SCIZOR: A Self-Supervised Approach to Data Curation for Large-Scale Imitation Learning
作者: Yu Zhang, Yuqi Xie, Huihan Liu, Rutav Shah, Michael Wan, Linxi Fan, Yuke Zhu
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-28 (更新: 2025-09-09)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SCIZOR:一种自监督数据清洗方法,用于提升大规模模仿学习性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 自监督学习 数据清洗 机器人操作 数据质量
📋 核心要点
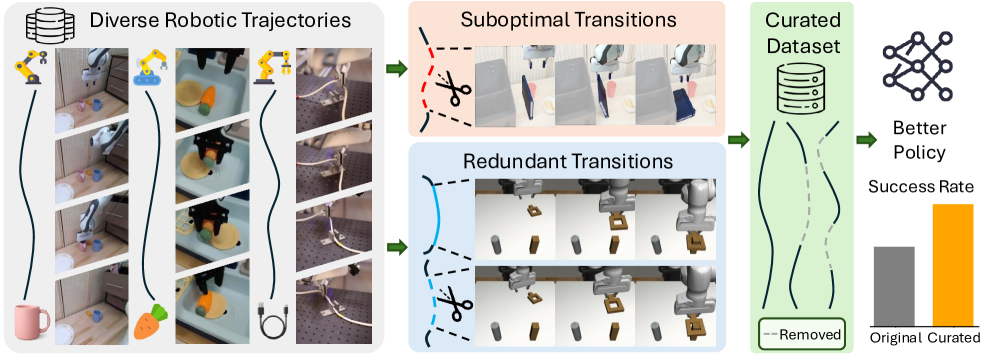
- 大规模模仿学习数据集质量差异大,直接影响策略学习效果,需要自动数据清洗。
- SCIZOR通过自监督学习识别并过滤次优和冗余的状态-动作对,提升数据质量。
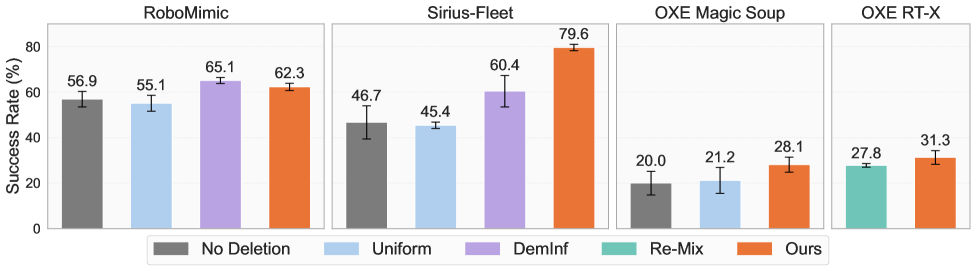
- 实验证明,SCIZOR能显著提高模仿学习策略性能,平均提升15.4%,且所需数据更少。
📝 摘要(中文)
模仿学习通过从人类演示中学习各种行为来提升机器人能力。然而,用于策略训练的大规模数据集通常质量参差不齐,这会负面影响性能。因此,自动清洗数据集,通过过滤低质量样本来提高质量至关重要。现有的机器人清洗方法依赖于昂贵的人工标注,并且以粗粒度(如数据集或轨迹级别)执行清洗,未能考虑单个状态-动作对的质量。为了解决这个问题,我们提出了SCIZOR,一个自监督数据清洗框架,它过滤掉低质量的状态-动作对,以提高模仿学习策略的性能。SCIZOR针对两种互补的低质量数据来源:次优数据(通过不良动作阻碍学习)和冗余数据(通过重复模式稀释训练)。SCIZOR利用自监督任务进度预测器来处理次优数据,移除缺乏任务进度的样本;并使用在联合状态-动作表示上运行的去重模块来处理具有冗余模式的样本。实验表明,SCIZOR使模仿学习策略能够以更少的数据实现更高的性能,在多个基准测试中平均提高了15.4%。
🔬 方法详解
问题定义:大规模模仿学习数据集通常包含大量低质量数据,包括次优动作和冗余状态-动作对。这些低质量数据会阻碍策略学习,降低最终性能。现有的数据清洗方法要么依赖昂贵的人工标注,要么只能在数据集或轨迹级别进行粗粒度清洗,无法有效识别和过滤单个状态-动作对中的噪声。
核心思路:SCIZOR的核心思路是利用自监督学习来识别和过滤低质量的状态-动作对。它将数据质量问题分解为两个方面:次优性和冗余性。通过设计相应的自监督任务,SCIZOR能够自动评估每个状态-动作对的质量,并将其用于数据清洗,从而提高模仿学习的性能。这种方法避免了人工标注的成本,并且能够以更细粒度的方式进行数据清洗。
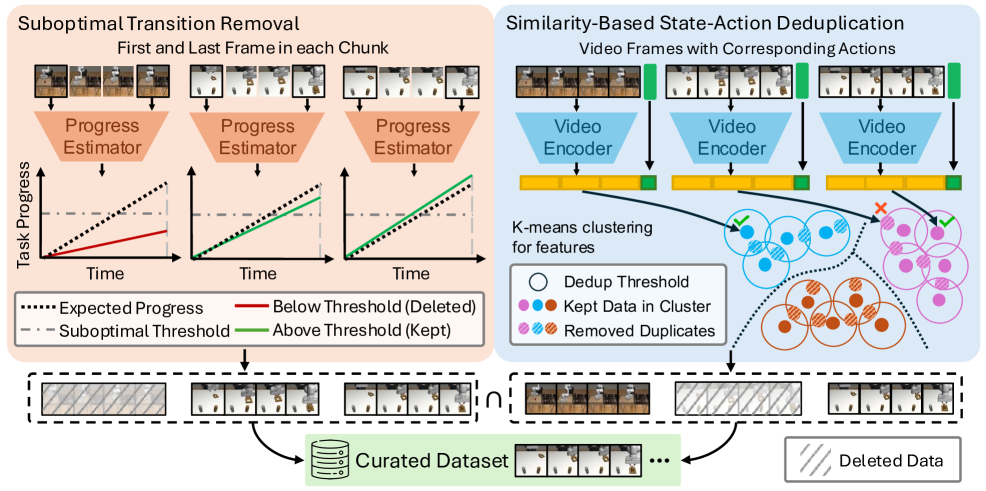
技术框架:SCIZOR包含两个主要模块:次优数据过滤模块和冗余数据过滤模块。次优数据过滤模块使用一个自监督任务进度预测器,该预测器学习预测给定状态-动作对后任务的进展程度。如果预测的进展程度低于阈值,则该状态-动作对被认为是次优的,并被过滤掉。冗余数据过滤模块使用一个去重模块,该模块计算状态-动作对的嵌入表示,并使用余弦相似度来检测重复的模式。如果两个状态-动作对的相似度高于阈值,则其中一个被认为是冗余的,并被过滤掉。这两个模块可以独立使用,也可以组合使用。
关键创新:SCIZOR的关键创新在于其自监督的数据清洗方法,该方法能够自动识别和过滤低质量的状态-动作对,而无需人工标注。它将数据质量问题分解为次优性和冗余性两个方面,并设计了相应的自监督任务来解决这两个问题。此外,SCIZOR能够在状态-动作对级别进行细粒度的数据清洗,这比现有的数据集或轨迹级别的清洗方法更加有效。
关键设计:任务进度预测器使用Transformer网络结构,输入为状态-动作对,输出为任务进展的预测值。损失函数采用均方误差损失。去重模块使用预训练的视觉编码器提取状态的特征,并与动作进行拼接,然后使用MLP网络进行嵌入。相似度阈值和任务进展阈值通过验证集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SCIZOR在多个机器人操作基准测试中显著提高了模仿学习策略的性能。例如,在部分任务上,使用SCIZOR清洗后的数据训练的策略比使用原始数据训练的策略性能提高了15.4%。此外,SCIZOR还能够减少训练所需的数据量,从而加快训练速度。
🎯 应用场景
SCIZOR可应用于各种模仿学习任务,尤其是在数据质量参差不齐的大规模数据集上。例如,它可以用于机器人操作、自动驾驶、游戏AI等领域,提高策略学习的效率和性能。通过自动清洗数据,SCIZOR可以降低对高质量人工演示数据的需求,从而降低模仿学习的成本。
📄 摘要(原文)
Imitation learning advances robot capabilities by enabling the acquisition of diverse behaviors from human demonstrations. However, large-scale datasets used for policy training often introduce substantial variability in quality, which can negatively impact performance. As a result, automatically curating datasets by filtering low-quality samples to improve quality becomes essential. Existing robotic curation approaches rely on costly manual annotations and perform curation at a coarse granularity, such as the dataset or trajectory level, failing to account for the quality of individual state-action pairs. To address this, we introduce SCIZOR, a self-supervised data curation framework that filters out low-quality state-action pairs to improve the performance of imitation learning policies. SCIZOR targets two complementary sources of low-quality data: suboptimal data, which hinders learning with undesirable actions, and redundant data, which dilutes training with repetitive patterns. SCIZOR leverages a self-supervised task progress predictor for suboptimal data to remove samples lacking task progression, and a deduplication module operating on joint state-action representation for samples with redundant patterns. Empirically, we show that SCIZOR enables imitation learning policies to achieve higher performance with less data, yielding an average improvement of 15.4% across multiple benchmarks. More information is available at: https://ut-austin-rpl.github.io/SCIZOR/