Disturbance-Aware Adaptive Compensation in Hybrid Force-Position Locomotion Policy for Legged Robots
作者: Yang Zhang, Buqing Nie, Zhanxiang Cao, Yangqing Fu, Yue Gao
分类: cs.RO
发布日期: 2025-05-31
备注: 8 pages, 12 figures
💡 一句话要点
提出混合力-位姿步态策略,增强腿式机器人抗扰动和负载适应性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿式机器人 强化学习 力位混合控制 扰动补偿 自适应控制
📋 核心要点
- 现有基于强化学习的腿式机器人运动策略在真实环境中难以适应负载变化和外部扰动,导致性能下降。
- 论文提出混合力-位姿步态策略,结合目标关节位置和前馈力矩,使机器人能快速响应扰动和负载变化。
- 提出的扰动感知自适应补偿基于扰动估计提供力矩补偿,增强了机器人对动态环境的适应性,并在实验中验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖的混合力-位姿步态策略(HFPLP)学习框架,旨在提高腿式机器人在不确定环境下的运动性能。该框架将目标关节位置和前馈力矩结合作为策略的动作空间,使机器人能够快速适应负载变化和外部扰动。此外,提出的扰动感知自适应补偿(DAAC)基于外部扰动估计,在力矩空间中提供补偿动作,从而增强机器人对动态环境变化的适应性。通过仿真和真实环境部署验证,结果表明该方法在负载能力和抗扰动方面优于现有方法。
🔬 方法详解
问题定义:现有基于强化学习的腿式机器人运动策略在真实环境中面临诸多挑战,尤其是在存在负载变化和外部扰动时,机器人的运动性能会显著下降。传统的基于位置控制的策略难以快速有效地应对这些扰动,需要更鲁棒的控制方法。
核心思路:论文的核心思路是将目标关节位置和前馈力矩结合起来作为强化学习策略的动作空间。通过直接控制关节力矩,机器人可以更快地响应外部扰动和负载变化,从而提高其在复杂环境中的适应性。此外,引入扰动感知自适应补偿机制,进一步增强了机器人对动态环境的鲁棒性。
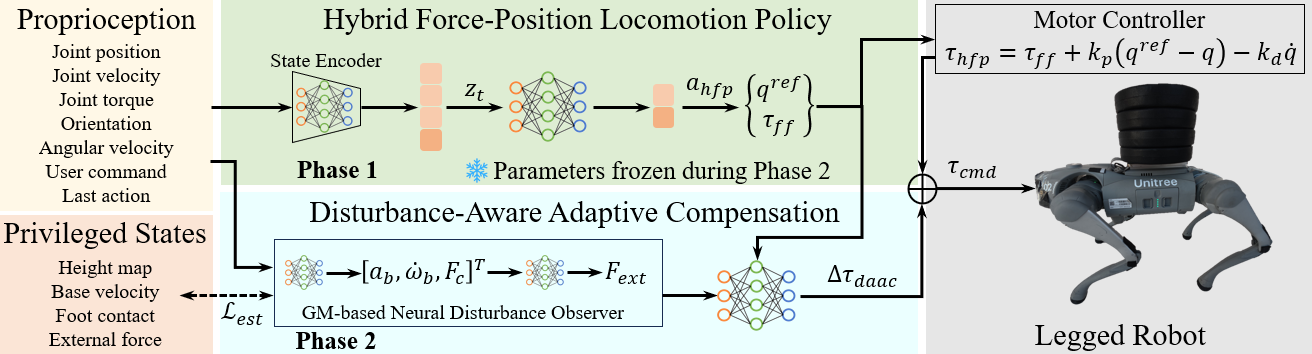
技术框架:该方法包含两个主要组成部分:混合力-位姿步态策略(HFPLP)和扰动感知自适应补偿(DAAC)。HFPLP通过强化学习训练得到,其动作空间包含目标关节位置和前馈力矩。DAAC模块则负责估计外部扰动,并基于此生成补偿力矩,与HFPLP的输出力矩叠加,共同作用于机器人。整体流程是:首先,HFPLP根据当前状态输出目标关节位置和前馈力矩;然后,DAAC模块估计外部扰动并生成补偿力矩;最后,将前馈力矩和补偿力矩叠加,驱动机器人运动。
关键创新:该方法最重要的创新点在于混合力-位姿的动作空间设计以及扰动感知自适应补偿机制。传统的强化学习方法通常只控制关节位置,而该方法同时控制关节位置和力矩,使得机器人能够更直接地响应外部扰动。DAAC模块通过估计外部扰动并进行补偿,进一步提高了机器人的鲁棒性。与现有方法相比,该方法能够更好地适应负载变化和外部扰动,从而提高机器人在复杂环境中的运动性能。
关键设计:DAAC模块的关键在于扰动估计方法和补偿力矩的生成策略。扰动估计可能采用卡尔曼滤波或其他状态估计方法,基于机器人的状态和控制输入来估计外部扰动。补偿力矩的生成策略则需要根据扰动估计结果,设计合适的控制律,例如PID控制或更复杂的自适应控制方法。具体的损失函数和网络结构未知,需要参考论文细节。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的方法在负载能力和抗扰动方面优于现有方法。具体性能数据未知,但摘要中明确指出该方法在仿真和真实环境部署中均表现出优越性,证明了其在实际应用中的潜力。与传统方法相比,该方法能够更好地适应负载变化和外部扰动,从而提高机器人在复杂环境中的运动性能。
🎯 应用场景
该研究成果可广泛应用于物流、救援、巡检等领域。腿式机器人能够在复杂地形和拥挤环境中灵活移动,适应负载变化和外部干扰。通过该技术,可以提升机器人在实际应用中的可靠性和效率,例如在灾难现场进行物资运输,或在仓库中进行货物搬运。
📄 摘要(原文)
Reinforcement Learning (RL)-based methods have significantly improved the locomotion performance of legged robots. However, these motion policies face significant challenges when deployed in the real world. Robots operating in uncertain environments struggle to adapt to payload variations and external disturbances, resulting in severe degradation of motion performance. In this work, we propose a novel Hybrid Force-Position Locomotion Policy (HFPLP) learning framework, where the action space of the policy is defined as a combination of target joint positions and feedforward torques, enabling the robot to rapidly respond to payload variations and external disturbances. In addition, the proposed Disturbance-Aware Adaptive Compensation (DAAC) provides compensation actions in the torque space based on external disturbance estimation, enhancing the robot's adaptability to dynamic environmental changes. We validate our approach in both simulation and real-world deployment, demonstrating that it outperforms existing methods in carrying payloads and resisting disturbances.