ReinFlow: Fine-tuning Flow Matching Policy with Online Reinforcement Learning
作者: Tonghe Zhang, Chao Yu, Sichang Su, Yu Wang
分类: cs.RO, cs.LG
发布日期: 2025-05-28 (更新: 2026-01-08)
备注: 38 pages
期刊: Published in The Thirty-Ninth Annual Conference on Neural Information Processing Systems, 2025
💡 一句话要点
ReinFlow:在线强化学习微调Flow Matching策略,提升连续机器人控制性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: Flow Matching 强化学习 机器人控制 在线学习 连续控制
📋 核心要点
- 现有Flow Matching策略在机器人控制中缺乏有效的在线微调方法,难以适应复杂环境和任务。
- ReinFlow通过注入可学习噪声,将Flow策略转化为马尔可夫过程,实现基于似然的强化学习微调。
- 实验表明,ReinFlow能显著提升Rectified Flow和Shortcut Model在运动和操作任务中的性能,并节省计算资源。
📝 摘要(中文)
本文提出ReinFlow,一个简单而有效的在线强化学习框架,用于微调连续机器人控制中的Flow Matching策略。ReinFlow源于严格的强化学习理论,通过向Flow策略的确定性路径注入可学习噪声,将Flow转化为离散时间马尔可夫过程,从而实现精确且直接的似然计算。这种转换有助于探索并确保训练稳定性,使ReinFlow能够微调各种Flow模型变体,包括Rectified Flow和Shortcut Models,尤其是在极少甚至一步去噪的情况下。在具有代表性的运动和操作任务中,包括具有视觉输入和稀疏奖励的长期规划,对ReinFlow进行了基准测试。在具有挑战性的腿部运动任务中,Rectified Flow策略的episode奖励在微调后平均净增长135.36%,与最先进的扩散强化学习微调方法DPPO相比,节省了去噪步骤和82.63%的运行时间。在状态和视觉操作任务中,Shortcut Model策略在使用ReinFlow进行微调后,在四步甚至一步去噪的情况下,成功率平均净增长40.34%,其性能与微调后的DDIM策略相当,同时平均节省了23.20%的计算时间。
🔬 方法详解
问题定义:论文旨在解决连续机器人控制中,Flow Matching策略难以通过在线强化学习进行有效微调的问题。现有的Flow Matching方法通常是离线训练的,难以适应动态变化的环境和任务需求。此外,直接将Flow Matching策略应用于强化学习,会面临探索不足和训练不稳定的问题。
核心思路:ReinFlow的核心思路是将确定性的Flow Matching策略转化为随机策略,从而允许强化学习算法进行有效的探索。具体来说,通过在Flow策略的确定性路径中注入可学习的噪声,将Flow转化为离散时间马尔可夫过程。这种转换使得可以精确计算似然,从而可以使用基于似然的强化学习算法进行微调。
技术框架:ReinFlow的整体框架包括以下几个主要模块:1) Flow Matching策略:使用预训练的Flow Matching模型,例如Rectified Flow或Shortcut Model,作为初始策略。2) 噪声注入模块:向Flow策略的确定性路径注入可学习的噪声,将Flow转化为离散时间马尔可夫过程。3) 强化学习算法:使用基于似然的强化学习算法,例如REINFORCE或Actor-Critic方法,对Flow策略进行微调。4) 奖励函数:根据具体的机器人控制任务设计奖励函数,用于指导强化学习过程。
关键创新:ReinFlow的关键创新在于将Flow Matching策略与在线强化学习相结合,并提出了一种有效的噪声注入方法,将确定性的Flow转化为随机策略。这种方法使得可以使用基于似然的强化学习算法对Flow策略进行微调,从而提高了Flow策略在复杂环境和任务中的适应性。与现有方法相比,ReinFlow不需要复杂的采样过程,可以直接计算似然,从而提高了训练效率和稳定性。
关键设计:ReinFlow的关键设计包括:1) 噪声注入策略:可以使用不同的噪声分布,例如高斯分布或均匀分布,并使用神经网络学习噪声的参数。2) 强化学习算法:可以使用不同的基于似然的强化学习算法,例如REINFORCE或Actor-Critic方法,并根据具体的任务需求进行调整。3) 奖励函数:奖励函数的设计至关重要,需要根据具体的机器人控制任务进行仔细设计,以确保强化学习过程能够收敛到期望的策略。
🖼️ 关键图片
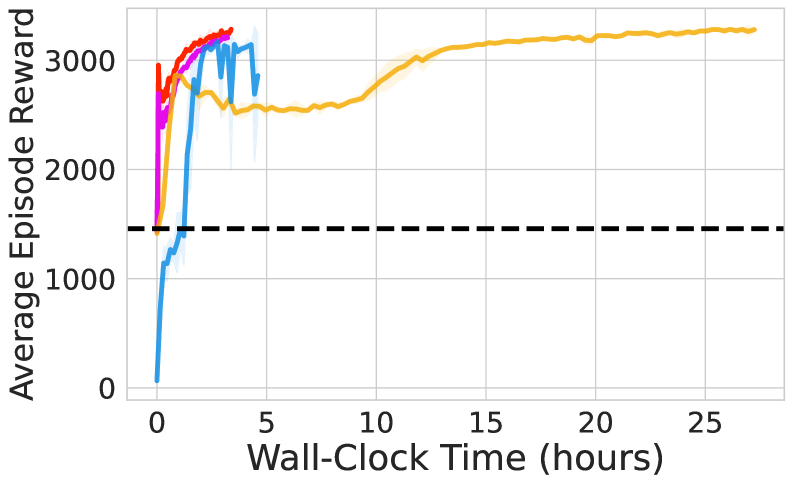

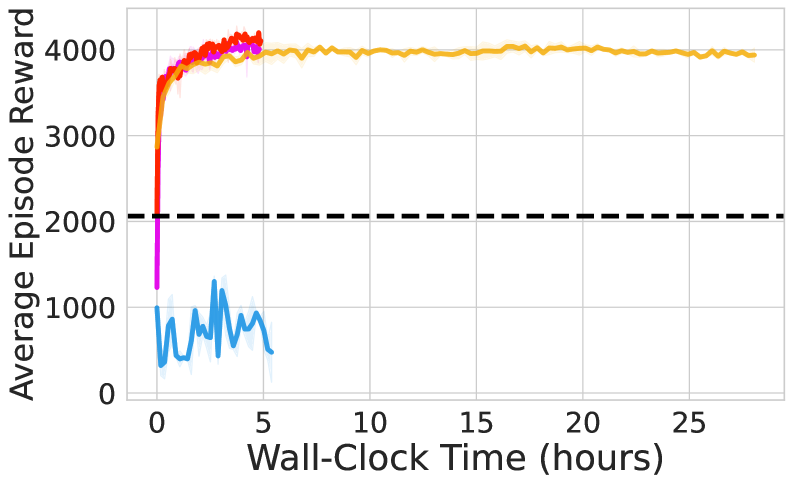
📊 实验亮点
ReinFlow在腿部运动任务中,Rectified Flow策略的episode奖励在微调后平均净增长135.36%,并节省了82.63%的运行时间,优于DPPO。在操作任务中,Shortcut Model策略在使用ReinFlow微调后,成功率平均净增长40.34%,性能与微调后的DDIM策略相当,同时节省了23.20%的计算时间。这些结果表明,ReinFlow能够有效地提高Flow Matching策略在机器人控制任务中的性能。
🎯 应用场景
ReinFlow具有广泛的应用前景,可应用于各种连续机器人控制任务,例如:无人驾驶、机器人操作、腿式机器人运动等。该方法能够提高机器人在复杂环境中的适应性和鲁棒性,并降低对人工设计的依赖。未来,ReinFlow可以与其他先进的强化学习技术相结合,进一步提高机器人控制的性能和智能化水平。
📄 摘要(原文)
We propose ReinFlow, a simple yet effective online reinforcement learning (RL) framework that fine-tunes a family of flow matching policies for continuous robotic control. Derived from rigorous RL theory, ReinFlow injects learnable noise into a flow policy's deterministic path, converting the flow into a discrete-time Markov Process for exact and straightforward likelihood computation. This conversion facilitates exploration and ensures training stability, enabling ReinFlow to fine-tune diverse flow model variants, including Rectified Flow [35] and Shortcut Models [19], particularly at very few or even one denoising step. We benchmark ReinFlow in representative locomotion and manipulation tasks, including long-horizon planning with visual input and sparse reward. The episode reward of Rectified Flow policies obtained an average net growth of 135.36% after fine-tuning in challenging legged locomotion tasks while saving denoising steps and 82.63% of wall time compared to state-of-the-art diffusion RL fine-tuning method DPPO [43]. The success rate of the Shortcut Model policies in state and visual manipulation tasks achieved an average net increase of 40.34% after fine-tuning with ReinFlow at four or even one denoising step, whose performance is comparable to fine-tuned DDIM policies while saving computation time for an average of 23.20%. Project webpage: https://reinflow.github.io/