Mobi-$π$: Mobilizing Your Robot Learning Policy
作者: Jingyun Yang, Isabella Huang, Brandon Vu, Max Bajracharya, Rika Antonova, Jeannette Bohg
分类: cs.RO, cs.CV, cs.LG
发布日期: 2025-05-29 (更新: 2025-09-26)
备注: CoRL 2025. Project website: https://mobipi.github.io/
💡 一句话要点
Mobi-$π$: 提出一种策略迁移方法,实现移动机器人操作策略在不同环境下的泛化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 移动机器人 策略迁移 视觉运动策略 3D高斯溅射 机器人操控
📋 核心要点
- 现有视觉运动策略在移动机器人上的泛化性差,尤其是在机器人基座位置变化时,限制了其应用。
- 论文提出策略迁移方法,通过优化机器人基座姿态,使其与策略训练时的分布对齐,从而实现策略在新环境中的应用。
- 实验结果表明,该方法在模拟和真实环境中均优于基线方法,验证了其在策略迁移方面的有效性。
📝 摘要(中文)
已学习的视觉运动策略能够执行日益复杂的操控任务。然而,这些策略大多在有限的机器人位置和相机视角下收集的数据上进行训练,导致对新机器人位置的泛化能力较差,限制了这些策略在移动平台上的应用,尤其是在执行诸如按按钮或拧水龙头等精确任务时。本文提出了策略迁移问题:在新环境中找到一个移动机器人基座姿态,使其相对于在有限相机视角下训练的操控策略而言,处于分布内。与重新训练策略本身以使其对未见过的机器人基座姿态初始化更具鲁棒性相比,策略迁移将导航与操控分离,因此不需要额外的演示。重要的是,这种问题定义补充了现有为提高操控策略对新视点的鲁棒性的工作,并与之兼容。我们提出了一种新的策略迁移方法,通过优化机器人基座姿态以与学习策略的分布内基座姿态对齐,从而桥接导航和操控。我们的方法利用3D高斯溅射进行新视角合成,使用评分函数评估姿态适用性,并使用基于采样的优化来识别最佳机器人姿态。为了更深入地理解策略迁移,我们还引入了Mobi-$π$框架,其中包括:(1)量化迁移给定策略难度的指标,(2)一套基于RoboCasa的模拟移动操控任务,用于评估策略迁移,以及(3)用于分析的可视化工具。在我们开发的模拟任务套件和现实世界中,我们都表明我们的方法优于基线,证明了其策略迁移的有效性。
🔬 方法详解
问题定义:现有学习的视觉运动策略在固定机器人位置和相机视角下训练,当移动机器人基座位置发生变化时,策略的性能会显著下降。现有方法通常需要重新训练策略以适应新的环境,这需要大量的额外数据和计算资源。因此,如何使已学习的策略能够泛化到新的机器人基座位置,是一个重要的挑战。
核心思路:论文的核心思路是将导航和操控解耦,通过优化移动机器人的基座姿态,使其在新环境中能够获得与训练环境中相似的视角和位置关系,从而使已学习的策略能够直接应用。这种方法避免了重新训练策略的需要,降低了数据和计算成本。
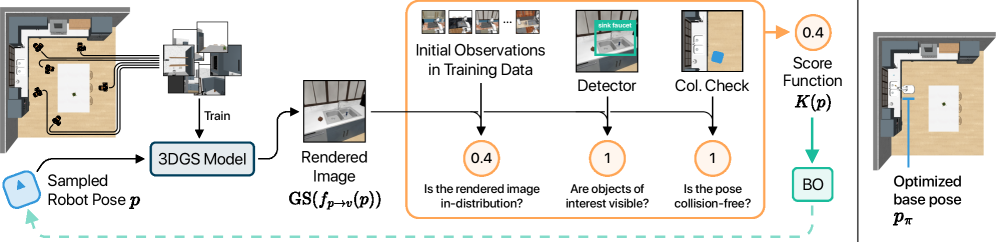
技术框架:该方法主要包含以下几个模块:1) 3D高斯溅射(3D Gaussian Splatting):用于在新视角下合成图像,模拟不同机器人基座姿态下的视觉输入。2) 评分函数:用于评估不同机器人基座姿态的适用性,即评估该姿态是否与训练数据分布相似。3) 基于采样的优化:用于搜索最佳的机器人基座姿态,使得评分函数的值最大化。整体流程是,首先使用3D高斯溅射生成不同姿态下的图像,然后使用评分函数对这些姿态进行评估,最后使用基于采样的优化算法找到最佳姿态。
关键创新:该方法的核心创新在于将策略迁移问题转化为一个优化问题,通过优化机器人基座姿态来实现策略的泛化。与传统的重新训练策略的方法相比,该方法不需要额外的训练数据,并且能够更好地利用已学习的策略知识。此外,使用3D高斯溅射进行新视角合成,能够有效地模拟不同姿态下的视觉输入,提高了姿态评估的准确性。
关键设计:评分函数的设计是关键。论文中评分函数的设计考虑了多种因素,例如图像的相似性、目标物体的可见性等。具体来说,评分函数可以基于预训练的视觉特征提取器,计算新视角图像与训练图像之间的特征相似度。此外,还可以加入目标物体的可见性约束,确保机器人能够清晰地看到目标物体。基于采样的优化算法可以选择多种方法,例如随机采样、遗传算法等。论文中具体使用的优化算法未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在模拟和真实环境中均优于基线方法。在模拟环境中,该方法在多个移动操控任务上取得了显著的性能提升。在真实环境中,该方法也能够成功地将策略迁移到新的机器人基座位置,并完成相应的操控任务。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于各种移动机器人操控任务,例如家庭服务机器人、工业机器人等。通过策略迁移,可以使机器人在新的环境中快速适应,执行诸如物品抓取、按钮按下、旋钮转动等任务。该方法能够降低机器人部署的成本,提高机器人的智能化水平,具有重要的实际应用价值。
📄 摘要(原文)
Learned visuomotor policies are capable of performing increasingly complex manipulation tasks. However, most of these policies are trained on data collected from limited robot positions and camera viewpoints. This leads to poor generalization to novel robot positions, which limits the use of these policies on mobile platforms, especially for precise tasks like pressing buttons or turning faucets. In this work, we formulate the policy mobilization problem: find a mobile robot base pose in a novel environment that is in distribution with respect to a manipulation policy trained on a limited set of camera viewpoints. Compared to retraining the policy itself to be more robust to unseen robot base pose initializations, policy mobilization decouples navigation from manipulation and thus does not require additional demonstrations. Crucially, this problem formulation complements existing efforts to improve manipulation policy robustness to novel viewpoints and remains compatible with them. We propose a novel approach for policy mobilization that bridges navigation and manipulation by optimizing the robot's base pose to align with an in-distribution base pose for a learned policy. Our approach utilizes 3D Gaussian Splatting for novel view synthesis, a score function to evaluate pose suitability, and sampling-based optimization to identify optimal robot poses. To understand policy mobilization in more depth, we also introduce the Mobi-$π$ framework, which includes: (1) metrics that quantify the difficulty of mobilizing a given policy, (2) a suite of simulated mobile manipulation tasks based on RoboCasa to evaluate policy mobilization, and (3) visualization tools for analysis. In both our developed simulation task suite and the real world, we show that our approach outperforms baselines, demonstrating its effectiveness for policy mobilization.