent's selected action to be optimal-controlling both prediction confidence and action preference. In addition, we propose a self-active learning strategy that enables an agent to evaluate its navigation outcomes based on confident predictions. As a result, the agent stays actively engaged throughout all iterations, leading to well-grounded and adaptive decision-making. Extensive evaluations on challenging VLN benchmarks-REVERIE, R2R, and R2R-CE-demonstrate that ATENA successfully overcomes distributional shifts at test time, outperforming the compared baseline methods across various settings.