Streaming Flow Policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories
作者: Sunshine Jiang, Xiaolin Fang, Nicholas Roy, Tomás Lozano-Pérez, Leslie Pack Kaelbling, Siddharth Ancha
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-05-28 (更新: 2025-09-24)
备注: Conference on Robot Learning (CoRL) 2025
💡 一句话要点
提出流式Flow策略,通过将动作轨迹视为流轨迹简化扩散/Flow匹配策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 流式控制 Flow匹配 模仿学习 机器人控制 动作轨迹生成
📋 核心要点
- 现有扩散/Flow匹配策略计算成本高昂,且需等待采样完成才能执行动作,限制了实时性。
- 提出流式Flow策略,将动作轨迹视为Flow轨迹,从窄高斯分布采样并积分速度场生成动作序列。
- 该方法支持动作流式传输,适用于后退水平线策略,并保留了建模多模态行为的能力,提升了模仿学习性能。
📝 摘要(中文)
扩散/Flow匹配策略在模仿学习复杂、多模态动作轨迹方面取得了进展。然而,由于它们对轨迹的轨迹进行采样(即动作轨迹的扩散/Flow轨迹),因此计算成本很高。它们丢弃中间动作轨迹,并且必须等待采样过程完成才能在机器人上执行任何动作。本文通过将动作轨迹视为Flow轨迹来简化扩散/Flow策略。算法不是从纯噪声开始,而是从最后一个动作周围的窄高斯分布中采样。然后,它增量地积分通过Flow匹配学习到的速度场,以产生构成单个轨迹的一系列动作。这使得在Flow采样过程中能够将动作流式传输到机器人,并且非常适合后退水平线策略执行。尽管是流式的,但该方法保留了建模多模态行为的能力。训练稳定在演示轨迹周围的Flow,以减少分布偏移并提高模仿学习性能。流式Flow策略优于先前的方法,同时实现了更快的策略执行和更紧密的传感器运动回路,用于基于学习的机器人控制。
🔬 方法详解
问题定义:现有基于扩散/Flow匹配的策略在模仿学习中,需要对动作轨迹的轨迹进行采样,计算量大,且必须等待整个采样过程完成才能执行动作,无法满足实时性要求,不适用于需要快速响应的机器人控制任务。此外,中间动作轨迹被丢弃,效率较低。
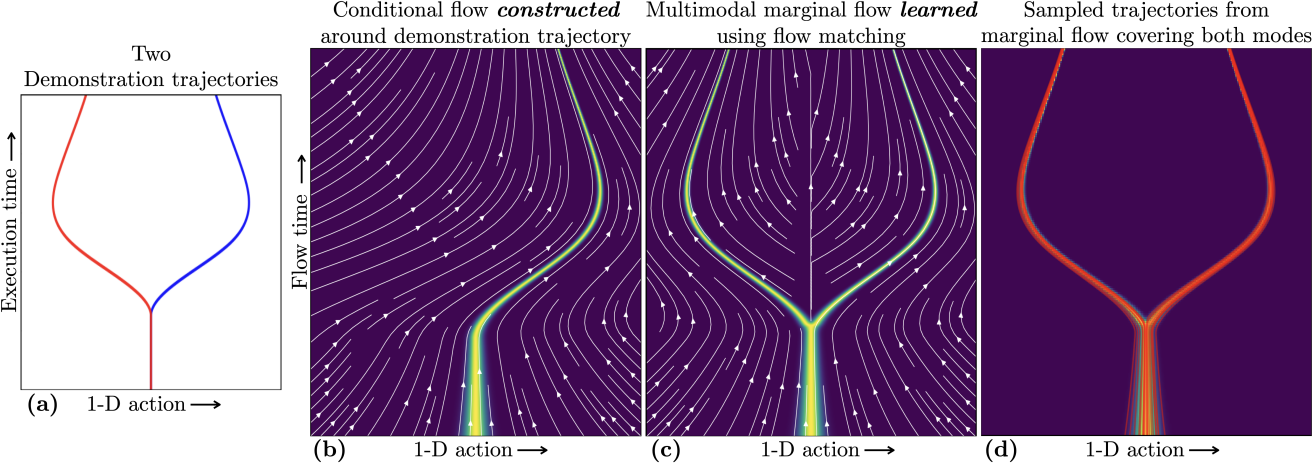
核心思路:论文的核心思路是将动作轨迹本身视为Flow轨迹,而不是生成轨迹的轨迹。通过从上一个动作附近采样,并利用Flow匹配学习到的速度场逐步积分,生成一个连续的动作序列。这样,动作可以边生成边执行,实现流式控制。
技术框架:该方法主要包含以下几个阶段:1) 从上一个动作附近采样:不再从纯噪声开始,而是从一个以最后一个动作为中心,方差较小的高斯分布中采样。2) Flow匹配:使用Flow匹配技术学习一个速度场,该速度场能够将采样点引导到期望的动作轨迹上。3) 轨迹积分:通过迭代地将速度场作用于当前动作,生成一个连续的动作序列。4) 流式执行:生成的动作可以立即发送给机器人执行,无需等待整个轨迹生成完成。
关键创新:最重要的创新点在于将动作轨迹视为Flow轨迹,实现了动作的流式生成和执行。这与传统的扩散/Flow匹配策略需要生成完整的轨迹后再执行有本质区别。此外,通过从上一个动作附近采样,并训练稳定在演示轨迹周围的Flow,可以减少分布偏移,提高模仿学习的性能。
关键设计:关键设计包括:1) 窄高斯分布的方差选择:需要根据具体任务调整,以保证探索性和稳定性。2) Flow匹配模型的网络结构:可以使用各种神经网络结构,如MLP、CNN等,具体选择取决于任务的复杂程度。3) 损失函数的设计:除了标准的Flow匹配损失外,还可以加入正则化项,以保证速度场的平滑性。4) 积分步长:需要根据任务的精度要求和计算资源进行权衡。
🖼️ 关键图片


📊 实验亮点
论文提出的流式Flow策略在模仿学习任务中表现优异,相较于传统方法,实现了更快的策略执行速度和更低的延迟。实验结果表明,该方法能够有效地减少分布偏移,提高模仿学习的性能,并且能够生成更平滑、更自然的机器人动作。
🎯 应用场景
该研究成果可应用于各种需要实时控制的机器人任务,如自动驾驶、无人机控制、机器人操作等。通过流式执行动作,可以实现更快的响应速度和更紧密的传感器运动回路,从而提高机器人的控制精度和鲁棒性。此外,该方法还可以用于生成更自然的机器人动作,提高人机交互的体验。
📄 摘要(原文)
Recent advances in diffusion$/$flow-matching policies have enabled imitation learning of complex, multi-modal action trajectories. However, they are computationally expensive because they sample a trajectory of trajectories: a diffusion$/$flow trajectory of action trajectories. They discard intermediate action trajectories, and must wait for the sampling process to complete before any actions can be executed on the robot. We simplify diffusion$/$flow policies by treating action trajectories as flow trajectories. Instead of starting from pure noise, our algorithm samples from a narrow Gaussian around the last action. Then, it incrementally integrates a velocity field learned via flow matching to produce a sequence of actions that constitute a single trajectory. This enables actions to be streamed to the robot on-the-fly during the flow sampling process, and is well-suited for receding horizon policy execution. Despite streaming, our method retains the ability to model multi-modal behavior. We train flows that stabilize around demonstration trajectories to reduce distribution shift and improve imitation learning performance. Streaming flow policy outperforms prior methods while enabling faster policy execution and tighter sensorimotor loops for learning-based robot control. Project website: https://streaming-flow-policy.github.io/