Navigation of a Three-Link Microswimmer via Deep Reinforcement Learning
作者: Yuyang Lai, Sina Heydari, On Shun Pak, Yi Man
分类: cs.RO, physics.flu-dyn
发布日期: 2025-05-30
💡 一句话要点
提出基于深度强化学习的三连杆微型游泳器导航方法,实现复杂环境下的自主运动。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 微型游泳器 导航 运动控制 低雷诺数
📋 核心要点
- 微型机器人在复杂生物环境中进行运动规划和轨迹设计面临巨大挑战,现有方法难以实现适应性运动。
- 利用强化学习,设计速度优先和能量感知两种策略,为三连杆游泳器模型开发运动模式,实现目标导航。
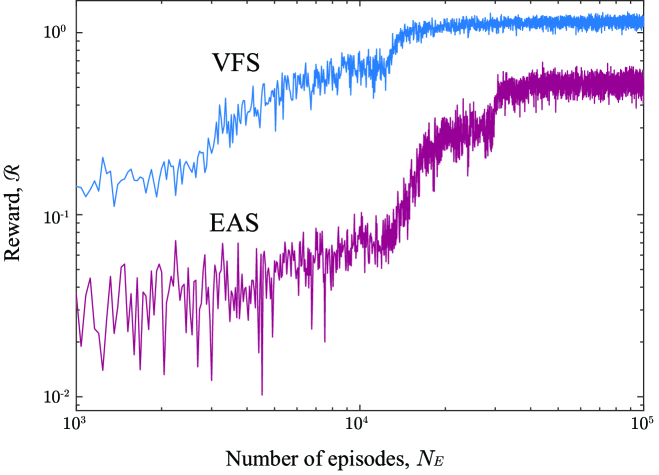
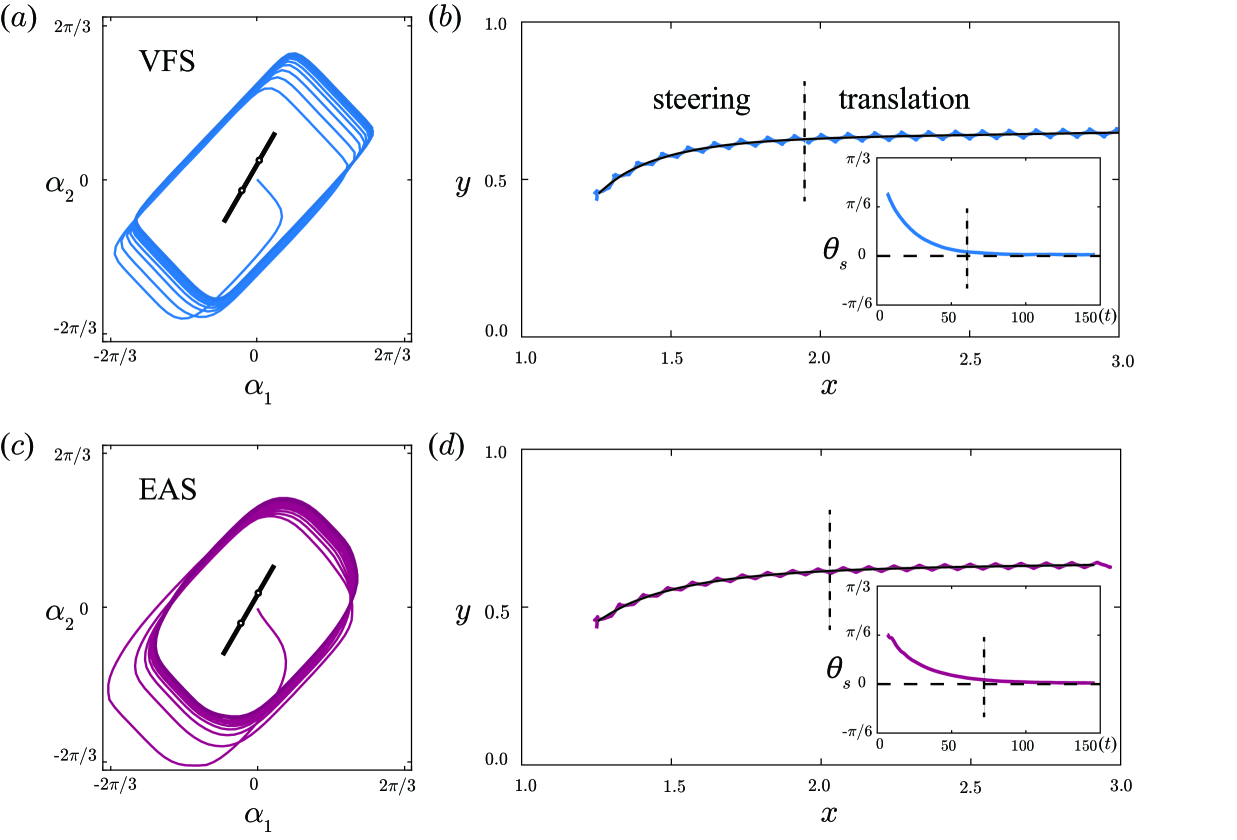
- 实验表明,不同奖励函数影响运动模式,RL游泳器能适应不同导航任务,如跟踪复杂轨迹和追逐移动目标。
📝 摘要(中文)
本文探索了利用强化学习(RL)为低雷诺数下的三连杆游泳器模型开发运动模式,以实现目标导航。具体而言,设计了两种基于RL的策略:一种侧重于最大化速度(速度优先策略),另一种则平衡速度与能量消耗(能量感知策略)。结果表明,不同奖励函数的使用如何影响通过RL开发的运动模式,并将其与传统优化方法获得的结果进行比较。此外,展示了基于RL的游泳器在执行不同导航任务中调整其运动模式的能力,包括跟踪复杂轨迹和追逐移动目标。总而言之,这项工作突出了强化学习作为一种通用工具的潜力,可用于设计高效且自适应的微型游泳器,使其能够在复杂环境中执行复杂的机动。
🔬 方法详解
问题定义:论文旨在解决微型机器人在低雷诺数环境下,如何有效地进行目标导航的问题。现有方法,如传统优化方法,在复杂环境中难以实现高效且自适应的运动模式,尤其是在能量消耗方面可能存在不足。
核心思路:论文的核心思路是利用强化学习(RL)来训练微型游泳器的运动模式。通过设计合适的奖励函数,引导RL智能体学习到能够最大化速度或平衡速度与能量消耗的运动策略,从而实现高效的目标导航。
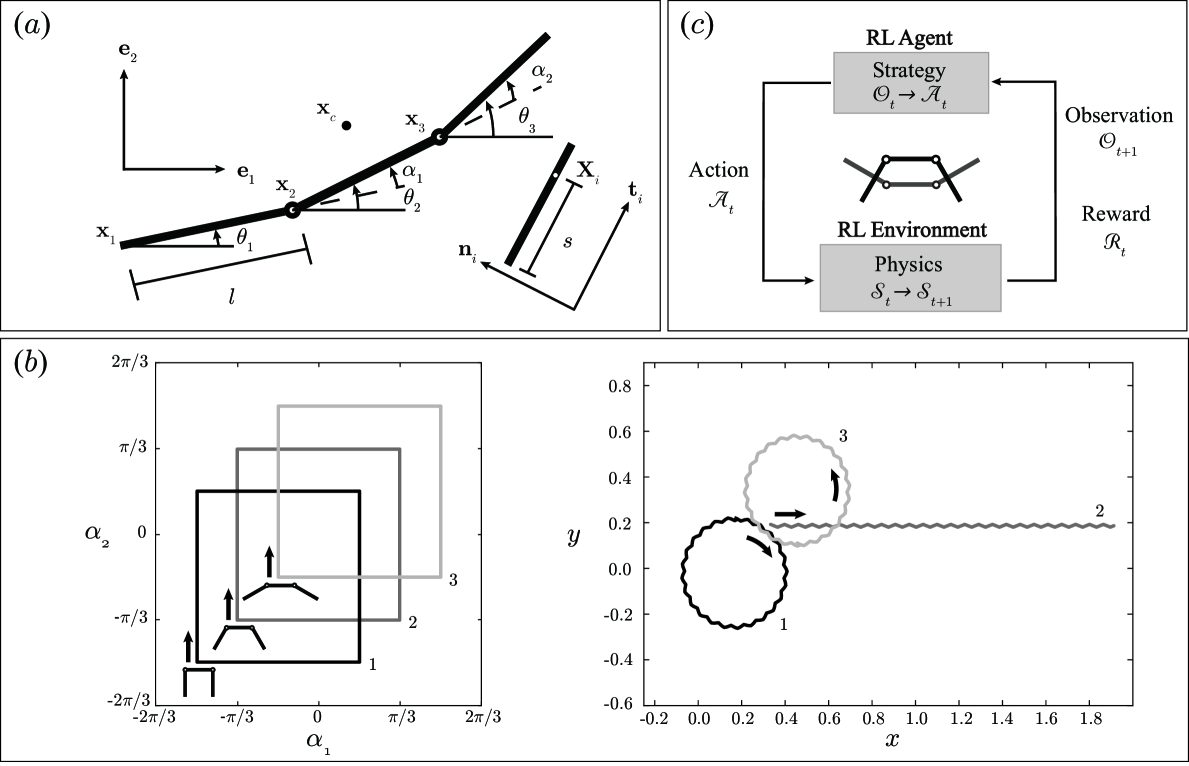
技术框架:整体框架包括以下几个主要模块:1) 三连杆游泳器模型构建;2) 强化学习环境搭建,包括状态空间、动作空间和奖励函数的设计;3) RL智能体训练,使用深度神经网络作为策略网络;4) 导航任务测试,包括轨迹跟踪和目标追逐。
关键创新:最重要的技术创新点在于将强化学习应用于微型游泳器的运动控制,使其能够自主学习适应复杂环境的运动模式。与传统优化方法相比,RL方法具有更强的适应性和泛化能力,能够处理更复杂的导航任务。
关键设计:论文设计了两种不同的奖励函数:速度优先策略(Velocity-Focused Strategy)和能量感知策略(Energy-Aware Strategy)。速度优先策略旨在最大化游泳器的前进速度,而能量感知策略则在最大化速度的同时,考虑能量消耗,以实现更节能的运动。具体参数设置和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过强化学习训练的微型游泳器能够有效地执行各种导航任务,包括跟踪复杂轨迹和追逐移动目标。与传统优化方法相比,RL方法能够学习到更高效且自适应的运动模式。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于生物医学工程领域,例如在微创手术中,利用微型机器人进行药物递送或靶向治疗。此外,还可应用于环境监测领域,例如在复杂水域中进行污染物检测。未来,该技术有望推动微型机器人在更多领域的应用,例如精密制造和微型器件组装。
📄 摘要(原文)
Motile microorganisms develop effective swimming gaits to adapt to complex biological environments. Translating this adaptability to smart microrobots presents significant challenges in motion planning and stroke design. In this work, we explore the use of reinforcement learning (RL) to develop stroke patterns for targeted navigation in a three-link swimmer model at low Reynolds numbers. Specifically, we design two RL-based strategies: one focusing on maximizing velocity (Velocity-Focused Strategy) and another balancing velocity with energy consumption (Energy-Aware Strategy). Our results demonstrate how the use of different reward functions influences the resulting stroke patterns developed via RL, which are compared with those obtained from traditional optimization methods. Furthermore, we showcase the capability of the RL-powered swimmer in adapting its stroke patterns in performing different navigation tasks, including tracing complex trajectories and pursuing moving targets. Taken together, this work highlights the potential of reinforcement learning as a versatile tool for designing efficient and adaptive microswimmers capable of sophisticated maneuvers in complex environments.