Prior Reinforce: Mastering Agile Tasks with Limited Trials
作者: Yihang Hu, Pingyue Sheng, Yuyang Liu, Shengjie Wang, Yang Gao
分类: cs.RO
发布日期: 2025-05-28 (更新: 2025-09-27)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
Prior Reinforce:通过少量试验掌握敏捷任务的强化学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 敏捷任务 运动先验 具身机器人 动态系统
📋 核心要点
- 现有机器人方法在处理敏捷动态任务(如投篮)时,面临数据收集成本高、奖励设计困难和运动规划复杂等挑战。
- Prior Reinforce (P.R.) 模仿人类学习方式,先从少量演示学习运动先验,再通过少量真实试验迭代优化运动。
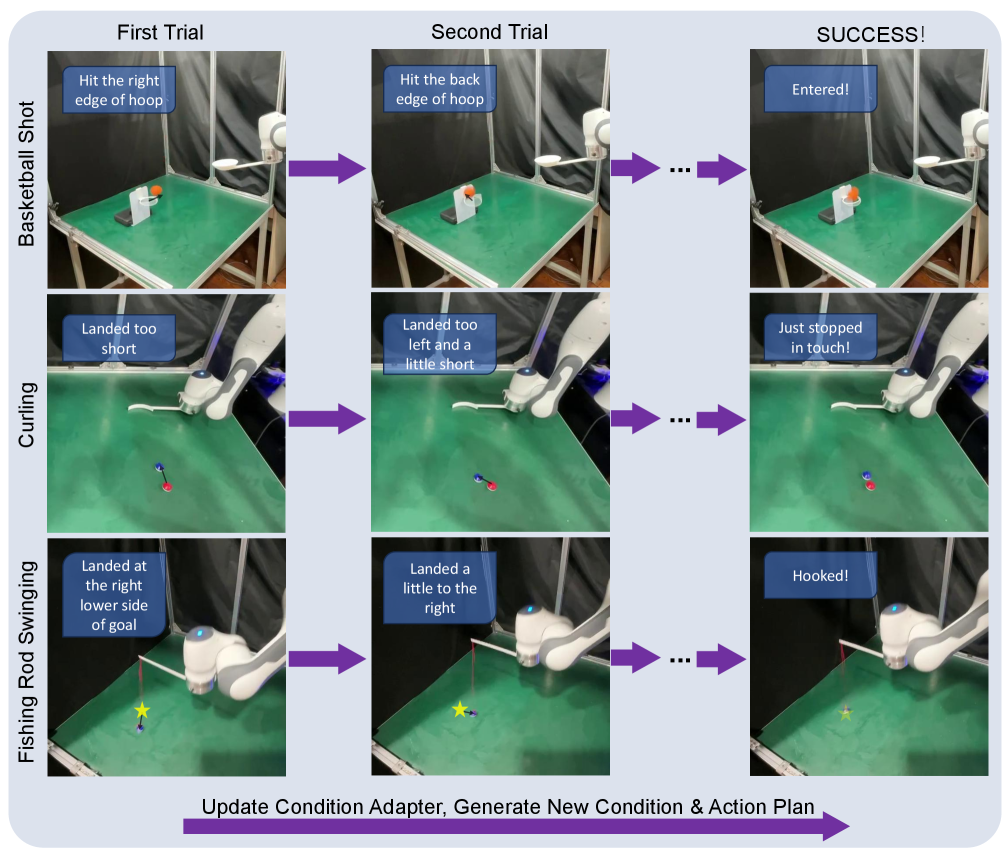
- 实验证明,P.R. 能够以人类水平的精度和效率,在真实世界中完成多种目标条件敏捷动态任务,例如在10次内学会投篮。
📝 摘要(中文)
如今,具身机器人已经能够处理许多现实世界的操控任务。然而,某些涉及动态过程的现实任务(例如,将篮球投进篮筐)非常敏捷,并且对结果的精度要求很高,这给主要为准静态操控设计的方法带来了额外的挑战。这导致了在昂贵的数据收集、费力的奖励设计或复杂的运动规划方面投入了更多的精力。然而,对于人类来说,这些任务的挑战性要小得多。例如,一个新手篮球运动员通常只需要大约10次尝试就能投进他们的第一个球,通过大致模仿一些运动先验,然后根据过去的結果迭代地调整他们的运动。受到这种人类学习范式的启发,我们提出Prior Reinforce(P.R.),这是一种简单且可扩展的方法,它首先从极少的演示中学习运动模式,然后基于少量真实世界试验的反馈迭代地改进其生成的运动,直到达到特定目标。实验表明,Prior Reinforce可以直接在现实世界中学习并完成各种具有人类水平精度和效率的目标条件敏捷动态任务,例如在少于10次试验中将篮球投进篮筐。
🔬 方法详解
问题定义:论文旨在解决具身机器人在敏捷动态任务中学习效率低下的问题,例如投篮。现有方法通常需要大量数据、复杂的奖励函数或精细的运动规划,这使得它们在实际应用中成本高昂且难以部署。人类通常可以通过少量尝试和迭代就能掌握这些任务,而现有机器人方法难以达到这种效率。
核心思路:论文的核心思路是模仿人类的学习方式,即首先学习一个粗略的运动先验,然后通过少量真实世界的试验进行迭代优化。这种方法利用了先验知识来指导探索,从而减少了对大量数据的需求,并提高了学习效率。
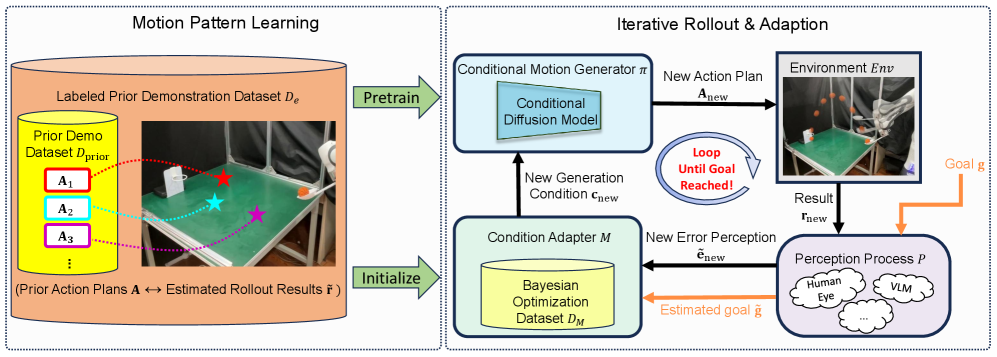
技术框架:Prior Reinforce (P.R.) 的整体框架包含两个主要阶段:1) 运动先验学习阶段:利用少量演示数据学习一个初始的运动模式。2) 强化学习优化阶段:通过与真实环境交互,根据试验结果迭代地调整运动模式,直到达到目标。该框架使用目标条件强化学习,允许机器人学习完成具有不同目标的任务。
关键创新:该方法最重要的创新点在于结合了运动先验学习和强化学习,从而实现了高效的敏捷动态任务学习。与传统的强化学习方法相比,P.R. 不需要从零开始学习,而是利用先验知识来加速学习过程。与模仿学习方法相比,P.R. 可以通过强化学习来进一步优化运动,从而提高精度和鲁棒性。
关键设计:P.R. 的关键设计包括:1) 使用少量演示数据学习运动先验。2) 设计合适的奖励函数,鼓励机器人达到目标。3) 使用合适的强化学习算法(例如,近端策略优化 PPO)来优化运动策略。4) 仔细调整强化学习算法的超参数,以确保学习的稳定性和效率。具体的网络结构和损失函数细节在论文中未明确给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Prior Reinforce 能够在少于10次试验中学会投篮,达到人类水平的精度和效率。与传统的强化学习方法相比,P.R. 显著减少了数据需求,并提高了学习速度。该方法还在其他敏捷动态任务中取得了良好的效果,证明了其通用性和可扩展性。具体的性能数据和对比基线在论文中未详细给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要敏捷性和精确性的机器人任务,例如体育运动(投篮、踢球)、物流分拣、医疗手术等。通过减少数据需求和提高学习效率,该方法有望降低机器人部署成本,并使其能够适应更复杂的现实世界环境。未来,该方法可以进一步扩展到更广泛的机器人应用领域,例如家庭服务、灾难救援等。
📄 摘要(原文)
Embodied robots nowadays can already handle many real-world manipulation tasks. However, certain other real-world tasks involving dynamic processes (e.g., shooting a basketball into a hoop) are highly agile and impose high precision requirements on the outcomes, presenting additional challenges for methods primarily designed for quasi-static manipulations. This leads to increased efforts in costly data collection, laborious reward design, or complex motion planning. Such tasks, however, are far less challenging for humans. Say a novice basketball player typically needs only about 10 attempts to make their first successful shot, by roughly imitating some motion priors and then iteratively adjusting their motion based on the past outcomes. Inspired by this human learning paradigm, we propose Prior Reinforce(P.R.), a simple and scalable approach which first learns a motion pattern from very few demonstrations, then iteratively refines its generated motions based on feedback of a few real-world trials, until reaching a specific goal. Experiments demonstrated that Prior Reinforce can learn and accomplish a wide range of goal-conditioned agile dynamic tasks with human-level precision and efficiency directly in real-world, such as throwing a basketball into the hoop in fewer than 10 trials. Project website:https://adap-robotics.github.io/.