Robot-R1: Reinforcement Learning for Enhanced Embodied Reasoning in Robotics
作者: Dongyoung Kim, Sumin Park, Huiwon Jang, Jinwoo Shin, Jaehyung Kim, Younggyo Seo
分类: cs.RO, cs.AI
发布日期: 2025-05-29 (更新: 2026-01-16)
备注: NeurIPS 2025
💡 一句话要点
Robot-R1:强化学习驱动的机器人具身推理增强框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人控制 具身推理 强化学习 视觉-语言模型 关键点预测
📋 核心要点
- 现有基于监督学习的机器人控制方法依赖启发式数据集,缺乏对机器人控制的直接优化,导致泛化性差。
- Robot-R1利用强化学习,通过奖励更准确的关键点预测,来增强机器人具身推理能力,提升控制性能。
- 实验表明,Robot-R1在具身推理任务上超越了监督学习方法,甚至在特定任务上优于GPT-4o。
📝 摘要(中文)
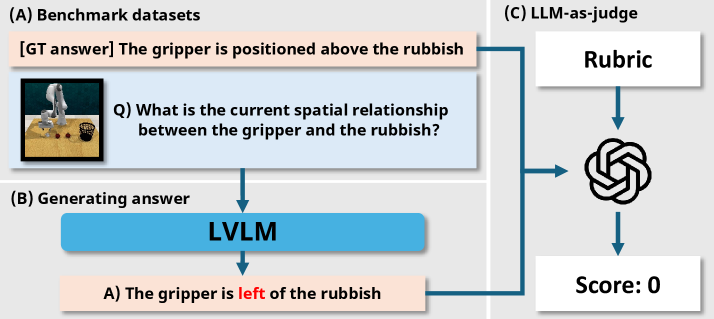
大型视觉-语言模型(LVLMs)通过结合具身推理与机器人控制,在机器人技术领域展现出巨大潜力。一种常见方法是使用监督式微调(SFT)在与机器人控制相关的具身推理任务上进行训练。然而,SFT数据集通常是启发式构建的,并未明确针对改进机器人控制进行优化。此外,SFT常常导致灾难性遗忘和泛化性能下降等问题。为了解决这些限制,我们引入了Robot-R1,这是一个利用强化学习来增强机器人控制的具身推理的新框架。Robot-R1学习预测完成任务所需的下一个关键点状态,并以当前场景图像和来自专家演示的环境元数据为条件。受DeepSeek-R1学习方法的启发,Robot-R1采样基于推理的响应,并强化那些能够实现更准确预测的响应。为了严格评估Robot-R1,我们还引入了一个新的基准,该基准需要多样化的具身推理能力来完成任务。实验表明,使用Robot-R1训练的模型在具身推理任务上优于SFT方法。尽管只有70亿参数,Robot-R1甚至在与低级动作控制相关的推理任务(如空间和运动推理)上超越了GPT-4o。
🔬 方法详解
问题定义:现有方法主要依赖于监督式微调(SFT),使用启发式构建的数据集训练大型视觉-语言模型(LVLMs)进行机器人控制。这种方法的痛点在于数据集并非专门为优化机器人控制而设计,导致模型在实际应用中泛化能力不足,容易出现灾难性遗忘等问题。因此,需要一种更有效的方法来提升机器人的具身推理能力,从而更好地完成控制任务。
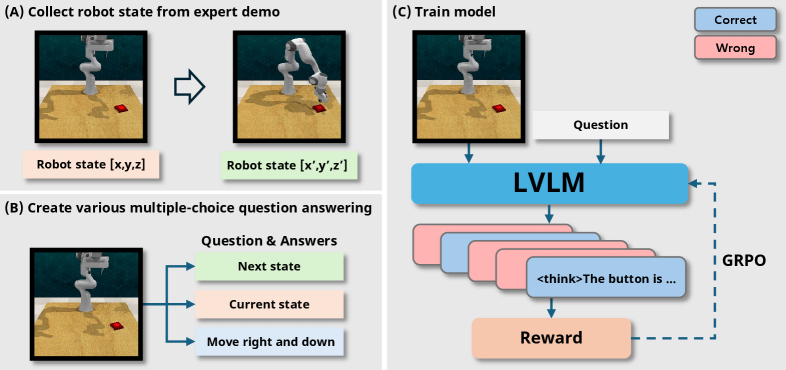
核心思路:Robot-R1的核心思路是利用强化学习来直接优化机器人的具身推理能力。通过奖励那些能够更准确预测下一步关键点状态的推理过程,模型可以学习到更有效的控制策略。这种方法避免了对启发式数据集的依赖,而是通过与环境的交互来学习,从而提高模型的泛化能力和鲁棒性。
技术框架:Robot-R1的整体框架包括以下几个主要模块:1) 视觉输入模块,用于处理当前场景的图像信息;2) 环境元数据模块,用于提供来自专家演示的环境信息;3) 推理模块,基于视觉输入和环境元数据预测下一步的关键点状态;4) 强化学习模块,根据预测的准确性给予奖励,并更新推理模块的参数。整个流程是循环迭代的,模型不断与环境交互,并通过强化学习来优化推理能力。
关键创新:Robot-R1最重要的技术创新点在于将强化学习引入到机器人具身推理的训练过程中。与传统的监督学习方法不同,Robot-R1通过奖励机制来引导模型学习更有效的控制策略,从而避免了对启发式数据集的依赖。此外,Robot-R1还借鉴了DeepSeek-R1的学习方法,通过采样推理过程并强化那些能够实现更准确预测的过程,进一步提升了模型的性能。
关键设计:Robot-R1的关键设计包括:1) 关键点状态的定义,需要根据具体的任务进行设计,以确保能够准确描述机器人的状态;2) 奖励函数的设计,需要能够准确反映预测的准确性,并引导模型学习更有效的控制策略;3) 强化学习算法的选择,需要根据具体的任务和环境进行选择,以确保能够有效地训练模型。论文中模型参数量为7B。
🖼️ 关键图片

📊 实验亮点
Robot-R1在具身推理任务上显著优于传统的监督学习方法。实验结果表明,Robot-R1不仅超越了SFT方法,甚至在与低级动作控制相关的推理任务(如空间和运动推理)上超越了GPT-4o,尽管其参数量仅为70亿。这表明Robot-R1在提升机器人具身推理能力方面具有显著优势。
🎯 应用场景
Robot-R1具有广泛的应用前景,可应用于各种需要复杂具身推理的机器人控制任务,例如家庭服务机器人、工业自动化机器人、医疗辅助机器人等。通过提升机器人的推理能力和控制精度,Robot-R1可以帮助机器人更好地理解环境、执行任务,并与人类进行更自然的交互,从而提高生产效率和服务质量。
📄 摘要(原文)
Large Vision-Language Models (LVLMs) have recently shown great promise in advancing robotics by combining embodied reasoning with robot control. A common approach involves training on embodied reasoning tasks related to robot control using Supervised Fine-Tuning (SFT). However, SFT datasets are often heuristically constructed and not explicitly optimized for improving robot control. Furthermore, SFT often leads to issues such as catastrophic forgetting and reduced generalization performance. To address these limitations, we introduce Robot-R1, a novel framework that leverages reinforcement learning to enhance embodied reasoning specifically for robot control. Robot-R1 learns to predict the next keypoint state required for task completion, conditioned on the current scene image and environment metadata derived from expert demonstrations. Inspired by the DeepSeek-R1 learning approach, Robot-R1 samples reasoning-based responses and reinforces those that lead to more accurate predictions. To rigorously evaluate Robot-R1, we also introduce a new benchmark that demands the diverse embodied reasoning capabilities for the task. Our experiments show that models trained with Robot-R1 outperform SFT methods on embodied reasoning tasks. Despite having only 7B parameters, Robot-R1 even surpasses GPT-4o on reasoning tasks related to low-level action control, such as spatial and movement reasoning.